1. 文档说明
1.1 编写目的
规范 DeepSeek-V3.2 模型在昇腾 Atlas 800 A2/A3 服务器上的多机推理部署流程,覆盖两种落地形态:
- 基于
vllm-ascend的原生多机部署; - 基于 TIONE 在线服务的多机部署。
文档面向大模型推理服务的部署工程师、平台工程师和运维人员,用于在生产环境中完成部署、验证和排障。
1.2 适用范围
本文档适用于满足以下条件的部署场景:
- 使用
DeepSeek-V3.2-W8A8、DeepSeek-V3.2-w8a8或DeepSeek-V3.2-w8a8-mtp-QuaRot量化权重; - 硬件为 Atlas 800 A2(8 × 910B2 NPU)或 Atlas 800 A3(16 × NPU);
- 推理框架为
vllm-ascendv0.18.0rc1或更新版本; - 运行环境已完成 Ascend 驱动、CANN、HCCL 网络配置。
1.3 参考资料
| 类别 | 名称 |
|---|---|
| 官方教程 | DeepSeek-V3.2 — vllm-ascend |
| 实践文档 | content/post/DeepSeek-v3.2多机推理.docx(TIONE + vllm-ascend 实现 DeepSeek v3.2 多机推理) |
| 配套文章 | vLLM-Ascend 多机推理 HCCL 通信原理深度解析 |
1.4 术语约定
| 术语 | 含义 |
|---|---|
| DP | Data Parallel,数据并行 |
| TP | Tensor Parallel,张量并行 |
| EP | Expert Parallel,专家并行,MoE 模型专用 |
| MTP | Multi-Token Prediction,DeepSeek 投机解码方法 |
| P/D | Prefill-Decode,预填充与解码阶段分离部署 |
| Headless 节点 | 不对外提供 API,仅作为后端 engine 加入 DP 集群的工作节点 |
2. 部署形态总览
2.1 两种部署形态的职责边界
TIONE 多机推理并非独立的推理框架,其底层仍依赖 vllm-ascend、PyTorch NPU、HCCL 与 Gloo。两种形态的差异集中在资源编排层:

| 维度 | vLLM-Ascend 原生多机 | TIONE 在线服务多机 |
|---|---|---|
| 部署入口 | Docker 命令或自建编排 | TIONE 在线服务配置 |
| 模型路径 | 节点本地或共享目录,例如 /root/.cache/... |
平台数据源挂载到 /data/model |
| 节点角色识别 | 人工区分 Node0 与 headless Node1 | 由 HOSTNAME 字段或平台环境变量自动识别 |
| 网络配置 | 人工指定 local_ip、node0_ip、网卡名 |
脚本从 /etc/hosts 与 MASTER_ADDR 推导 |
| 服务入口 | Node0 对外暴露 OpenAI 兼容 API | 平台托管的在线服务入口 |
| 日志与生命周期 | 自行采集与守护 | 平台托管启动、日志、重启与发布 |
| 适用场景 | 研发验证、性能压测、定制化控制 | 生产在线服务、团队协作、统一运维 |
2.2 推荐落地路径
1) vLLM 原生双节点部署 → 验证通信与基础功能
2) 固化 HCCL / DP / TP / EP 配置
3) TIONE 在线服务配置等效资源与数据源
4) 以 master/worker 脚本复刻原生命令
5) 功能与性能验证
6) 按长上下文场景调优或切换至 P/D 分离部署
3. 硬件与版本基线
3.1 硬件要求
| 模型权重 | 硬件配置 |
|---|---|
DeepSeek-V3.2-W8A8 / DeepSeek-V3.2-w8a8 |
1 台 Atlas 800 A3(16 × NPU,64 GB 显存/卡)或 2 台 Atlas 800 A2(8 × NPU,64 GB 显存/卡) |
DeepSeek-V3.2-w8a8-mtp-QuaRot(P/D 分离示例) |
A3-752T,4 节点 |
DeepSeek-v3.2-mtp(TIONE 示例) |
2 台 Atlas 800 A2,每台 8 × 910B2 |
3.2 软件版本
| 组件 | 版本 |
|---|---|
| 推理框架 | vllm-ascend v0.18.0rc1 或更新版本 |
| 容器镜像(A2) | quay.io/ascend/vllm-ascend:v0.18.0rc1 |
| 容器镜像(A3) | quay.io/ascend/vllm-ascend:v0.18.0rc1-a3 |
| TIONE 平台 | 3.11 或兼容版本 |
| 依赖 | Ascend driver、CANN、HCCL、hccn_tool、npu-smi |
3.3 并行配置基线
| 部署形态 | DP | Local DP | TP | EP | RPC 端口 | 服务端口 |
|---|---|---|---|---|---|---|
| A2 双节点普通部署 | 2 | 1 | 8 | 开启 | 13389 | 8077 |
| A3 双节点普通部署 | 2 | 1 | 16 | 开启 | 12890 | 8077 |
| TIONE A2 双节点 | 2 | 1 | 8 | 开启 | 13389 | 8000 |
| P/D Prefill 集群 | 2 | 1 | 16 | 开启 | 12890 | 9100 |
| P/D Decode 集群 | 8 | 4 | 4 | 开启 | 12777 | 9100 |
注:TP 规模需与每个 DP rank 可见的本节点 NPU 数保持一致,避免高频 TP 集合通信跨节点。
4. 部署前置条件
4.1 网络与通信验证
执行多机部署前,必须完成以下验证项,缺失任何一项都会导致 HCCL 初始化失败。
