一、为什么需要 MindCluster:NPU 集群不是“多装几个驱动”
在单机单卡时代,AI 基础设施的复杂度通常集中在驱动、框架和模型代码上;到了多机多卡训练与服务化推理阶段,真正棘手的问题会变成:
- Kubernetes 如何识别并分配昇腾 NPU?
- 调度器是否知道 NPU 之间的 HCCS、PCIe、交换机和超节点拓扑?
- 作业启动时,谁来生成 HCCL/RankTable 等集合通信配置?
- 芯片、节点、网络或容器故障发生后,谁来判定影响范围并触发恢复?
- 运维侧如何收集指标、定位根因、做性能验收和软件包安全校验?
MindCluster 的价值就在于把这些能力从“平台开发者自己拼装”变成一套面向昇腾训练和推理集群的软件栈。 官方 7.1.RC1 文档将 MindCluster 能力划分为安装部署、性能测试、集群调度、故障诊断、日志收集、安全校验和参考信息等方向;本地 mind-cluster 代码库则进一步展示了这些能力在源码层如何拆分成多个组件。
说明:本文以本地
mind-cluster开源代码库为实现视角,并结合昇腾社区 MindCluster 7.1.RC1 文档导读和关键页面做架构解读。具体部署参数和兼容性以实际版本的官方文档为准。
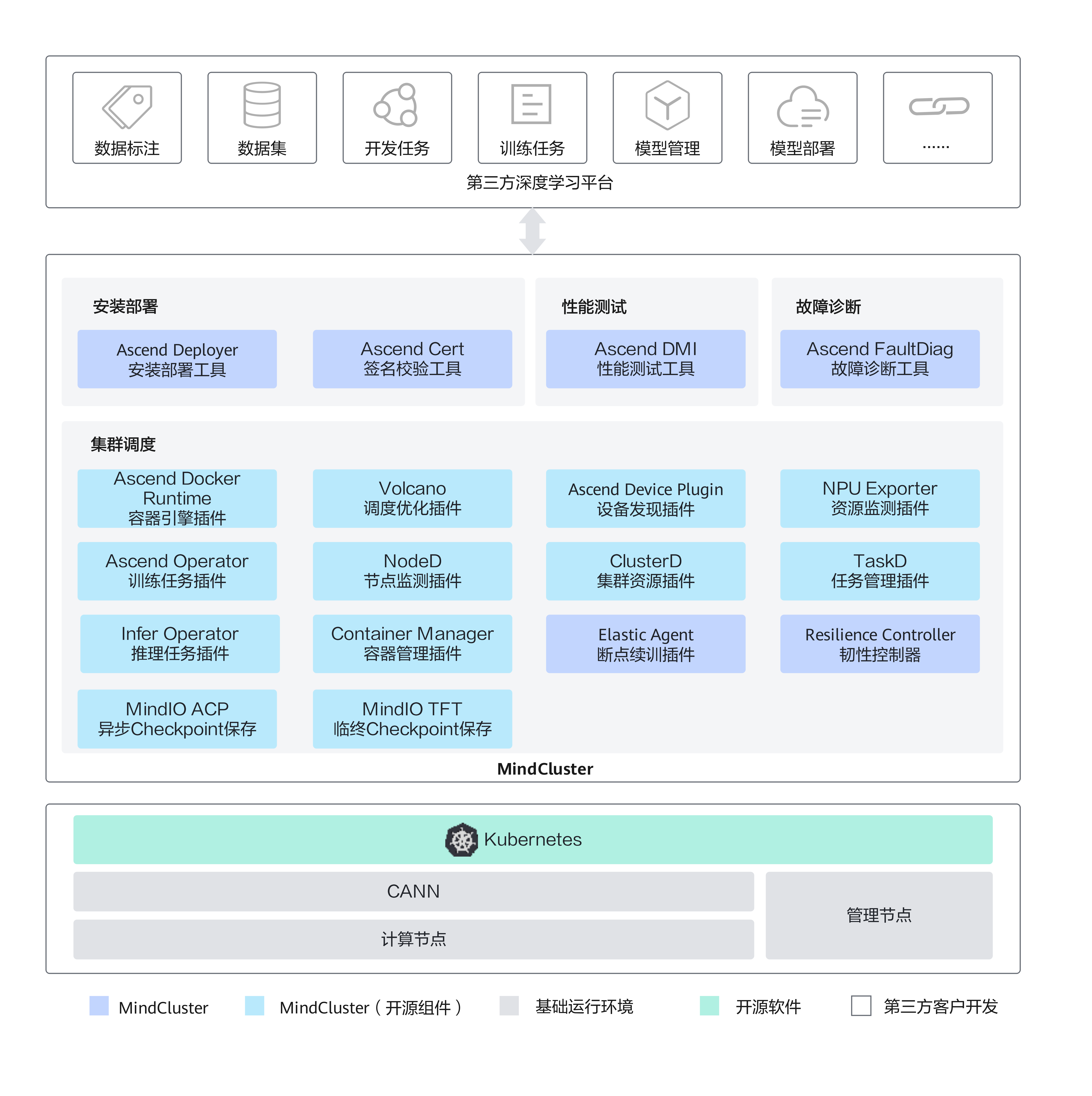
如果用一句话概括:MindCluster 是围绕昇腾 NPU 构建的 AI 集群控制面,它把底层设备、Kubernetes 调度、分布式训练通信、故障恢复和运维诊断连接成闭环。

二、从代码库看组件版图
本地仓库的顶层结构比较清晰:
mind-cluster/
├── build/ # 全组件统一构建脚本与版本配置
├── component/ # 核心组件源码
├── docker/ # 官方镜像 Dockerfile 与镜像说明
├── docs/ # 中文用户文档、RFC、架构图和 API 参考
└── tests/ # 系统测试和冒烟用例
真正的主体在 component/ 下。可以按职责把组件分成五类:
| 类别 | 组件 | 主要职责 |
|---|---|---|
| 公共基础 | ascend-common |
公共 API、日志、文件校验、DCMI/HCCN 设备管理封装 |
| 容器与资源接入 | ascend-docker-runtime、ascend-device-plugin |
容器内挂载 NPU 与驱动依赖;向 Kubernetes 上报 NPU 资源、健康状态与设备分配结果 |
| 集群调度控制面 | ascend-for-volcano、ascend-operator、clusterd、infer-operator |
NPU/网络拓扑感知调度、训练任务生命周期、集群资源/故障汇总、推理服务管理 |
| 观测与诊断 | npu-exporter、noded、ascend-faultdiag、ascend-faultdiag-online |
NPU 指标采集、节点故障检测、离线/在线故障诊断 |
| 容错与恢复 | taskd、mindio/acp、mindio/tft、container-manager |
任务状态管理、Checkpoint 加速、TTP/UCE/ARF 训练容错、一体机容器恢复 |
这套拆分非常符合“控制面 + 节点代理 + 任务侧 SDK”的云原生思路:
- 管理节点运行调度器、Operator、ClusterD 等全局控制面;
- 计算节点运行 Device Plugin、NodeD、NPU Exporter、Ascend Docker Runtime 等节点代理;
- 任务容器内通过环境变量、RankTable、TaskD、MindIO 等能力完成训练/推理运行时协同。
三、安装部署层:先把昇腾软件栈交付成“可重复环境”
官方文档中的 Ascend Deployer 是安装部署入口。它面向昇腾训练和推理环境,支持 OS 依赖、Docker、驱动、固件、CANN、MindCluster 组件、AI 框架和 MindIE 镜像的在线/离线下载、安装和升级,并支持单机与批量部署。
本地仓库则提供了源码构建链路。build/build_all.sh 会把各组件复制到 GOPATH,准备 Volcano 开源代码和 ascend-docker-runtime 构建依赖,然后逐个构建:
mind_cluster=(
"ascend-device-plugin"
"ascend-docker-runtime"
"ascend-for-volcano"
"ascend-operator"
"ascend-faultdiag"
"clusterd"
"container-manager"
"infer-operator"
"mindio"
"noded"
"npu-exporter"
"taskd"
)
for component in "${mind_cluster[@]}"; do
./build_each.sh $GOPATH service_config.ini $component
done
对平台工程师来说,部署层的重点不是“能不能把二进制编出来”,而是要保证:
- 固件、驱动、CANN 与 MindCluster 组件版本匹配;
