一、引言:AI 应用开发范式的转变
原文链接:Harnessing Claude’s Intelligence 作者:Lance Martin(Anthropic Claude 平台技术团队) 发布时间:2026 年 4 月 2 日
Anthropic 联合创始人 Chris Olah 曾说过一句意味深长的话:
“像 Claude 这样的生成式 AI 系统是’培育’出来的,而不是’建造’出来的。”
研究人员设定条件来引导模型的成长,但最终涌现出的具体结构或能力并不总是可预测的。这意味着,围绕 Claude 构建的应用程序也需要持续适配模型能力的变化——不是一次性的架构设计,而是一个持续演进的过程。

这篇来自 Anthropic 官方的技术博客,由 Claude 平台团队的 Lance Martin 撰写,系统性地提出了三大核心模式,帮助开发者在 Claude 不断进化的背景下,构建能够平衡智能(Intelligence)、延迟(Latency) 和 成本(Cost) 的应用程序。
本文将对这三大模式进行深度技术解析,并结合具体的工程实践和基准测试数据,为开发者提供可落地的架构指导。需要说明的是:文中的配图、流程图和伪代码主要用于解释原文机制,均为作者基于原文整理的概念示意,并非 Anthropic 官方原图或官方接口定义。
二、概念关系图:从基础工具到高阶模式
在深入三大模式之前,先做一个边界说明:原文并没有给出“应用层 / 编排层 / 基础层”的正式三层架构。 为了帮助理解,我把文中出现的工具与机制整理成下面这张概念关系图。

图注:作者基于原文整理的概念关系图,非官方分层架构。
原文明确给出的事实是:Claude 已经非常熟悉 bash 工具和文本编辑器工具,而 Agent Skills、programmatic tool calling、memory tool / memory folder 这些更高阶的模式,都可以建立在这类通用工具之上。因此,与其为 Claude 设计一套过于复杂的专用工具体系,不如优先使用它已经“理解良好”的能力单元。
三、模式一:使用 Claude 已知的能力
3.1 核心理念
第一个模式的核心是一个反直觉的建议:不要给 Claude 使用你认为它需要的工具,而是使用 Claude 理解良好的工具来构建应用。
Claude 3.5 Sonnet 在 2024 年底于 SWE-bench Verified 基准上达到了 49% 的准确率,而它仅使用了两个工具:
| 工具 | 功能 | 特点 |
|---|---|---|
| Bash 工具 | 执行 shell 命令 | 通用、可组合、Claude 深度理解 |
| 文本编辑器工具 | 查看、创建、编辑文件 | 覆盖代码修改全生命周期 |

图注:作者基于原文整理的三大模式概览图。
3.2 从基础工具到复杂模式
这两个简单工具的威力在于它们的可组合性。通过组合,它们可以构建出三种更高级的模式:

Agent Skills(代理技能)
技能本质上是预定义的、可按需加载的上下文片段。每个技能包含:
- YAML 前置元数据:简短描述,始终预加载在上下文窗口中
- 完整内容:通过读取文件工具按需加载
# 技能元数据示例(始终可见)
name: api-design
description: "Guides REST and GraphQL API design"
trigger: "designing APIs, creating endpoints"
# 完整内容(按需加载)
# → Claude 根据任务判断是否需要调用 read_file 加载
这种设计的精妙之处在于:它把上下文管理的决策权交给了 Claude 自身。
Programmatic Tool Use(程序化工具调用)
不是每个工具调用的结果都需要流经 Claude 的上下文窗口。通过代码执行工具,Claude 可以:
- 编写代码来表达工具调用和它们之间的逻辑
- 决定过滤哪些结果、管道传输到下一个调用
- 只有最终输出到达 Claude 的上下文窗口
Memory Tools(记忆工具)
允许 Claude 将上下文写入文件并在需要时读取,实现跨会话的信息持久化。
3.3 工程启示
核心原则:Claude Code 就是基于这些相同的基础工具构建的。如果你正在构建代理应用,首先考虑 Claude 最擅长使用的工具,而不是设计最多功能的工具集。
四、模式二:问自己"我可以停止做什么?"
这是三大模式中最具颠覆性的一个。随着 Claude 能力的持续提升,开发者需要不断重新评估代理框架(agent harness)中的假设——特别是那些为弥补模型不足而添加的“辅助轮”。
4.1 让 Claude 编排自己的操作
问题:工具结果的上下文膨胀
传统假设是:每个工具调用的结果都应该流经 Claude 的上下文窗口,以便 Claude 做出下一步决策。但这会导致:
- 速度慢:大量的工具输出占用处理时间
- 成本高:每个 token 都有计费
- 不必要:许多中间结果对最终决策没有价值
解决方案:代码执行作为编排层
提供代码执行工具(Bash 或特定语言 REPL),让 Claude 自己决定信息流的编排:

基准测试数据
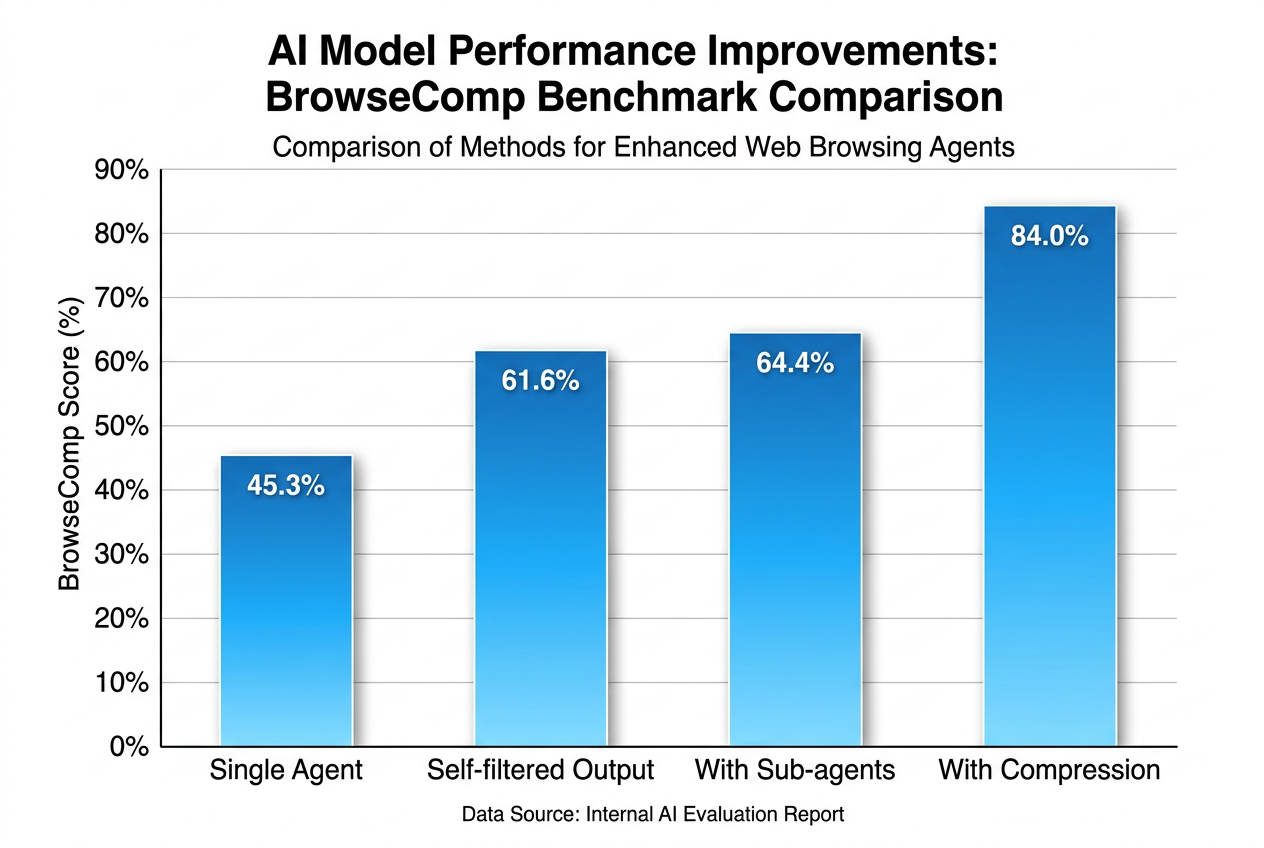
这种方法在 BrowseComp 基准上产生了显著的效果:
| 方法 | 模型 | BrowseComp 准确率 |
|---|---|---|
| 标准模式(全部结果流经上下文) | Opus 4.6 | 45.3% |
| 自编排模式(Claude 过滤自己的工具输出) | Opus 4.6 | 61.6% |
提升幅度:+16.3 个百分点(+36% 相对提升)
4.2 让 Claude 管理自己的上下文
问题:手工系统提示的注意力稀释
为每种任务手工编写特定的系统提示词(System Prompt)是不可扩展的。每添加一个 token 到系统提示中,都会消耗 Claude 有限的注意力预算,而大部分内容在任何给定任务中可能是无关的。
三种上下文管理策略