| 检查项 | 验证方式 |
|---|---|
| NPU 网络链路状态 | hccn_tool -i <device_id> -link -g 返回 UP |
| NPU 网络健康状态 | hccn_tool -i <device_id> -net_health -g 返回 success |
| NPU IP 配置 | /etc/hccn.conf 中的 IP、netmask、gateway 正确 |
| 跨节点 NPU ping | 从本机 NPU IP ping 对端 NPU IP 成功 |
| 主机网络连通性 | 各节点间 local_ip 互通,且 DP RPC 端口未被占用 |
| 管理网卡 | HCCL_SOCKET_IFNAME、GLOO_SOCKET_IFNAME、TP_SOCKET_IFNAME 对应的网卡存在且 IP 正确 |
4.2 模型与存储
- 所有节点必须能访问同一份模型文件(权重、tokenizer、配置、自定义代码);
- 推荐方式:
- vLLM 原生部署:共享目录挂载到
/root/.cache/...; - TIONE 部署:通过平台数据源挂载到
/data/model;
- vLLM 原生部署:共享目录挂载到
- 模型代码涉及
--trust-remote-code,需在可信模型源下使用,并对远程代码进行审计。
4.3 容器运行时
所有推理容器必须具备以下能力:
--net=host:使用宿主机网络;- 挂载 NPU 设备文件:
/dev/davinci*、davinci_manager、devmm_svm、hisi_hdc; - 挂载 Ascend driver 与工具链:
/usr/local/Ascend/driver、hccn_tool、npu-smi; - 挂载模型目录。
5. vLLM-Ascend 原生多机部署
5.1 部署流程

5.2 启动容器
以 Atlas 800 A2 为例,在每个节点上执行:
export IMAGE=quay.io/ascend/vllm-ascend:v0.18.0rc1
docker run --rm \
--name vllm-ascend \
--shm-size=1g \
--net=host \
--device /dev/davinci0 \
--device /dev/davinci1 \
--device /dev/davinci2 \
--device /dev/davinci3 \
--device /dev/davinci4 \
--device /dev/davinci5 \
--device /dev/davinci6 \
--device /dev/davinci7 \
--device /dev/davinci_manager \
--device /dev/devmm_svm \
--device /dev/hisi_hdc \
-v /usr/local/dcmi:/usr/local/dcmi \
-v /usr/local/Ascend/driver/tools/hccn_tool:/usr/local/Ascend/driver/tools/hccn_tool \
-v /usr/local/bin/npu-smi:/usr/local/bin/npu-smi \
-v /usr/local/Ascend/driver/lib64/:/usr/local/Ascend/driver/lib64/ \
-v /usr/local/Ascend/driver/version.info:/usr/local/Ascend/driver/version.info \
-v /etc/ascend_install.info:/etc/ascend_install.info \
-v /root/.cache:/root/.cache \
-it $IMAGE bash
A3 镜像使用 v0.18.0rc1-a3 后缀,并挂载 davinci0 至 davinci15 共 16 个 NPU 设备。
5.3 配置通信环境变量
各节点进入容器后,根据实际网卡与 IP 设置以下变量:
# 节点本地参数,必须按实际环境修改
nic_name="eth0" # local_ip 对应的网卡名
local_ip="<current_node_ip>" # 当前节点 IP
node0_ip="<node0_ip>" # Node0 的 local_ip,所有节点保持一致
# 通用 HCCL / Gloo / TP 配置
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
# 运行时通用环境变量
export OMP_PROC_BIND=false
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export VLLM_ASCEND_ENABLE_MLAPO=1
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
A2 专属补充变量:
export OMP_NUM_THREADS=100
export HCCL_CONNECT_TIMEOUT=120
export HCCL_INTRA_PCIE_ENABLE=1
export HCCL_INTRA_ROCE_ENABLE=0
A3 使用:
export OMP_NUM_THREADS=10
5.4 启动 Node0(Master)
A2 双节点 Node0 启动命令:
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/DeepSeek-V3.2-W8A8 \
--host 0.0.0.0 \
--port 8077 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 8 \
--quantization ascend \