- Kubernetes、Docker/containerd、Volcano 版本匹配;
- 管理节点和计算节点组件安装角色清晰;
- 软件包在交付前经过签名与 CRL 校验。
官方 ToolBox 中的 Ascend Cert 正是用于软件包数字签名校验和 CRL 证书吊销列表比较更新;Ascend DMI 则面向 Atlas 标卡、板卡和模组类产品,提供带宽、算力、功耗等测试能力,可用于上线前验收和性能基线建立。
四、资源接入层:让 Kubernetes “看见” NPU
Kubernetes 原生只理解 CPU、内存、普通设备插件上报的扩展资源。昇腾 NPU 要进入调度体系,至少要经过三步:
- 节点侧发现 NPU 设备和健康状态;
- 将 NPU 注册成 Kubernetes 扩展资源;
- 在容器启动时挂载真实设备、驱动和运行库。
4.1 Ascend Device Plugin:设备发现、健康检查与分配
component/ascend-device-plugin/main.go 是 Device Plugin 的启动入口。它解析 volcanoType、listWatchPeriod、hotReset、presetVirtualDevice、shareDevCount、enableSlowNode 等参数,初始化设备管理器后开始监听设备与 DPU 状态:
hdm, err := devicefactory.InitFunction()
if err != nil {
return
}
hdm.DoSetMultiDiePolicyForA3()
setUseAscendDocker()
go hdm.ListenDevice(ctx)
go hdm.ListenDpu(ctx)
go topology.RasTopoWriteTask(ctx, hdm)
duplicatedetector.CheckDuplicateDevices(ctx, &types.DetectorConfig{
CriEndpoint: "",
RuntimeType: hdm.ContainerRuntime,
})
它承担的关键职责包括:
- 从驱动/DCMI 获取设备类型、数量和健康状态;
- 将 NPU 资源上报给 kubelet;
- 将芯片状态、故障信息、拓扑信息上报给 ClusterD 或调度器;
- 在资源挂载阶段,把调度器选中的芯片编号写入 Pod 注解/环境变量;
- 支持 vNPU、软切分、热复位、故障升级等高级能力。
4.2 Ascend Docker Runtime:容器运行时适配
component/ascend-docker-runtime 基于 OCI hook 思路工作。官方 README 中说明,它不修改 Docker 引擎,而是在 runc 启动容器的 prestart-hook 阶段完成:
- 根据
ASCEND_VISIBLE_DEVICES挂载指定 NPU 设备; - 配置 device cgroup,限制容器只能访问指定设备;
- 挂载 Host 上的 CANN Runtime Library。
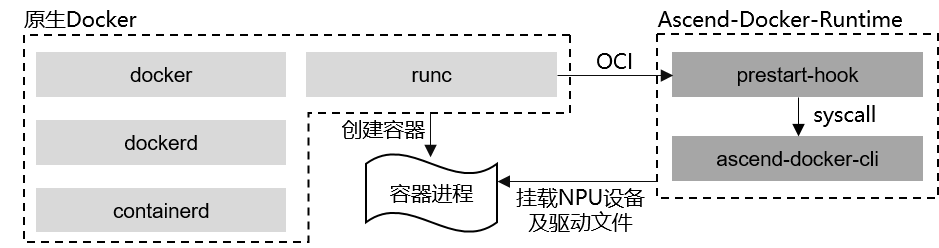
从云原生角度看,Device Plugin 负责“资源分配”,Docker Runtime 负责“运行时兑现”。前者告诉 Kubernetes 这个 Pod 应该拿哪张卡,后者把对应设备真正放进容器 namespace。
五、调度控制面:NPU 亲和性不是简单的数量匹配
MindCluster 调度能力的核心在 component/ascend-for-volcano。官方文档说明,集群调度组件基于 Kubernetes,增加了昇腾 NPU 的资源管理、优化调度和分布式训练集合通信配置能力;本地代码则显示其通过 Volcano 插件机制实现 NPU 亲和性调度、交换机亲和性调度、多级调度和故障重调度。
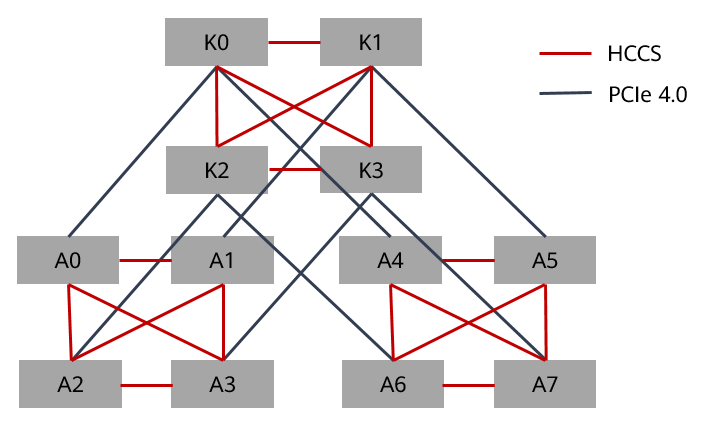
以 Ascend 910 为例,单节点 8 颗处理器之间并不是“任意几张卡都等价”。ascend-for-volcano/README.md 中说明:每台物理设备具备 8 颗处理器、两个 HCCS;同一 HCCS 内可通信,不同 HCCS 内不能直接通信。因此,一个 Pod 申请 1/2/4/8 张 NPU 时,调度器需要考虑:
- 小于等于 4 张时尽量放入同一个 HCCS;
- 优先占满已有分配,减少资源碎片;
- 剩余资源尽量保持偶数,便于后续任务继续成组分配。
5.1 Volcano 插件如何接入调度周期
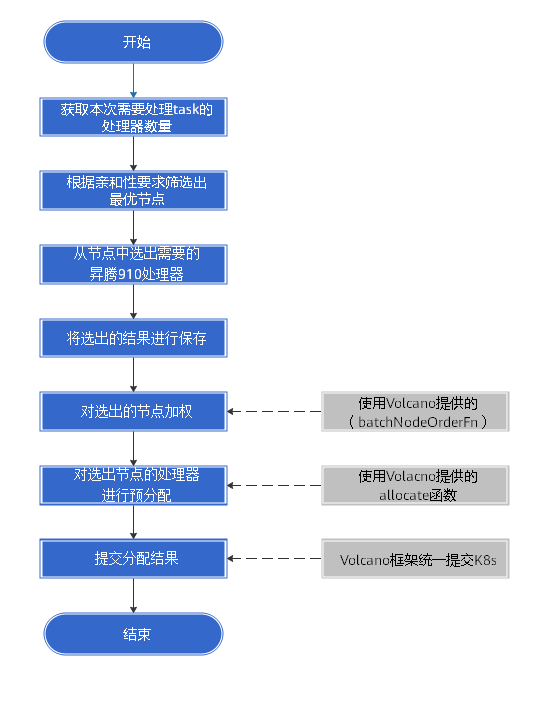
component/ascend-for-volcano/npu.go 是插件入口。OnSessionOpen 中注册了多个 Volcano 回调:
func (tp *huaweiNPUPlugin) OnSessionOpen(ssn *framework.Session) {
if err := tp.Scheduler.InitNPUSession(ssn); err != nil {
return
}
ssn.AddJobValidFn(tp.Name(), func(obj interface{}) *api.ValidateResult {