子代理的关键价值在于上下文隔离:特定任务的工作在独立的上下文窗口中进行,不会污染主代理的上下文。
子代理基准数据
使用 Opus 4.6,生成子代理的能力在 BrowseComp 上比最佳单代理运行提高了 2.8%。看似不大,但在接近基准天花板时,每一个百分点的提升都意味着模型处理了更多高难度边界情况。
4.3 让 Claude 持久化自己的上下文
问题:上下文窗口的物理限制
长期运行的代理任务(如多日代码重构、持续学习)可能超过单个上下文窗口的容量限制。
两种持久化策略
策略一:Compaction(压缩/精简)
原文这里使用的术语是 Compaction。它的核心思想是:让 Claude 对已经积累的上下文进行总结与提炼,使长期任务在切换到新的上下文窗口后仍能保持连续性。

图注:作者基于原文整理的 Compaction 示意图。
策略二:记忆文件夹(Memory Folder)
另一种方式是让 Claude 把信息写入文件,并在之后按需读取。原文强调了 memory folder 的思路,但没有规定统一的固定目录路径或标准目录结构。 换句话说,重点不在“目录应该长什么样”,而在于:Claude 是否已经学会把长期任务中的关键经验、状态和失败教训持久化下来。
跨模型的 Compaction 性能对比
不同模型在利用 Compaction 策略时表现出显著的能力差异:
| 模型 | BrowseComp(无 Compaction) | BrowseComp(有 Compaction) | 提升 |
|---|---|---|---|
| Sonnet 4.5 | 43% | 43% | 0%(无论给多少 compaction 预算) |
| Opus 4.5 | - | 68% | 显著提升 |
| Opus 4.6 | - | 84% | 极大提升 |
关键发现:Compaction 不是简单地“压缩文本”,而是要判断哪些信息值得被保留下来,用于支撑未来任务的连续性。原文的数据恰恰说明,这种能力与模型本身的智能水平强相关。
记忆文件夹的量化效果
在 BrowseComp-Plus 基准上,给 Sonnet 4.5 提供记忆文件夹,准确率从 60.4% 提升到 67.2%。这说明即使对 Compaction 不敏感的模型,也可能从外部持久化记忆中受益。
4.4 案例研究:从 Sonnet 3.5 到 Opus 4.6 的记忆进化
原文用《宝可梦》代理作为一个很生动的长期任务案例。它展示的不是“模型会不会写文件”,而是模型是否知道该记住什么,以及如何把记忆组织成真正可复用的工作资料。
| 维度 | Sonnet 3.5 | Opus 4.6 |
|---|---|---|
| 步数 | 14,000 步 | 同样 14,000 步 |
| 记忆方式 | 更像“转录记录”,记录 NPC 说过的话 | 主动组织信息,形成更可执行的战术知识 |
| 文件数量 | 31 个文件,其中还包含近重复内容 | 10 个文件,并且按目录组织 |
| 游戏进度 | 仍停留在第二个城镇 | 已获得 3 个徽章 |
| 元认知表现 | 原文未强调明显的失败反思机制 | 维护了一个从失败中提炼经验的学习文件 |
这个案例生动地说明了:更强的模型不仅更会“用工具”,也更会“组织自己的工作记忆”。
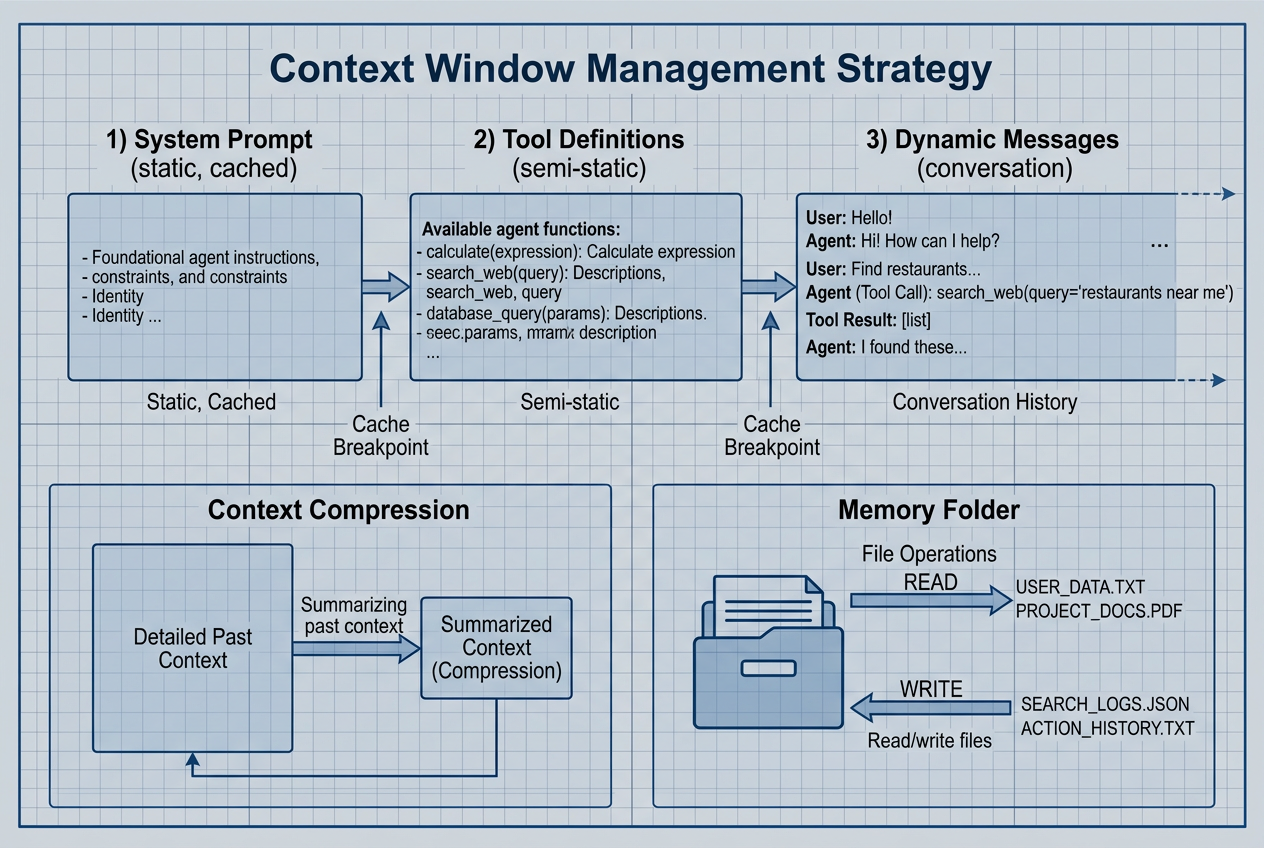
图注:作者基于原文整理的上下文管理策略示意图。
五、模式三:精准设置边界
代理框架(agent harness)为 Claude 提供结构性约束,用来落实 UX、成本 与 安全 要求。但原文的重点不是“多设一些边界”,而是只在真正需要的地方设边界。
5.1 设计上下文以最大化缓存命中
Messages API 是无状态的——Claude 无法直接看到之前轮次的会话历史。因此,多轮应用往往需要不断重新发送上下文,而这正是 Prompt Caching 发挥价值的地方。
缓存优化的五大原则