--seed 1024 \
--served-model-name deepseek_v3_2 \
--enable-expert-parallel \
--max-num-seqs 16 \
--max-model-len 8192 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.92 \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "cudagraph_capture_sizes":[8, 16, 24, 32, 40, 48]}' \
--additional-config '{"layer_sharding": ["q_b_proj", "o_proj"]}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}'
5.5 启动参数详解
本节对第 5.4 节 Node0 命令中出现的全部启动参数逐项说明。参数定义以 vllm serve 官方 CLI 文档 为准,取值建议参照 DeepSeek-V3.2 — vllm-ascend 教程。
5.5.1 位置参数:模型路径
| 参数 | 作用 | 教程取值 |
|---|---|---|
<model> |
vllm serve 的位置参数,指向模型权重所在目录。支持本地路径或 HuggingFace/ModelScope 模型名。 |
/root/.cache/modelscope/hub/models/vllm-ascend/DeepSeek-V3.2-W8A8 |
5.5.2 服务端参数
| 参数 | 默认值 | 作用 | 本文档取值 |
|---|---|---|---|
--host |
未指定(绑定所有接口) | 服务监听的主机地址。多机部署需设置为 0.0.0.0 以接受跨主机请求。 |
0.0.0.0 |
--port |
8000 |
OpenAI 兼容 API 监听端口。 | 8077 |
--headless |
False |
以 headless 模式运行,节点仅作为后端 engine 加入 DP 集群,不对外暴露 API。仅辅助节点需设置。 | Node0 不设置;Node1 设置 |
5.5.3 数据并行参数
| 参数 | 简写 | 默认值 | 作用 | 本文档取值 |
|---|---|---|---|---|
--data-parallel-size |
-dp |
1 |
数据并行组总数。MoE 层权重按 tp_size × dp_size 分片。 |
2 |
--data-parallel-size-local |
-dpl |
无 | 当前节点上运行的 DP 副本数。需保证所有节点 local 之和 = --data-parallel-size。 |
1 |
--data-parallel-address |
-dpa |
无 | DP 集群 head node(Node0)的 IP,所有节点必须保持一致。 | $node0_ip |
--data-parallel-rpc-port |
-dpp |
无 | DP 控制面 RPC 端口,所有节点一致且未被占用。 | 13389 |
--data-parallel-start-rank |
-dpr |
无 | 辅助节点的起始 DP rank。Node0 默认从 0 开始;Node1 须设置为已分配 rank 数之后的第一个编号。 | Node1 使用 1 |
5.5.4 张量并行与专家并行参数
| 参数 | 简写 | 默认值 | 作用 | 本文档取值 |
|---|---|---|---|---|
--tensor-parallel-size |
-tp |
1 |
TP 组大小。每个 DP 副本内部使用的 NPU 数量,建议等于本节点可见 NPU 数。 | A2:8;A3:16 |
--enable-expert-parallel |
-ep |
False |
对 MoE 层启用专家并行。DeepSeek-V3.2 为 MoE 架构,必须启用。 | 启用 |
5.5.5 模型与加载参数
| 参数 | 简写 | 默认值 | 作用 | 本文档取值 |
|---|---|---|---|---|
--quantization |
-q |
None |
权重量化方案。未指定时优先读取模型配置,否则按 dtype 装载未量化权重。 |
ascend:启用 vLLM-Ascend 专用量化路径以加载 W8A8 权重 |
--seed |
— | 0 |
全局随机种子,用于保证各 TP worker 采样一致,避免 token 不同步。 | 1024 |
--served-model-name |
— | 使用 --model 的值 |
API 响应与 Prometheus model_name 标签使用的模型名称。 |
deepseek_v3_2 |
--trust-remote-code |
— | False |
允许加载模型仓库中的自定义 Python 代码(DeepSeek 架构代码在此路径中)。需仅对可信模型源使用。 | 启用 |
5.5.6 调度器参数
| 参数 | 默认值 | 作用 | 本文档取值 |
|---|---|---|---|
--max-num-seqs |
引擎内部默认 | 单次 iteration 中允许并发的最大序列数。直接决定并发上限和 KV cache 占用。 | 16 |
--max-num-batched-tokens |
引擎内部默认 | 单次 iteration 中允许处理的最大 token 数(合并所有序列)。支持 1k、2M 等人类可读单位。 |
4096 |
--max-model-len |
自动推断 | 模型上下文长度上限(prompt + 生成)。未指定时从模型配置推断;-1 或 auto 表示按显存自动选择。 |
8192 |
5.5.7 KV Cache 与前缀缓存
| 参数 | 默认值 | 作用 | 本文档取值 |
