一、引言:它解决的不是“召回算法不够强”,而是“Chunk 天生难检索”
在 RAG 讨论里,大家很容易把注意力放在更强的 embedding、更复杂的 reranker,或者 query rewriting 这类检索侧优化上。但 Anthropic 这篇文章真正提醒我们的,是另一个更靠前的问题:很多检索失手,不是因为召回算法太弱,而是因为文档在切块之后,已经不再像一个容易被检索的知识单元。
如果一个 chunk 里只剩下“公司收入增长了 3%”这样的句子,那么无论是向量检索还是 BM25,面对的都是一个语义不完整、定位信息不足的对象。系统后面的检索链路再精细,也只能在这个残缺输入上做优化。
Contextual Retrieval 的价值就在这里。它不直接修改 RAG 的主流程,也不试图发明一种全新的召回算法,而是在索引之前先做一件事:把 chunk 在切分时丢掉的最小必要语境补回来。
本文重点回答三个问题:
- Contextual Retrieval 到底解决了什么问题?
- 它在工程上是怎样落地的?
- 为什么它能在不大改 RAG 架构的前提下,把检索失败率继续往下压?
1.1 传统 RAG 的根本痛点
检索增强生成(Retrieval-Augmented Generation,RAG)是当前大模型应用里最常见的系统形态之一。它通过从外部知识库中检索相关信息,为模型补充事实依据,再让模型基于这些信息生成回答。
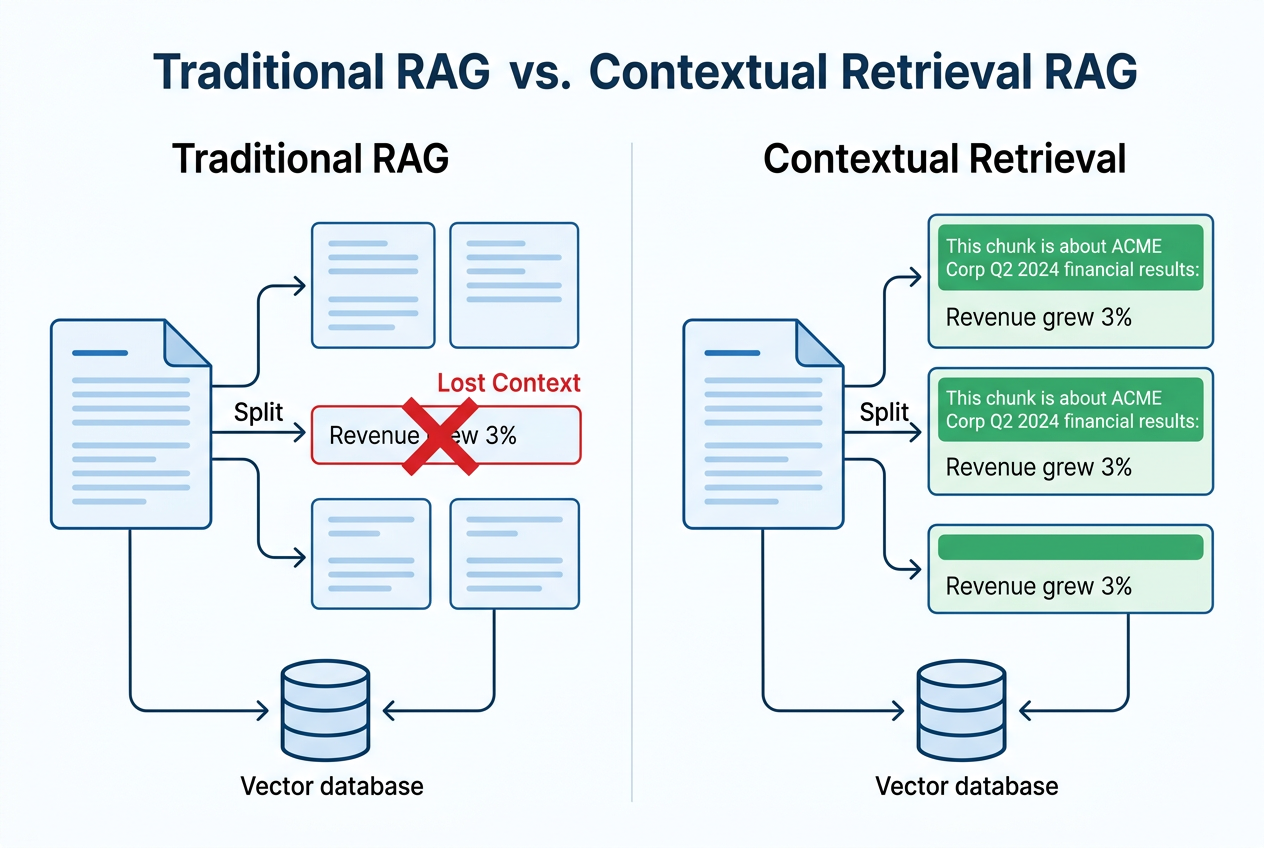
问题也出在这里。传统 RAG 通常先把文档切成很多文本块,再分别做向量化和索引。这样做便于存储和召回,但副作用很明显:chunk 一旦脱离原文,它就很容易失去“自己在说什么、属于哪一段、和谁相关”的关键信息。
举个很典型的例子:
某份财报里有一句话:“公司收入增长了 3%"。
这句话单独切出来以后,立刻就会变得含糊:是哪家公司?哪个季度?同比还是环比?当用户查询“ACME 公司 2024 年 Q2 收入增长情况”时,传统 RAG 很可能检不到这个 chunk,不是因为这句原文没价值,而是因为它被切出来以后,已经不够“可检索”了。
1.2 Anthropic 给出的办法
2024 年 9 月,Anthropic 工程团队在 Introducing Contextual Retrieval 一文里给出了一个很工程化的思路:在做嵌入和建索引之前,先让模型阅读整篇文档,再为每个 chunk 生成一段简短说明,用来交代它在全文里的位置、主题和关联对象。