return tp.Scheduler.JobValid(obj)
})
addPredicateFn(ssn, tp)
addBatchNodeOrderFn(ssn, tp)
ssn.AddJobReadyFn(tp.Name(), func(obj interface{}) bool {
return jobReady(obj, tp)
})
ssn.AddJobEnqueueableFn(tp.Name(), func(job interface{}) int {
return jobEnqueueable(job, ssn, tp)
})
addEventHandler(ssn, tp)
}
这段代码可以拆成五个阶段理解:
| 阶段 | Volcano 回调 | MindCluster 做什么 |
|---|---|---|
| 作业校验 | AddJobValidFn |
校验 NPU 请求、调度策略、Gang 调度等作业级约束 |
| 节点过滤 | AddPredicateFn |
排除数量够但拓扑不满足的节点 |
| 节点打分 | AddBatchNodeOrderFn |
根据 HCCS、交换机、多级拓扑等策略选择最优节点和芯片 |
| 资源落盘 | AddEventHandler |
在 Allocate/Deallocate 时维护节点芯片占用,避免并发重复分配 |
| 作业状态 | AddJobReadyFn、AddJobEnqueueableFn |
控制作业是否可入队、是否达到最小可用副本 |

5.2 策略工厂:从 schedule-policy 到具体调度器
component/ascend-for-volcano/internal/npu/factory.go 是策略分发中心。它根据作业的 NPU 类型、节点标签、accelerator-type 和调度策略注解,选择不同的处理器:
var policy910HandlerMap = map[string]string{
util.Chip8Node8: module910bx8Name,
util.Chip8Node16: module910bx16.SchedulerName,
util.Chip2Node16Sp: superpod.A3x16SchedulerName,
util.Chip8Node8Sp: chip8node8sp.SchedulePolicy8Px8Sp,
util.Chip8Node8Ra64Sp: chip8node8ra64sp.SchedulePolicy8Px8Ra64Sp,
util.MultiLevel: multilevelscheduling.MultiLevelHandlerName,
}
这种设计有两个好处:
- 硬件形态解耦:310、310P、910、910B、910A3、超节点、vNPU 等策略可分别实现;
- 调度策略可扩展:新增多级网络亲和性、软切分或超节点策略时,不必重写 Volcano 插件主流程。
internal/controller.go 进一步把 NPU 策略和 NSLB(网络/交换机亲和性)策略组合起来:
func (c *Controller) SetPolicyHandler(attr util.SchedulerJobAttr, env plugin.ScheduleEnv) {
if handler, ok := npu.InitPolicyHandler(attr, env); ok {
c.PolicyHandler = append(c.PolicyHandler, handler)
}
if handler, ok := nslb.InitPolicyHandler(attr, env); ok {
c.PolicyHandler = append(c.PolicyHandler, handler)
}
}
因此,一次调度决策既可以考虑 NPU 芯片内部拓扑,也可以考虑节点间交换机拓扑和多级网络结构。
六、ClusterD:集群故障与资源信息的“汇聚层”
如果 Device Plugin 是每个节点的“设备眼睛”,ClusterD 就是管理节点上的“集群大脑”。官方文档和 docker/clusterd/OVERVIEW.zh.md 都强调:ClusterD 收集集群任务、资源、故障信息及影响范围,从任务、芯片和故障维度统计分析,统一判定故障处理级别和策略。
component/clusterd/main.go 展示了它启动后的几类工作:
- 初始化 Kubernetes 客户端与 informers;
- 注册 Pod、PodGroup、VCJob、ACJob、ConfigMap、节点、公共故障等处理函数;
- 启动 gRPC Server,向上层和任务侧提供资源/故障/恢复接口;
- 启动故障处理中心、任务统计、调度异常检查、公共故障处理。
关键初始化逻辑可以概括为:
func startInformer(ctx context.Context) {
addResourceFunc()
addJobFunc()
addEpRankTableFunc()
kube.InitCMInformer()
kube.InitPubFaultCMInformer()
kube.InitPodAndNodeInformer()