|---|---|---|---|
--gpu-memory-utilization |
0.92 |
当前实例允许占用的 NPU 显存比例,取值 0–1。不影响同设备其他 vLLM 实例。 | 0.92 |
--no-enable-prefix-caching |
— | 显式关闭前缀缓存。教程推荐在 DeepSeek-V3.2 部署中关闭,以避免与 MTP 投机解码及长上下文共存时的兼容问题。 | 启用(即关闭前缀缓存) |
5.5.8 高级 JSON 配置
高级配置支持两种等价写法,本文档统一使用完整 JSON 字符串格式。
--compilation-config / -cc
用于配置 torch.compile 与 CUDA/ACL Graph 的捕获行为。
| 子字段 | 作用 | 本文档取值 | 备注 |
|---|---|---|---|
cudagraph_mode |
控制 Graph 捕获策略。 | FULL_DECODE_ONLY |
教程示例统一使用该值,仅在 decode 阶段捕获 graph,避免 prefill 阶段的动态 shape 问题。 |
cudagraph_capture_sizes |
需要捕获的 batch size 列表;取值通常 ≤ --max-num-seqs。 |
[8, 16, 24, 32, 40, 48] |
实际运行 batch 必须命中列表,否则会 fallback 到非 graph 执行并带来抖动。 |
--additional-config
平台相关的附加配置,值必须可哈希。
| 子字段 | 作用 | 本文档取值 | 备注 |
|---|---|---|---|
layer_sharding |
vLLM-Ascend 特有字段,指定需要进一步做层级切分的模块列表。 | ["q_b_proj", "o_proj"] |
教程中多机与 P/D Prefill 场景使用该值;其他字段(如 recompute_scheduler_enable)仅在 P/D Decode 使用。 |
--speculative-config / -sc
配置投机解码(speculative decoding)。
| 子字段 | 作用 | 本文档取值 | 备注 |
|---|---|---|---|
method |
投机解码算法。 | deepseek_mtp |
教程固定取值,使用 DeepSeek 官方 MTP。 |
num_speculative_tokens |
每步投机预测 token 数。 | 3 |
普通多机推荐 3,P/D 分离推荐 2。取值增大可提高吞吐,但会增加单步计算成本。 |
5.5.9 参数必要性与差异速查
| 参数 | Node0 | Node1 | 必要性 | 变更影响 |
|---|---|---|---|---|
<model> |
✓ | ✓ | 必填 | 各节点路径必须一致 |
--host / --port |
✓ | ✓ | 必填 | 端口冲突会导致启动失败 |
--headless |
— | ✓ | Node1 必填 | 缺失则 Node1 会尝试独立对外提供服务 |
--data-parallel-size |
✓ | ✓ | 必填 | 各节点值必须一致 |
--data-parallel-size-local |
✓ | ✓ | 必填 | 所有节点之和 = --data-parallel-size |
--data-parallel-start-rank |
— | ✓ | Node1 必填 | 缺失或冲突将导致 rank 编排错误 |
--data-parallel-address |
✓ | ✓ | 必填 | 必须等于 Node0 的 local_ip |
--data-parallel-rpc-port |
✓ | ✓ | 必填 | 各节点值必须一致,且端口未被占用 |
--tensor-parallel-size |
✓ | ✓ | 必填 | 须与本节点可见 NPU 数匹配 |
--quantization |
✓ | ✓ | W8A8 权重必填 | BF16 权重可不设 |
--enable-expert-parallel |
✓ | ✓ | MoE 必填 | DeepSeek-V3.2 必须启用 |
--trust-remote-code |
✓ | ✓ | 必填 | 加载 DeepSeek 自定义代码所需 |
--seed |
✓ | ✓ | 推荐 | 保证各 TP worker 采样一致 |
--served-model-name |
✓ | ✓ | 推荐 | 必须与客户端请求的 model 一致 |
--max-num-seqs / --max-num-batched-tokens / --max-model-len |
✓ | ✓ | 按业务 | 取值过大易 OOM,过小影响吞吐 |
--gpu-memory-utilization |
✓ | ✓ | 推荐 | 超过 0.95 需验证显存余量 |
--no-enable-prefix-caching |
✓ | ✓ | 推荐 | 教程建议在 DeepSeek-V3.2 场景下关闭 |
--compilation-config |
✓ | ✓ | 推荐 | cudagraph_capture_sizes 需覆盖实际 batch |
--additional-config |
✓ | ✓ | 多机推荐 | layer_sharding 为 vLLM-Ascend 特有字段 |
--speculative-config |
✓ | ✓ | 可选 | 开启可提升吞吐,代价是单步计算成本 |
5.6 启动 Node1(Headless Worker)
Node1 在 Node0 命令基础上增加 --headless 与 --data-parallel-start-rank 1:
vllm serve /root/.cache/modelscope/hub/models/vllm-ascend/DeepSeek-V3.2-W8A8 \