图注:作者基于原文整理的缓存优化原则图。
| 原则 | 原文要点 | 工程含义 |
|---|---|---|
| 静态优先 | 稳定内容放前,动态内容放后 | 系统提示、工具定义尽量稳定 |
| 消息追加 | 用 <system-reminder> 追加更新,而不是编辑提示 |
降低缓存前缀失效概率 |
| 不切换模型 | 缓存与模型绑定 | 会话中频繁换模型会破坏缓存收益 |
| 谨慎管理工具 | 工具定义位于缓存前缀中 | 动态增删工具会让缓存失效 |
| 更新断点 | 多轮应用应移动断点位置 | 让可复用前缀尽可能长 |
成本影响:缓存 token 的价格仅为基础输入 token 的 10%。
动态工具发现:原文给的是模式,不是固定 API
原文建议:如果工具集合需要动态发现,应考虑 tool search 这类模式,而不是每轮都直接增删工具定义。这里的重点是保持缓存前缀稳定,而不是某个固定的接口 schema。换句话说,真正值得记住的是设计原则:
- 尽量稳定工具定义
- 把“发现工具”变成一次显式操作
- 不要让工具列表频繁变化,破坏缓存收益
5.2 声明式工具:把边界变成可拦截、可审计的动作
原文强调,某些操作值得被提升成声明式工具(declarative tools)。这样做的好处,不在于“工具更多”,而在于这些动作会拥有类型化参数,从而让代理框架可以对它们进行拦截、门控、渲染或审计。


