一、引言:当 16 个 AI 代理组成一支编译器开发团队
原文链接:Building a C compiler with a team of parallel Claudes 作者:Nicholas Carlini(Anthropic Safeguards 团队研究员) 项目源码:github.com/anthropics/claudes-c-compiler
如果有人告诉你:一个人指挥 16 个 AI 代理,用不到一个月的时间,从零写出了一个可以编译 Linux 内核的 C 编译器——你的第一反应可能是 “这也太夸张了吧”。但 Anthropic 研究员 Nicholas Carlini 确实做到了。

这个项目的最终成果:
| 指标 | 数据 |
|---|---|
| 代码量 | 100,000 行 Rust |
| Claude Code 会话数 | ~2,000 次 |
| 输入 Token | 20 亿 |
| 输出 Token | 1.4 亿 |
| API 成本 | ~$20,000 |
| 目标架构 | x86、ARM、RISC-V |
| 核心成果 | 可编译 Linux 6.9 内核并启动 |
| 额外验证 | 可编译 QEMU、FFmpeg、SQLite、PostgreSQL、Redis |
但 Carlini 反复强调:这篇文章的重点不在于编译器本身,而在于背后"代理团队"(Agent Teams)的工程方法论。这是一次关于"如何设计让多个自主 AI 代理长时间并行协作"的压力测试。
本文导读
- 第二节 拆解单代理如何实现"永不停歇"的自主循环
- 第三节 分析多代理并行的核心难题与同步算法
- 第四节 总结代理团队编程中的实战经验
- 第五节 评估项目成果与已知局限
- 第六节 展望代理团队模式的未来与风险
二、启用长期运行的自主代理:从工具到自主循环
2.1 问题:现有框架的天花板
当前的 AI 编程助手(包括 Claude Code 自身)主要面向人机协作场景:人类提出任务、AI 执行、人类审核、AI 调整。这种工作模式下,AI 的产出上限取决于人类的带宽。

如果要让 AI 自主完成一个大型项目,就必须打破这个"人在循环中"的限制。
2.2 解决方案:无限循环驱动
Carlini 的核心思路极其简单——把 Claude 放进一个 Bash 无限循环里:
#!/bin/bash
while true; do
COMMIT=$(git rev-parse --short=6 HEAD)
LOGFILE="agent_logs/agent_${COMMIT}.log"
claude --dangerously-skip-permissions \
-p "$(cat AGENT_PROMPT.md)" \
--model claude-opus-4-0-20250514 &> "$LOGFILE"
done
⚠️ 安全提醒:
--dangerously-skip-permissions跳过了所有权限检查。Carlini 强烈建议在 Docker 容器 中运行此脚本,而不是在裸机上。
这段代码的运行逻辑如下:

关键设计决策:每次循环迭代都是一个全新的 Claude Code 会话。这意味着:
- 上下文窗口自动刷新:不会因为长时间运行导致上下文窗口被历史信息填满
- 自动从最新状态恢复:每次启动时读取
AGENT_PROMPT.md,Claude 重新评估当前代码状态 - 天然的故障恢复:如果某次会话崩溃,循环会自动启动新会话继续工作
2.3 Agent Prompt 的设计哲学
AGENT_PROMPT.md 是整个系统的"灵魂"。它不是简单的任务列表,而是一套自主决策框架:
# 你是一个编译器开发者
你正在开发一个用 Rust 编写的 C 编译器。
## 工作方式
1. 查看 `current_tasks/` 目录,了解当前待办事项
2. 选择一个你能解决的任务
3. 将问题分解为小步骤
4. 每完成一步就提交代码并运行测试
5. 如果所有任务都完成了,检查是否有新的可优化点
6. 持续工作,直到没有更多改进空间
## 原则
- 每次修改后都要运行测试
- 不要破坏已有功能
- 优先修复回归问题
- 保持代码整洁
这种设计让 Claude 具备了自主规划能力:它不仅执行预定义任务,还能在完成已知任务后主动发现新的改进点。
三、并行运行多个 Claude 代理:从单兵到团队
3.1 为什么需要并行?
单一代理循环虽然可以持续工作,但存在两个根本性限制:

3.2 并行架构设计
Carlini 的方案架构清晰:

每个代理运行在独立的 Docker 容器中,拥有自己的代码工作副本。代理之间不直接通信——它们通过 Git 仓库进行间接协调。
3.3 任务锁定与同步算法
多个代理并行修改同一代码库,最大的挑战是冲突管理。Carlini 设计了一个优雅的基于 Git 的同步算法:

这个设计的巧妙之处在于利用了 Git 自身的并发控制机制:
- 乐观锁:两个代理同时尝试锁定同一任务时,先 push 成功的获得锁,后者会因为 push 冲突而自动放弃
- 无需额外协调服务:不需要 Redis、数据库或消息队列,Git 本身就是同步原语
- 容错性:即使某个代理崩溃,锁文件不会永久存在(其他代理可以在超时后清理)
3.4 完整的代理生命周期
把循环、同步和任务管理结合起来,一个代理的完整生命周期如下:

四、代理团队编程的实战经验
这一节是 Carlini 文章中最具实操价值的部分。以下经验来自近 2,000 次 Claude Code 会话的积累。
4.1 编写极致高质量的测试
核心原则:Claude 会自主解决你给出的任何问题,因此问题的定义(测试)必须几乎完美。
在人机协作模式下,人类可以通过审查代码来弥补测试的不足。但在自主代理模式下,测试是唯一的质量看门人。

Carlini 的应对策略:
- 构建 CI 管道:当 Claude 频繁破坏已有功能时,实施持续集成,每次提交都运行完整测试套件
- 执行规则升级:在 Agent Prompt 中加入更严格的约束(如"必须先运行全量测试再提交")
- 测试覆盖率警戒:确保关键路径有充分的测试保护
4.2 设身处地为 Claude 设计
测试框架是为 Claude 写的,不是为人类。这个认知转变带来了几个重要的设计调整:
上下文窗口污染问题

- 输出控制:测试框架不应该向 stdout 输出大量无用字节。关键信息应写入文件,让 Claude 按需读取
- 摘要优先:测试结果应先展示失败计数和关键错误,而非完整堆栈
时间盲区问题
Claude 没有时间概念——它不知道一个测试运行了 3 秒还是 3 小时。Carlini 的解决方案:
# 默认运行 1% 的随机测试样本(快速检测回归)
./run_tests.sh --fast
# 完整测试(仅在 CI 中运行)
./run_tests.sh --full
--fast 模式让 Claude 能在几秒内判断自己的修改是否引入了回归,而不需要等待完整测试套件运行完毕。
4.3 让并行化变得容易
理想场景:有 100 个不同的失败测试 → 每个代理负责修复不同的测试 → 自然并行。
困难场景:编译 Linux 内核时,所有代理都遇到同一个编译错误 → 大家挤在同一个问题上 → 并行退化为串行。
Carlini 的创新解决方案——GCC 作为预言机的随机分割策略:

这个方法的精妙之处:
- 用 GCC 作为"已知正确"的基准,保证内核整体可编译
- 随机选择一小部分文件用 Claude 的编译器编译,每次选择不同的文件
- 每个代理看到不同文件中的不同错误,自然实现并行化
- 渐进式覆盖:随着错误被修复,越来越多的文件可以切换到 Claude 编译器
4.4 多角色代理分工
并行化不仅是"多个代理做同样的事",更重要的是专业化分工:

每种角色的 Agent Prompt 不同,确保它们关注的视角和产出也不同。
五、编译器成果与能力评估
5.1 最终成果
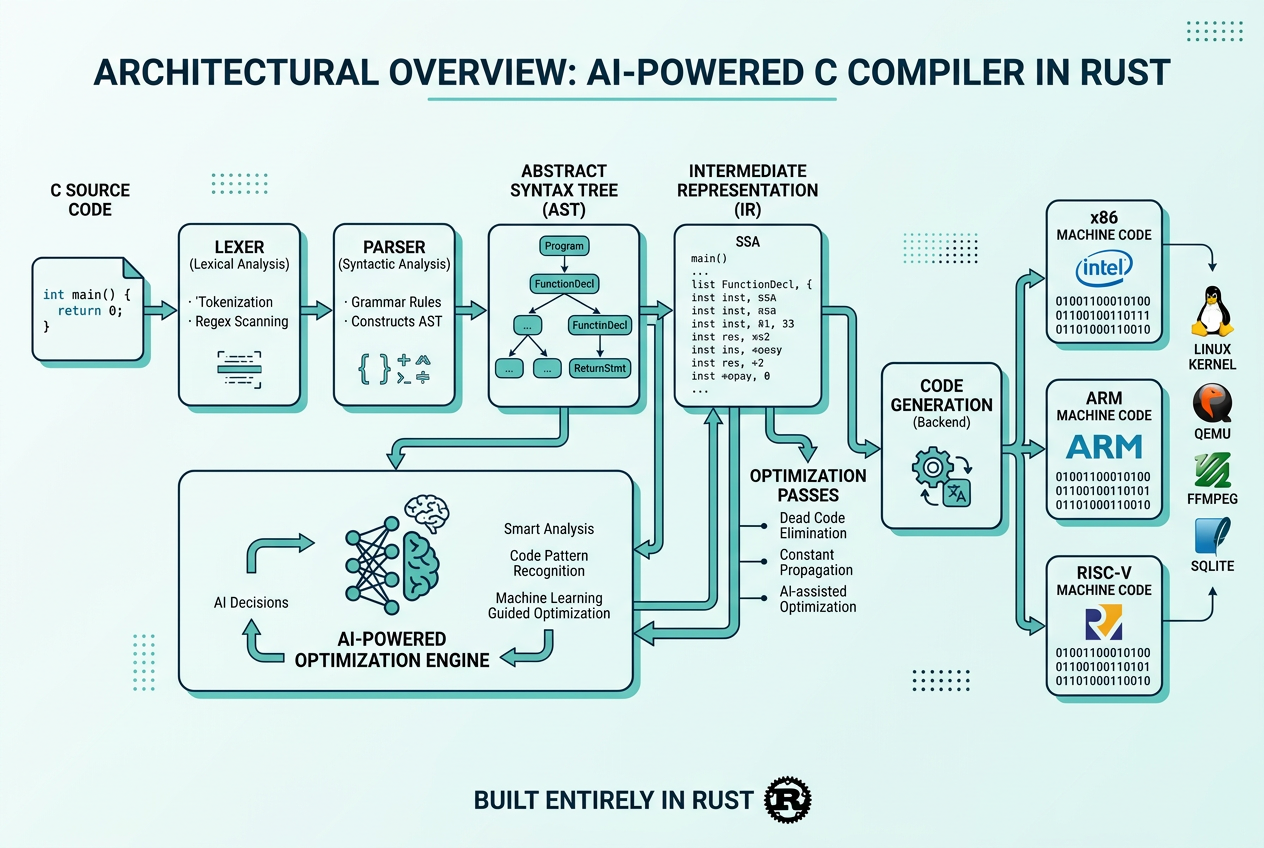
这个纯 AI 编写的编译器(“净室实现”——开发过程中 Claude 没有互联网访问,仅依赖 Rust 标准库)取得了令人印象深刻的成果:
| 能力维度 | 具体成果 |
|---|---|
| Linux 内核编译 | 可构建 Linux 6.9 并成功启动(x86、ARM、RISC-V) |
| 大型项目编译 | QEMU、FFmpeg、SQLite、PostgreSQL、Redis |
| 测试通过率 | 大多数编译器测试套件 99% 通过 |
| 彩蛋 | 可以编译并运行 Doom 🎮 |
| 代码实现 | 净室实现,仅依赖 Rust 标准库 |
5.2 已知局限
Carlini 非常坦诚地列出了编译器的不足:

特别值得注意的是:
- 16 位 x86 问题:Opus 模型无法实现 16 位 x86 代码生成器来启动进入实模式。因此在 x86 架构上,引导阶段仍调用 GCC(ARM 和 RISC-V 架构则完全由 Claude 编译器编译)
- 生成代码效率:编译器开启所有优化后,生成的代码效率仍低于 GCC 关闭所有优化(
-O0)的水平——这说明当前 LLM 在底层性能工程方面仍有明显差距
5.3 成本效益分析

一些有趣的对比思考:
- $20,000 的成本大约等于一位中级 Rust 开发者 1-2 周 的薪资(美国市场)
- 但一位人类开发者不太可能在 1-2 周内从零写出 10 万行可编译 Linux 内核的编译器
- 当然,人类开发者写出的代码质量、性能和可维护性可能远优于 AI 的产出
六、代理团队模式的工程启示
6.1 对软件工程的影响
Carlini 的实验揭示了一种全新的软件开发范式——人类从"编码者"转变为"架构师和测试设计师":

关键角色转变:
- 测试设计 > 代码编写:你的测试质量直接决定了 AI 代码的质量
- 架构设计 > 实现细节:人类负责定义"做什么"和"怎么验证",AI 负责"怎么做"
- 提示词工程 = 管理艺术:编写 Agent Prompt 本质上是在"管理"一支 AI 团队
6.2 安全与风险思考
Carlini 在文章结尾表达了一种谨慎的不安:
“当人类与 Claude 并肩开发时,可以确保质量和实时捕获错误。但对于自主系统,很容易看到测试通过就认为工作完成了。作为一个曾经从事渗透测试的人,想到程序员部署从未亲自验证过的软件,这是一个真正的担忧。”
这段话点出了自主代理编程的核心风险:

- 测试覆盖率幻觉:99% 测试通过率可能掩盖了剩余 1% 中的严重问题
- 安全盲区:AI 可能不会主动考虑安全攻击向量
- 架构腐化:长时间自主运行可能导致代码结构逐渐劣化
6.3 可复用的工程模式
从 Carlini 的实验中,可以提炼出一套可复用的代理团队框架:

核心原则总结:
| 原则 | 说明 |
|---|---|
| Git 即协调 | 用 Git 的并发控制替代复杂的分布式协调服务 |
| 测试即管理 | 测试套件是"管理" AI 团队的最重要工具 |
| 容器即安全 | 每个代理在独立容器中运行,限制爆炸半径 |
| 循环即韧性 | 无限循环 + 新会话 = 天然故障恢复 |
| 角色即效率 | 专业化分工比通用代理更高效 |
| 预言机即标准 | 用已知正确的参考实现作为比较基准 |
七、总结与展望
这个实验证明了什么?
- LLM 已具备构建复杂系统的能力:10 万行代码、三种指令集架构、可编译 Linux 内核——这不是"玩具项目"
- 并行代理团队是可行的:通过简单的 Git 同步和任务锁定,16 个代理可以有效协作
- 人类角色正在转变:从"写代码"变为"写测试"和"设计架构"
- 自主≠无风险:测试通过不等于正确,人类审查仍不可或缺
哪些问题仍待解决?
- 代码质量天花板:AI 生成的 Rust 代码质量远不如人类专家
- 性能工程:AI 在底层优化(如寄存器分配、指令调度)上仍有明显差距
- 安全保证:缺乏有效的方法来验证 AI 自主编写的代码不含安全漏洞
- 成本可控性:$20,000 的实验成本对大多数团队来说仍然不菲
如何看待这项技术的未来?
用 Carlini 自己的话说:
“每一代语言模型都开辟了新的工作方式。积极的应用将超过消极的影响,但我们需要新的策略来安全地应对这个新世界。”
代理团队模式不会取代人类程序员,但它正在重新定义"编程"这件事的含义。未来的软件工程师可能更像建筑师而非砌砖工——负责设计蓝图和质量标准,让 AI 团队去完成具体的实现。
参考资料
- Building a C compiler with a team of parallel Claudes - Anthropic Engineering
- Claude’s C Compiler - GitHub
- Claude Code - Anthropic
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