kube.InitPodGroupInformer()
go kube.InitACJobInformer()
go kube.InitVCJobInformer()
go jobv2.Handler(ctx)
go jobv2.Checker(ctx)
go resource.Report(ctx)
}
ClusterD 的价值在故障场景中最明显:单个节点只知道“我这里有芯片故障或节点故障”,但分布式训练需要知道“这个故障影响哪些 rank、哪些 Pod、是否需要单 Pod 重调度、整作业重调度、进程级恢复还是仅隔离故障资源”。这类全局判断必须由集群侧组件完成。
七、Ascend Operator:把训练任务变成可运行的分布式作业
component/ascend-operator 负责训练任务生命周期管理。README 中说明它支持 MindSpore、PyTorch、TensorFlow 等框架在 Kubernetes 上进行分布式训练,通过 AscendJob CRD 定义任务。
main.go 中注册了 Kubernetes、Volcano、MindCluster CRD scheme,并启动 Reconciler:
mgr, err := ctrl.NewManager(initKubeConfig(), ctrl.Options{
Scheme: runtimeScheme,
MetricsBindAddress: "0",
})
if err = v1.NewReconciler(mgr, enableGangScheduling).SetupWithManager(mgr); err != nil {
return
}
mgr.Start(ctrl.SetupSignalHandler())
一个简化的 AscendJob 训练样例如下,来自本地 tests/st/testcases/basic_schedule/training_910b/resources_0001/job_llama-1x8.yaml 的核心字段:
apiVersion: mindxdl.gitee.com/v1
kind: AscendJob
metadata:
name: default-test-1x8
namespace: trjob
labels:
framework: pytorch
fault-scheduling: "force"
pod-rescheduling: "on"
spec:
schedulerName: volcano
runPolicy:
schedulingPolicy:
minAvailable: 1
queue: default
replicaSpecs:
Master:
replicas: 1
template:
spec:
hostNetwork: true
containers:
- name: ascend
image: ubuntu:22.04
env:
- name: ASCEND_VISIBLE_DEVICES
valueFrom:
fieldRef:
fieldPath: metadata.annotations['huawei.com/Ascend910']
resources:
limits:
huawei.com/Ascend910: 8
requests:
huawei.com/Ascend910: 8
这里有几个关键点:
schedulerName: volcano让任务进入 Volcano 调度器;huawei.com/Ascend910: 8表示请求 8 张 Ascend 910 NPU;ASCEND_VISIBLE_DEVICES从 Pod annotation 中取值,这正是调度器和 Device Plugin 传递芯片选择结果的关键通道;fault-scheduling、pod-rescheduling、fault-retry-times等标签参与故障重调度策略。
换句话说,Ascend Operator 负责把“训练任务”转化为 Kubernetes 资源对象,并注入集合通信所需的环境变量和 RankTable;Volcano 插件负责把这些 Pod 放到最合适的 NPU 上;Device Plugin 和 Runtime 负责最终挂载设备。
八、资源监测:NPU Exporter 与 NodeD
8.1 NPU Exporter:把设备指标暴露给 Prometheus/Telegraf
官方文档将 NPU Exporter 定位为实时监测昇腾 AI 处理器资源指标的组件。本地 component/npu-exporter/cmd/npu-exporter/main.go 显示,它启动后会:
- 初始化 DCMI 设备管理器;
- 初始化容器运行时解析器,从 CRI 获取容器与设备关系;
- 创建 NPU 指标采集器;
- 注册插件指标;
- 根据
platform参数以 Prometheus 或 Telegraf 方式输出。
dmgr, err := devmanager.AutoInit("", deviceResetTimeout)
deviceParser := container.MakeDevicesParser(readCntMonitoringFlags())