图注:作者基于原文整理的声明式工具作用示意图。
原文给出的价值主要有三类:
- 安全边界:对不可逆或高风险操作进行用户确认或额外门控
- UX 呈现:把操作渲染成更清晰的界面交互,而不是纯文本往返
- 可观察性:由于参数是结构化的,框架更容易记录、追踪和重放操作
需要注意的是:原文讨论的是设计思想,没有给出固定的 JSON schema,也没有定义类似 requires_confirmation、render_as、risk_level 这样的标准字段。
5.3 Claude Code 的 auto-mode:重新思考安全边界的粒度
原文这里的表述更准确地说是:Claude Code 的 auto-mode(文章写作时处于 research mode),会在 bash 工具周围提供一层安全边界——由第二个 Claude 读取命令字符串并判断其是否安全。

图注:作者基于原文整理的 auto-mode 安全边界示意图。
从工程视角看,这一段最值得关注的不是某个具体实现,而是一个更大的信号:随着 Claude 自身能力增强,一些原本必须依赖专用工具或外部控制逻辑的边界,可能会被重新内化到更灵活的代理框架里。
六、实践指南:构建生产级 Claude 应用的清单
基于三大模式,以下是构建 Claude 应用时的工程决策清单:
6.1 工具设计清单
✅ 优先使用 Claude 深度理解的通用工具(Bash、文本编辑器)
✅ 提供代码执行环境让 Claude 编排多步骤操作
✅ 将安全敏感操作封装为声明式工具
✅ 为动态工具集使用工具搜索而非动态注册
❌ 避免为每种操作创建专用工具
❌ 避免所有工具输出都流经上下文窗口
6.2 上下文管理清单
✅ 使用技能系统(Skills)按需加载上下文
✅ 实现上下文编辑,移除过期/无关信息
✅ 对长期任务启用压缩策略
✅ 提供记忆文件夹用于跨会话持久化
✅ 为独立子任务分叉子代理
❌ 避免将所有指令硬编码在系统提示中
❌ 避免无限增长的上下文窗口
6.3 成本优化清单
✅ 遵循"静态优先,动态最后"的请求结构
✅ 用消息追加而非编辑系统提示
✅ 会话内保持同一模型
✅ 固定工具定义,使用工具搜索处理动态需求
✅ 多轮应用中移动缓存断点
❌ 避免会话中途切换模型
❌ 避免频繁修改工具列表
七、前瞻:持续进化的应用架构
7.1 “上下文焦虑"的启示
文章提到了一个引人深思的案例:
- Sonnet 4.5 在感知到上下文限制接近时,会提前结束任务——团队称之为"上下文焦虑”
- 为了应对这个问题,开发团队添加了上下文重置(Context Reset) 机制来清除上下文窗口
- 当 Opus 4.5 发布后,这种行为完全消失了——之前为补偿不足而构建的上下文重置,反而成了代理框架中的**“死重”(Dead Weight)**
7.2 动态修剪架构
这个案例揭示了一个重要的工程原则:
随着模型能力的每一次飞跃,你需要重新测试"Claude 不能做什么"的假设。应用中的结构或边界应该基于这个问题持续修剪:“我可以停止做什么?”

这意味着 Claude 应用的架构不是一次性设计的静态产物,而是一个需要持续修剪的活文档:
- 定期基准测试:每次模型升级后,重新测试所有辅助机制的必要性
- 可拆卸设计:每个架构组件都应该可以独立移除
- A/B 测试:在生产环境中对比有/无特定组件的效果
- 成本-收益审计:量化每个组件的延迟/成本开销与智能提升
八、总结
Anthropic 这篇博客传递的核心信息可以凝练为一句话:
最好的 Claude 应用是那些知道何时放手的应用。
三大模式的本质:
| 模式 | 核心问题 | 设计哲学 |
|---|---|---|
| 使用 Claude 已知的能力 | 用什么工具? | 少即是多:通用工具 > 专用工具 |
| 停止做不必要的事 | 控制什么? | 让 Claude 自主:减少外部编排 |
| 精准设置边界 | 约束什么? | 精准干预:只在安全/UX/成本需要时介入 |
随着 Claude 从 Sonnet 3.5 进化到 Opus 4.6,我们看到的不仅是基准分数的提升,更是一种根本性的范式转变:从"我如何让 AI 做正确的事"到"我如何停止阻碍 AI 做正确的事"。
对于开发者而言,最重要的实践是建立一个持续评估循环:每次模型能力升级后,重新审视你的假设、测试你的辅助机制、修剪不再需要的控制结构。你的代理框架应该随着 Claude 的成长而变得更简洁,而不是更复杂。
参考资源:原文最后提到,可查看
claude-apiskill,以使用文中讨论的工具和模式。
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