随后,把这段说明拼到原始 chunk 前面,再送去做 embedding 和 BM25 索引。这样一来,检索系统面对的就不再是“脱离上下文的碎片”,而是“带着最小语境的知识单元”。
这个思路听上去不复杂,但效果非常直接。按照 Anthropic 在原文中的评测,Contextual Retrieval 结合 reranking 之后,检索失败率最高可以下降 67%。
二、核心原理
2.1 核心思想
Contextual Retrieval 的核心思想可以用一句话概括:
让大模型阅读整篇文档,为每个文本块生成一段简短的、特定于该块的上下文说明,然后将这段说明拼接到原始文本块前面,再进行向量化和索引。
这段上下文说明通常为 50-100 tokens,包含了该文本块在文档中的定位信息,例如所属章节、讨论主题、关联的实体名称等。
2.2 两个子技术
Contextual Retrieval 包含两个相互配合的子技术:
| 子技术 | 说明 | 作用 |
|---|---|---|
| Contextual Embeddings | 在生成向量嵌入之前,为文本块添加上下文 | 提升语义检索精度 |
| Contextual BM25 | 在创建 BM25 索引之前,为文本块添加上下文 | 提升关键词检索精度 |
两者的组合,使得无论是语义检索还是关键词检索,都能受益于上下文的补充。
2.3 上下文生成 Prompt
Anthropic 提供了一个通用的上下文生成 Prompt 模板:
<document>
{{WHOLE_DOCUMENT}}
</document>
Here is the chunk we want to situate within the whole document:
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk within
the overall document for the purposes of improving search retrieval
of the chunk. Answer only with the succinct context and nothing else.