colcommon.Collector = colcommon.NewNpuCollector(
cacheTime,
time.Duration(updateTime)*time.Second,
deviceParser,
dmgr,
)
plugins.RegisterPlugin()
config.Register(colcommon.Collector)
colcommon.StartCollect(wg, ctx, colcommon.Collector)
component/npu-exporter/plugins/README.md 还提供了自定义插件机制。用户实现 MetricCollector 的 Describe、CollectToCache、UpdatePrometheus、UpdateTelegraf 等接口后,就可以把自定义 NPU 指标接入采集链路。
8.2 NodeD:节点健康状态与慢节点检测
NodeD 负责节点状态上报。README 中说明它从 IPMI 获取 CPU、内存、硬盘故障信息并上报给 ClusterD。main.go 还显示它会启动监控、ConfigMap watcher、PingMesh,并集成在线故障诊断:
go monitorManager.Run(ctx)
go configmap.GetCmWatcher().Watch(ctx.Done())
if pingmeshManager != nil {
go pingmeshManager.Run(ctx)
}
fdol.StartFDOnline(fdConfigPath, []string{"slowNode"}, "node")
这使 NodeD 不只是“节点心跳”,还承担了网络探测、慢节点识别和故障信息回流的职责。
九、故障诊断与恢复:从日志证据到自动重调度
MindCluster 的故障能力可以分成两条链路:
- 在线故障处理链路:Device Plugin / NodeD / ClusterD / Volcano / TaskD 共同完成故障感知和恢复;
- 离线诊断链路:FaultDiag 对日志和指标做清洗、汇总、根因分析与报告输出。
9.1 在线重调度:Rescheduler 如何接入 Volcano
component/ascend-for-volcano/internal/rescheduling/frame.go 中,ReScheduler.Execute 会在调度 session 中同步故障缓存、故障节点、故障作业和剩余重试次数,然后决定是否重启或重调度作业:
func (reScheduler *ReScheduler) Execute(env *plugin.ScheduleEnv, ssn *framework.Session) error {
reScheduler.initialize(env)
reScheduler.AddFaultNodeWithSession()
reScheduler.synCacheFaultJobWithSession(ssn)
reScheduler.SyncJobRemainRetryTimes(ssn)
reScheduler.SyncJobRecentRescheduleReason(ssn)
reScheduler.RestartNeedForceDeleteJobs(ssn, *env)
runningJobs := reScheduler.GetRunningJobs(ssn)
reScheduler.AddFaultJobWithSession(runningJobs, *env)
return reScheduler.RestartFaultJobs(ssn, *env)
}
这说明 MindCluster 的重调度并非简单删除 Pod,而是维护了故障节点、故障作业、重试次数、近期重调度原因、故障 rank 等状态。对于长时间运行的大模型训练来说,这些状态是避免“盲目重启”和“重复震荡”的基础。
9.2 FaultDiag:日志清洗、根因节点和故障事件分析
官方 FaultDiag 文档强调,该工具会读取并处理用户采集的原日志和监测指标文件,用户需要确保输入目录不包含敏感信息和个人数据。本地 component/ascend-faultdiag 代码展示了更完整的实现:
src/ascend_fd/cli.py:提供parse、diag、single-diag、entity、blacklist、config等命令;controller/controller.py:ParseController和DiagController分别负责日志清洗和诊断任务编排;pkg/parse/knowledge_graph/parser/:CANN、MindIE、MindIO、Device Plugin、NodeD、Volcano、训练日志等解析器;pkg/diag/knowledge_graph/、root_cluster/、network_congestion/、node_anomaly/:故障事件、根因节点、网络拥塞和节点异常诊断。

基础使用流程可以简化为:
# 1. 日志清洗:从原始日志中提取有效信息
ascend-fd parse -i /data/raw_logs -o /data/parsed_logs