--host 0.0.0.0 \
--port 8077 \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 8 \
--quantization ascend \
--seed 1024 \
--served-model-name deepseek_v3_2 \
--enable-expert-parallel \
--max-num-seqs 16 \
--max-model-len 8192 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--no-enable-prefix-caching \
--gpu-memory-utilization 0.92 \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "cudagraph_capture_sizes":[8, 16, 24, 32, 40, 48]}' \
--additional-config '{"layer_sharding": ["q_b_proj", "o_proj"]}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}'
--headless 表示该节点不对外提供 API,仅作为后端 engine;--data-parallel-start-rank 1 确保 Node1 从全局 DP rank 1 开始,避免与 Node0 的 rank 0 冲突。两个参数的详细定义参见 5.5.2 服务端参数 与 5.5.3 数据并行参数。
5.7 A2 与 A3 配置差异
| 配置项 | A2 双节点 | A3 双节点 |
|---|---|---|
| 每节点 NPU | 8 | 16 |
| 全局 DP | 2 | 2 |
| 本地 DP | 1 | 1 |
| TP size | 8 | 16 |
| DP RPC 端口 | 13389 | 12890 |
| OMP_NUM_THREADS | 100 | 10 |
| 额外 HCCL 变量 | HCCL_CONNECT_TIMEOUT / HCCL_INTRA_PCIE_ENABLE / HCCL_INTRA_ROCE_ENABLE |
无额外 |
6. TIONE 在线服务多机部署
6.1 部署架构

本节参考 TIONE 3.11 + vllm-ascend-v018:v0.18.0rc1 + DeepSeek-v3.2-mtp 的生产实践配置,硬件为 2 台 Atlas 800 A2(8 × 910B2)。
6.2 数据源配置
模型文件通过 TIONE 平台的共享存储(也可选用 NAS)挂载到推理实例的 /data/model 目录。
配置要点:
- 数据源类型:平台共享存储或 NAS;
- 挂载路径:固定为
/data/model; - 权限:容器内用户需具备读权限,日志目录
/data/model/logs需具备写权限; - 一致性:所有实例使用同一份数据源,确保权重、tokenizer、配置和自定义代码版本一致。
6.3 在线服务配置
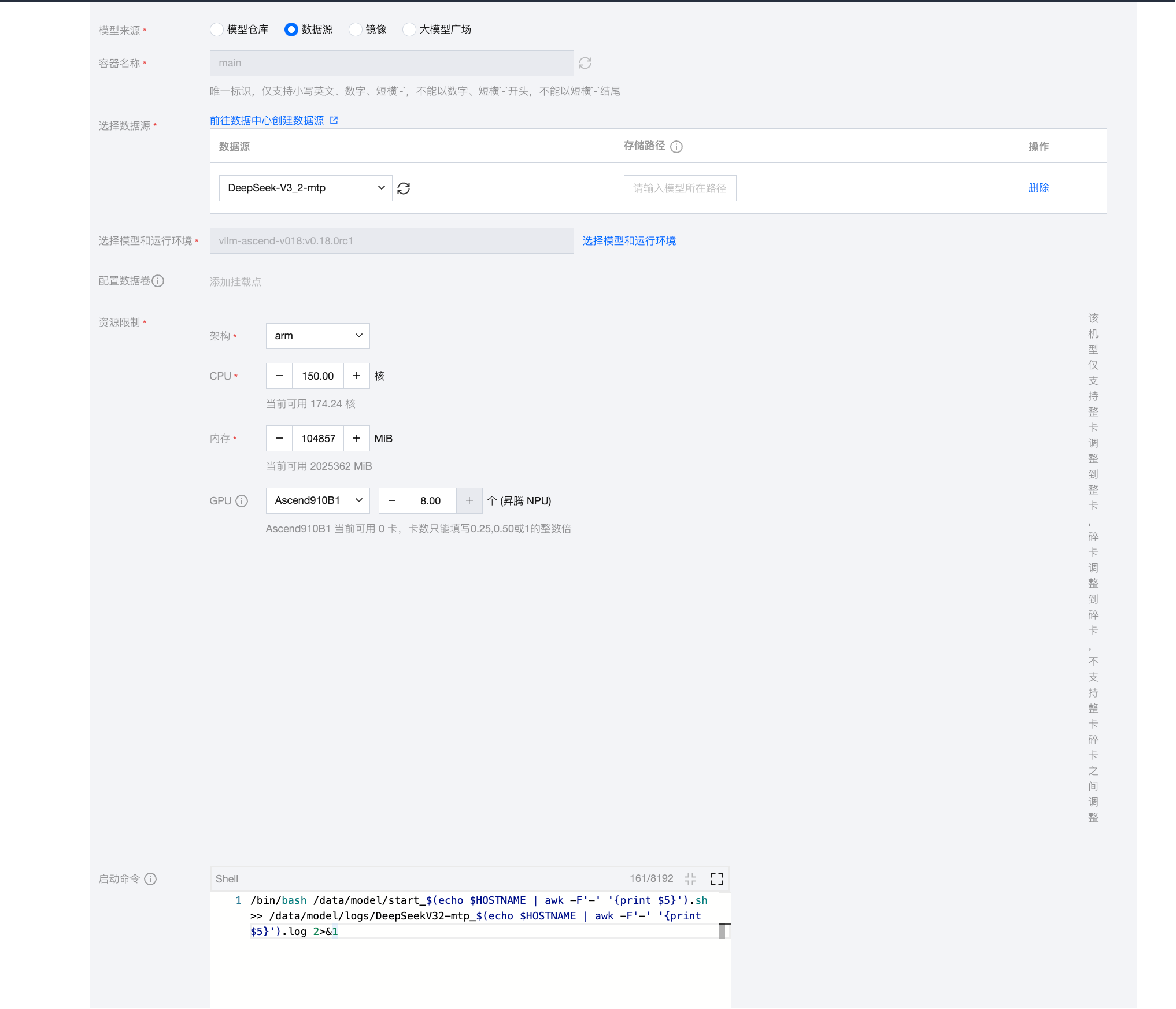
服务启动命令:
/bin/bash /data/model/start_$(echo $HOSTNAME | awk -F'-' '{print $5}').sh \
>> /data/model/logs/DeepSeekV32-mtp_$(echo $HOSTNAME | awk -F'-' '{print $5}').log 2>&1
角色识别机制:
- 实例
HOSTNAME的第 5 个字段(以-分隔)标识角色,例如master或worker; - 对应脚本:
/data/model/start_master.sh、/data/model/start_worker.sh; - 日志独立写入
/data/model/logs/DeepSeekV32-mtp_<role>.log。
6.4 start_master.sh
#!/bin/bash
# 推理和函数调用相关的附加参数
EXTRA_PARAMS=${EXTRA_PARAMS:-"--reasoning-parser deepseek_v3 --enable-auto-tool-choice --tool-call-parser deepseek_v32 --tokenizer-mode deepseek_v32"}
# nic_name 为当前节点 local_ip 对应的网卡名
nic_name=${NIC_NAME:-"eth0"}
local_ip=$(grep $HOSTNAME /etc/hosts | awk '{print $1}')
# node0_ip 必须与 master 节点的 local_ip 一致
node0_ip=${MASTER_ADDR:-$local_ip}
# HCCL / Gloo / TP 通信配置
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
# 运行时环境变量
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=100
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export VLLM_ASCEND_ENABLE_MLAPO=1
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
export HCCL_CONNECT_TIMEOUT=120
export HCCL_INTRA_PCIE_ENABLE=1
export HCCL_INTRA_ROCE_ENABLE=0
vllm serve /data/model \