# 2. 多节点清洗结果汇总后做故障诊断
ascend-fd diag -i /data/cluster_parsed_logs -o /data/diag_result
# 3. 如需性能劣化诊断,启用 performance 模式
ascend-fd diag -i /data/cluster_parsed_logs -o /data/diag_result -p
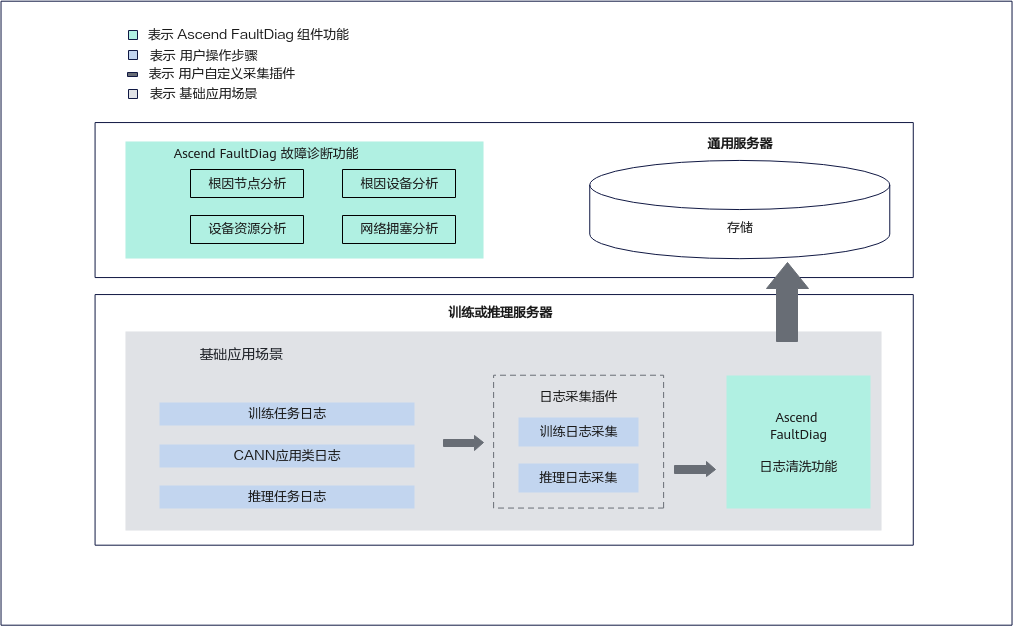
9.3 FaultDiag Toolkit:轻量链路诊断
component/ascend-faultdiag/toolkit_src 是链路故障诊断工具。README 明确说明它提供从 PC 或单台服务器远程访问集群设备采集数据诊断的能力,支持交互式和非交互式模式。
典型场景包括:
在线故障诊断:
1. 准备 conn.ini
2. set_conn_config conn.ini
3. auto_collect_diag
4. 查看诊断报告
离线日志分析:
1. 设置 host / bmc / switch 日志目录
2. auto_collect_diag
3. 查看诊断报告
跨网络平面采集:
1. 多个网络平面分别 auto_collect
2. 汇总后 auto_diag
其 CLI 入口在 ascend_fd_tk/cli.py,命令模型在 core/cli_module/cli_model.py;examples/auto_diag/auto_collect.py 展示了并发采集 Host、BMC、交换机、L1 HCCS 信息的编排方式。
十、训练容错:TaskD、MindIO ACP 与 MindIO TFT
对于大模型训练,最昂贵的不是单次失败,而是失败后的恢复时间和已消耗算力损失。MindCluster 在这部分提供了三类能力。
10.1 TaskD:任务状态管理与任务侧控制
component/taskd 是一个 Python + Go/cgo 组合组件。README 中说明它负责训练和推理任务的状态管理,包括进程生命周期管理和状态采集。
源码中可以看到两条线:
- Python 侧:
taskd/python/framework/manager/controller.py、worker/worker.py面向训练框架暴露 manager/worker 能力; - Go 侧:
taskd/go/backend_api.go通过//export暴露 C ABI,例如InitWorker、RegisterSwitchCallback、RegisterStressTestCallback。
它与 MindIO TFT 结合后,可以把训练进程状态、故障 rank、恢复策略等信息传给任务侧。
10.2 MindIO ACP:Checkpoint 保存/加载加速
component/mindio/acp/README.md 将 ACP 定位为 Async CheckPoint Persistence:Checkpoint 数据先写入训练服务器内存系统,再异步写入后端可靠存储,从而降低训练主流程等待 I/O 的时间。
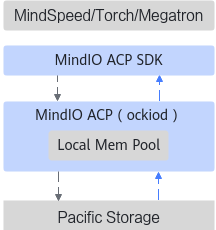
它的核心适用场景是大模型训练中的 Checkpoint 保存和加载加速,构建产物以 Python wheel 形式提供:
cd mind-cluster/component/mindio/acp/build
bash build.sh
pip3 install mindio_acp-${version}-py3-none-linux_${arch}.whl --force-reinstall
10.3 MindIO TFT:TTP、UCE、ARF 训练容错
component/mindio/tft/README.md 对 TFT 的定位更偏运行时容错。它包括:
- TTP(Try To Persist):故障发生后生成临终 Checkpoint,减少迭代损失;
- UCE:片上内存不可纠错错误的 Step 级重计算和在线修复;
- ARF(Air Refuelling):异常故障时以节点或进程为单位快速恢复,而非停止整个集群;
- 网络故障快速恢复、亚健康热切、在线压测/借轨回切等能力。
源码层看,TaskD 会调用 mindio_ttp.controller_ttp 中的 tft_init_controller、tft_start_controller、tft_notify_controller_dump、tft_notify_controller_change_strategy 等接口,将控制面的恢复决策和训练框架侧的恢复动作连接起来。
十一、推理服务与一体机场景
除了训练任务,MindCluster 也覆盖推理服务和一体机场景。
11.1 Infer Operator
component/infer-operator 是 Kubernetes Operator,README 中说明它定义了 InferServiceSet、InferService、InstanceSet 三类 CRD,用于部署和管理多角色协作的推理任务。main.go 中启动多个 Reconciler,面向 Deployment、StatefulSet、Service、PodGroup 等资源做生命周期管理。
这类能力适合 vLLM、SGLang、MindIE Motor 等推理服务场景:平台侧提交一个推理服务声明,Operator 负责把多角色实例、服务发现、扩缩容和故障恢复落到 Kubernetes 资源上。
11.2 Container Manager
component/container-manager 面向无 Kubernetes 的一体机场景。README 中说明它支持故障管理、故障芯片和故障容器自动恢复,提供 run 与 status 两个命令:
./container-manager run -ctrStrategy=<ctrStrategy> -sockPath=<sockPath>
./container-manager status
这说明 MindCluster 并不只服务标准 K8s 集群,也给边缘、一体机、弱控制面环境预留了轻量恢复路径。
十二、实践路线:如何把这些组件串起来
如果要在一套昇腾训练集群上落地 MindCluster,可以按以下路径推进。
12.1 准备环境与基础软件
# 查询 Kubernetes 节点
kubectl get node
# 给计算节点打标签,供调度器识别硬件形态
kubectl label nodes worker01 node-role.kubernetes.io/worker=worker --overwrite
kubectl label nodes worker01 workerselector=dls-worker-node --overwrite
kubectl label nodes worker01 host-arch=huawei-arm --overwrite
kubectl label nodes worker01 accelerator=huawei-Ascend910 --overwrite
kubectl label nodes worker01 accelerator-type=module-910b-8 --overwrite
kubectl label nodes worker01 nodeDEnable=on --overwrite
# 创建 MindCluster 命名空间
kubectl create ns mindx-dl
12.2 安装节点侧组件
计算节点通常需要:
Ascend Docker Runtime:容器内挂载 NPU 与 CANN 依赖;Ascend Device Plugin:NPU 发现、健康检查与分配;NodeD:节点故障检测;NPU Exporter:NPU 指标暴露。
管理节点通常需要:
Volcano + Ascend for Volcano;ClusterD;Ascend Operator;- 按需安装
Infer Operator、FaultDiag 或 ToolBox 工具。
12.3 提交训练任务
提交作业时重点检查三类字段:
spec:
schedulerName: volcano
runPolicy:
schedulingPolicy:
minAvailable: 1
queue: default
replicaSpecs:
Master:
template:
spec:
containers:
- name: ascend
env:
- name: ASCEND_VISIBLE_DEVICES
valueFrom:
fieldRef:
fieldPath: metadata.annotations['huawei.com/Ascend910']
resources:
limits:
huawei.com/Ascend910: 8
requests:
huawei.com/Ascend910: 8
schedulerName决定是否进入 Volcano;resources决定申请多少 NPU;ASCEND_VISIBLE_DEVICES决定容器内使用哪些调度器选中的芯片。
12.4 观测与诊断
# Prometheus 模式采集 NPU 指标,常见暴露端口为 npu-exporter 启动参数配置
kubectl -n mindx-dl get pods -o wide
kubectl -n mindx-dl logs <npu-exporter-pod>
# 作业失败后,收集日志并使用 FaultDiag 分析
ascend-fd parse -i /data/raw_logs -o /data/parsed_logs
ascend-fd diag -i /data/cluster_parsed_logs -o /data/diag_result
如果是链路类问题,还可以用 FaultDiag Toolkit:
set_conn_config conn.ini
auto_collect_diag
十三、源码阅读建议:按控制闭环而不是按目录读
mind-cluster 代码量较大,建议按“控制闭环”阅读:
| 阅读目标 | 推荐入口 |
|---|---|
| 全局组件与文档 | README.md、docs/zh/overview.md |
| 集群调度概念 | docs/zh/scheduling/introduction.md |