--host 0.0.0.0 \
--port 8000 \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 8 \
--quantization ascend \
--seed 1024 \
--served-model-name DeepSeek-V3_2-mtp \
--enable-expert-parallel \
--max-num-seqs 8 \
--max-model-len 60000 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--gpu-memory-utilization 0.95 \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "cudagraph_capture_sizes":[8, 16, 24]}' \
--additional-config '{"layer_sharding": ["q_b_proj", "o_proj"]}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}' \
$EXTRA_PARAMS
6.5 start_worker.sh
Worker 脚本在 master 脚本基础上增加 --headless 与 --data-parallel-start-rank 1:
#!/bin/bash
EXTRA_PARAMS=${EXTRA_PARAMS:-"--reasoning-parser deepseek_v3 --enable-auto-tool-choice --tool-call-parser deepseek_v32 --tokenizer-mode deepseek_v32"}
nic_name=${NIC_NAME:-"eth0"}
local_ip=$(grep $HOSTNAME /etc/hosts | awk '{print $1}')
node0_ip=${MASTER_ADDR:-$local_ip}
export HCCL_OP_EXPANSION_MODE="AIV"
export HCCL_IF_IP=$local_ip
export GLOO_SOCKET_IFNAME=$nic_name
export TP_SOCKET_IFNAME=$nic_name
export HCCL_SOCKET_IFNAME=$nic_name
export OMP_PROC_BIND=false
export OMP_NUM_THREADS=100
export VLLM_USE_V1=1
export HCCL_BUFFSIZE=200
export VLLM_ASCEND_ENABLE_MLAPO=1
export PYTORCH_NPU_ALLOC_CONF=expandable_segments:True
export VLLM_ASCEND_ENABLE_FLASHCOMM1=1
export HCCL_CONNECT_TIMEOUT=120
export HCCL_INTRA_PCIE_ENABLE=1
export HCCL_INTRA_ROCE_ENABLE=0
vllm serve /data/model \
--host 0.0.0.0 \
--port 8000 \
--headless \
--data-parallel-size 2 \
--data-parallel-size-local 1 \
--data-parallel-start-rank 1 \
--data-parallel-address $node0_ip \
--data-parallel-rpc-port 13389 \
--tensor-parallel-size 8 \
--quantization ascend \
--seed 1024 \
--served-model-name DeepSeek-V3_2-mtp \
--enable-expert-parallel \
--max-num-seqs 8 \
--max-model-len 60000 \
--max-num-batched-tokens 4096 \
--trust-remote-code \
--gpu-memory-utilization 0.95 \
--compilation-config '{"cudagraph_mode": "FULL_DECODE_ONLY", "cudagraph_capture_sizes":[8, 16, 24]}' \
--additional-config '{"layer_sharding": ["q_b_proj", "o_proj"]}' \
--speculative-config '{"num_speculative_tokens": 3, "method": "deepseek_mtp"}' \
$EXTRA_PARAMS
6.6 TIONE 实践配置与官方示例的差异
| 参数 | TIONE 实践值 | 官方 A2 示例值 | 差异原因 |
|---|---|---|---|
--port |
8000 | 8077 | 对齐平台在线服务默认端口 |
--served-model-name |
DeepSeek-V3_2-mtp |
deepseek_v3_2 |
显式标识 MTP 投机解码能力 |
--max-num-seqs |
8 | 16 | 长上下文场景下控制并发,降低显存压力 |
--max-model-len |
60000 | 8192 | 面向长上下文应用 |
--gpu-memory-utilization |
0.95 | 0.92 | 更激进利用 NPU 显存 |
cudagraph_capture_sizes |
[8, 16, 24] |
[8, 16, 24, 32, 40, 48] |