| Device Plugin 启动 | component/ascend-device-plugin/main.go |
| Volcano 插件入口 | component/ascend-for-volcano/npu.go |
| 调度策略接口 | component/ascend-for-volcano/plugin/plugin.go |
| NPU 策略工厂 | component/ascend-for-volcano/internal/npu/factory.go |
| 多级网络亲和性 | component/ascend-for-volcano/internal/npu/policy/multilevelscheduling/、docs/rfc/26.0.0/features-multilevel-scheduling-npu-affinity.md |
| 故障重调度 | component/ascend-for-volcano/internal/rescheduling/ |
| ClusterD | component/clusterd/main.go、component/clusterd/pkg/ |
| Ascend Operator | component/ascend-operator/main.go、pkg/controllers/、pkg/ranktable/ |
| NPU Exporter | component/npu-exporter/cmd/npu-exporter/main.go、collector/metrics/ |
| FaultDiag | component/ascend-faultdiag/src/ascend_fd/cli.py、controller/、pkg/parse/、pkg/diag/ |
| TaskD / MindIO | component/taskd/、component/mindio/acp/、component/mindio/tft/ |
阅读时可以围绕一个问题往下追:一次 AscendJob 从提交到运行、故障、恢复,分别经过哪些组件? 这比单独读某个目录更容易建立系统图景。
十四、安全与工程化注意点
本地 README 和官方文档多处提到安全与合规注意事项,实践中尤其要关注:
-
ServiceAccount Token 与特权容器风险
多个组件以容器方式部署,部分组件需要较高权限访问设备、主机日志或容器运行时。生产环境需要结合集群安全策略做加固。 -
日志与诊断数据敏感信息
FaultDiag 会处理用户采集的原始日志和监测指标。官方文档明确提醒用户确保输入目录中不包含敏感信息和个人数据。 -
软件包可信校验
使用 Ascend Cert 做软件包签名校验和 CRL 更新,避免在集群交付链路中引入不可信包。 -
版本配套
MindCluster 涉及驱动、固件、CANN、Kubernetes、Volcano、Docker/containerd、AI 框架等多层版本组合。上线前必须按官方版本配套表验证。 -
故障恢复策略不要一刀切
芯片故障、节点故障、网络慢节点、公共故障、训练进程异常的处理方式不同。应按业务 RTO/RPO、Checkpoint 周期、作业规模和模型并行策略配置恢复策略。
十五、总结
MindCluster 并不是一个单独的调度器,也不是一个单纯的故障诊断工具。它更像一套面向昇腾 AI 集群的系统软件栈:
- 向下接入 NPU、驱动、CANN、容器运行时和硬件拓扑;
- 向中间扩展 Kubernetes/Volcano,完成 NPU 亲和性、多级网络亲和性和故障重调度;
- 向上服务训练/推理任务,注入集合通信配置、管理推理服务实例;
- 向运维输出指标、日志清洗、根因诊断、性能测试和安全校验能力;
- 向容错提供 Checkpoint 加速、进程级恢复、TTP/UCE/ARF 和一体机恢复路径。
对于平台开发者来说,理解 MindCluster 的最佳方式不是记住每个组件的名字,而是理解这条闭环:
部署交付 → 设备发现 → 资源上报 → 拓扑感知调度 → 容器挂载 → 任务运行
↑ ↓
└──────────── 指标采集 ← 故障诊断 ← 故障汇总 ← 任务恢复 ───┘
一旦掌握了这条闭环,再回到源码中看 Device Plugin、ClusterD、Ascend for Volcano、Ascend Operator、FaultDiag、TaskD 和 MindIO,就能清楚地知道每个组件为什么存在、在什么时候发挥作用,以及如何把它们组合成稳定可用的昇腾 AI 集群平台。
参考资料
- MindCluster 7.1.RC1 使用导读
- Ascend Deployer 安装部署工具
- MindCluster 集群调度组件
- Ascend FaultDiag 故障诊断工具
- 本地代码库:
mind-cluster/README.md、mind-cluster/docs/zh/overview.md、mind-cluster/docs/zh/scheduling/introduction.md、mind-cluster/docs/zh/faultdiag/introduction.md
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