与 max-num-seqs=8 匹配 |
EXTRA_PARAMS |
开启 reasoning parser、tool choice、deepseek_v32 tokenizer mode |
无 | 支持 Agent 与工具调用场景 |
--no-enable-prefix-caching |
未显式设置 | 显式关闭 | TIONE 侧保留默认行为 |
6.7 TIONE 部署关键约束
HOSTNAME命名约束:平台实例命名规则必须保证第 5 个字段正确区分master与worker,否则启动命令会选到错误脚本。MASTER_ADDR注入:Worker 实例必须能从环境变量中读到 master IP。若未注入,脚本中node0_ip=${MASTER_ADDR:-$local_ip}会退化为 worker 自身 IP,导致 DP 集群无法汇合。/etc/hosts解析:脚本通过grep $HOSTNAME /etc/hosts获取local_ip,需确保平台在实例启动时写入了正确的主机名解析。- 日志目录可写:
/data/model/logs目录必须具备写权限,且容量足够承载长时间运行日志,避免撑满模型盘。
7. Prefill-Decode 分离部署
7.1 适用场景
P/D 分离适用于以下场景:
- 输入上下文长度 ≥ 32k,Prefill 阶段耗时显著;
- 对 TPOT 有严格要求的在线服务;
- Prefill 与 Decode 吞吐瓶颈差异明显;
- 可提供 ≥ 4 节点的 A3-752T 或同等硬件资源。
普通双节点 serving 已能满足需求时,不建议引入 P/D 分离,避免增加运维复杂度。
7.2 部署架构

官方性能基线:
| 项 | 值 |
|---|---|
| 硬件 | A3-752T,4 节点 |
| 部署形态 | 1P1D |
| Prefill 配置 | DP2 + TP16 |
| Decode 配置 | DP8 + TP4 |
| 输入 / 输出长度 | 64k / 3k |
| 性能 | 533 tps |
| TPOT | 32 ms |
7.3 KV 传输配置
Prefill 与 Decode 之间通过 MooncakeLayerwiseConnector 按层传输 KV cache。
Prefill 侧(kv_producer):
{
"kv_connector": "MooncakeLayerwiseConnector",
"kv_role": "kv_producer",
"kv_port": "30000",
"engine_id": "0",
"kv_connector_extra_config": {
"prefill": {"dp_size": 2, "tp_size": 16},
"decode": {"dp_size": 8, "tp_size": 4}
}
}
Decode 侧(kv_consumer):
{
"kv_connector": "MooncakeLayerwiseConnector",
"kv_role": "kv_consumer",
"kv_port": "30100",
"engine_id": "1",
"kv_connector_extra_config": {
"prefill": {"dp_size": 2, "tp_size": 16},
"decode": {"dp_size": 8, "tp_size": 4}
}
}
KV 传输链路独立于 HCCL 集合通信,不应与 TP/EP 内部 AllReduce、AllGather 混为一谈。
7.4 启动命令
使用 launch_online_dp.py 统一拉起各节点 DP 实例:
# Prefill Node0
python launch_online_dp.py \
--dp-size 2 --tp-size 16 --dp-size-local 1 \
--dp-rank-start 0 \
--dp-address <prefill_node0_ip> --dp-rpc-port 12890 \
--vllm-start-port 9100
# Prefill Node1
python launch_online_dp.py \
--dp-size 2 --tp-size 16 --dp-size-local 1 \
--dp-rank-start 1 \
--dp-address <prefill_node0_ip> --dp-rpc-port 12890 \
--vllm-start-port 9100
# Decode Node0
python launch_online_dp.py \
--dp-size 8 --tp-size 4 --dp-size-local 4 \
--dp-rank-start 0 \
--dp-address <decode_node0_ip> --dp-rpc-port 12777 \
--vllm-start-port 9100
# Decode Node1
python launch_online_dp.py \
--dp-size 8 --tp-size 4 --dp-size-local 4 \
--dp-rank-start 4 \
--dp-address <decode_node0_ip> --dp-rpc-port 12777 \
--vllm-start-port 9100
请求由 load_balance_proxy_layerwise_server_example.py 代理,统一分发至 Prefill 与 Decode 集群。
8. 验证与测试
8.1 功能验证
服务启动后执行以下请求,注意 model 字段必须与 --served-model-name 严格一致。
vLLM 官方示例:
curl http://<node0_ip>:8077/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "deepseek_v3_2",
"prompt": "The future of AI is",
"max_completion_tokens": 50,
"temperature": 0
}'
TIONE 实践示例:
curl http://<master_ip>:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "DeepSeek-V3_2-mtp",
"prompt": "请用三句话解释 vLLM 多机推理中的 DP 和 TP。",
"max_completion_tokens": 128,
"temperature": 0
}'
8.2 性能测试
使用 vllm bench serve 进行在线服务吞吐测试:
export VLLM_USE_MODELSCOPE=True
vllm bench serve \
--model /root/.cache/Eco-Tech/DeepSeek-V3.2-w8a8-mtp-QuaRot \
--dataset-name random \
--random-input 200 \
--num-prompts 200 \
--request-rate 1 \
--save-result \
--result-dir ./
8.3 验收指标
| 指标 | 验收要求 |
|---|---|
| 首 token 延迟(TTFT) | 与基线配置偏差 ≤ 10% |
| 输出 token 间延迟(TPOT) | 与基线配置偏差 ≤ 10% |
| 吞吐(tokens/s) | 随 DP 扩展呈接近线性增长 |
| 错误率 | ≤ 0.1% |
| NPU 利用率 | 无长时间单 rank 空转 |
| HBM 占用 | 峰值 ≤ --gpu-memory-utilization 设定值 |
9. 运维与排障
9.1 部署检查清单
| 分类 | 检查项 | 期望状态 |
|---|---|---|
| 网络 | HCCL_IF_IP = $local_ip |
一致 |
| 网络 | HCCL_SOCKET_IFNAME 等 = 实际网卡 |
一致 |
| 网络 | 跨节点 NPU ping | 成功 |
| 网络 | DP RPC 端口未占用 | 可用 |
| Rank | Node0 无 --headless,Node1 含 --headless |
正确 |
| Rank | --data-parallel-start-rank Node0=默认,Node1=1 |
正确 |
| Rank | --data-parallel-size 各节点一致 |
一致 |
| 模型 | 各节点模型路径一致 | 一致 |
| 模型 | --served-model-name 与请求 model 一致 |
一致 |
| 容器 | --net=host |
已启用 |
| 容器 | NPU 设备与驱动挂载完整 | 完整 |
9.2 常见故障定位
| 故障现象 | 可能原因 | 排查步骤 |
|---|---|---|
| Worker 无法加入集群 | MASTER_ADDR 未注入,node0_ip 退化为自身 IP |
在 worker 中 echo $MASTER_ADDR、grep $HOSTNAME /etc/hosts |
| 启动后请求卡住 | HCCL 通信初始化未完成 | 检查 HCCL_IF_IP、HCCL_SOCKET_IFNAME、NPU 链路状态 |
model not found |
请求 model 与 served-model-name 不一致 |
核对请求体与启动参数 |
| 大 batch 超时或 OOM | max-model-len / max-num-seqs / gpu-memory-utilization 过激 |
逐项下调并重试 |
| EP 场景部分 rank 空转 | DP coordinator 未调度空 rank dummy forward | 检查 --enable-expert-parallel 是否在所有节点一致 |
| TPOT 抖动 | CUDAGraph capture sizes 未覆盖实际 batch | 将实际运行 batch 加入 cudagraph_capture_sizes |
| HCCL 连接超时 | 网络抖动或 HCCL_CONNECT_TIMEOUT 过小 |
增大 HCCL_CONNECT_TIMEOUT,或检查跨节点网络 |
9.3 部署方式选择矩阵
| 场景 | 推荐方案 | 理由 |
|---|---|---|
| 首次验证多机通信 | vLLM 原生 | 便于直接定位 HCCL/rank/网络问题 |
| 性能压测与参数探索 | vLLM 原生 | 参数调整灵活,日志直接 |
| 团队共享在线服务 | TIONE 在线服务 | 平台化入口、实例管理与日志 |
| 生产稳定发布 | TIONE 在线服务 | 支持平台运维与版本管理 |
| 长上下文高吞吐 | vLLM P/D 分离 | Prefill 与 Decode 独立扩展 |
10. 总结
- DeepSeek-V3.2 多机推理的核心复杂度在于通信拓扑与 rank 编排,而非模型本身的启动。
- vLLM-Ascend 原生部署显式暴露 HCCL、DP、TP、EP 的全部配置,是验证多机通信与性能调优的首选形态。
- TIONE 在线服务在同一套
vllm-ascend运行时之上提供平台化封装,将模型交付、实例编排、日志与入口沉淀为可复用配置,适合生产环境稳定交付。 - 长上下文高吞吐场景可进一步引入 Prefill-Decode 分离部署,通过
MooncakeLayerwiseConnector解耦两个阶段的资源画像。 - 无论选择哪种形态,必须先完成网络、NPU 拓扑与 rank 编排的验证,再进入功能与性能测试阶段。
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