该 Prompt 的设计非常精妙:
- 输入整篇文档作为全局上下文
- 指定目标文本块
- 要求模型生成简短、精炼的定位说明
- 明确限制输出只包含上下文说明,不含其他内容
三、系统架构
3.1 整体架构
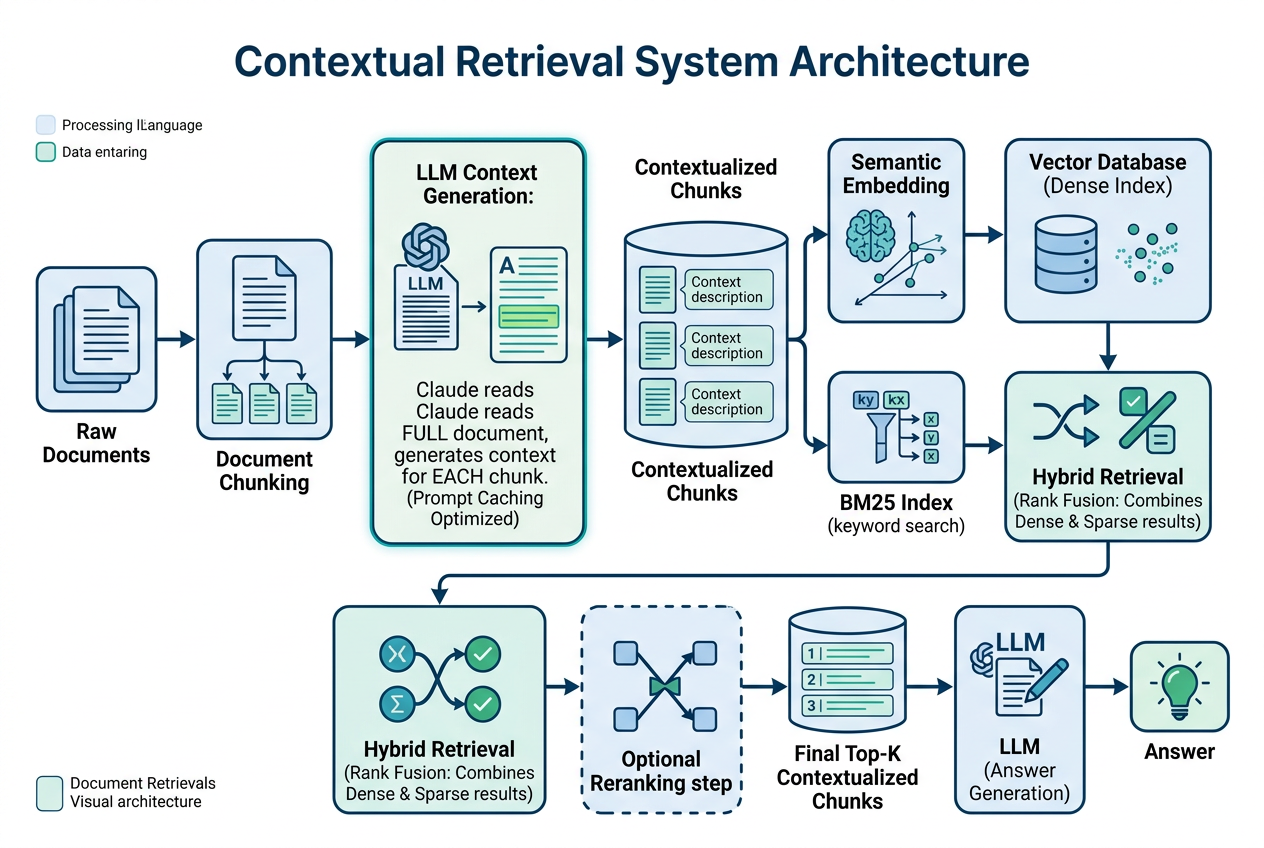
Contextual Retrieval 是一种预处理技术,其核心创新在于索引阶段,而非检索阶段。完整的系统架构如下:
3.2 架构分层详解
第一层:输入层(Raw Documents)
原始文档集合,可以是技术文档、法律合同、医疗记录、代码库等各种类型的文本数据。
第二层:预处理层(核心创新)
这是 Contextual Retrieval 的关键步骤,主要分成三段:
Step 1 - 文档切分(Chunking)
将文档分解为较小的文本块,通常每个块包含几百个 token。切分策略需要考虑:
- 块大小(chunk size)
- 重叠度(overlap)
- 边界对齐(paragraph/sentence boundaries)
Step 2 - 上下文生成(Context Generation)
接着,使用大模型(如 Claude 3 Haiku)为每个文本块生成一段简短的定位说明。下面的代码只是示意这一过程的伪代码,真实实现里通常还会包含缓存命中、重试和批处理逻辑:
def generate_context(whole_document: str, chunk: str) -> str:
prompt = f"""
<document>
{whole_document}
</document>
Here is the chunk we want to situate within the whole document:
<chunk>
{chunk}
</chunk>
Please give a short succinct context to situate this chunk
within the overall document for the purposes of improving
search retrieval of the chunk.
Answer only with the succinct context and nothing else.
"""
return llm.generate(prompt)
Step 3 - 上下文拼接(Context Prepending)
最后,把生成的上下文前置到原始文本块:
contextualized_chunk = f"{generated_context}\n\n{original_chunk}"
实际工程里,除了拼接后的文本本身,通常还会保留原 chunk 的 metadata,用于后续排序、溯源和结果展示。
第三层:存储/索引层
经过上下文化处理后的文本块,同时进入两个索引通道:
- 向量数据库:存储经过 Contextual Embeddings 处理的语义向量
- BM25 索引:存储经过 Contextual BM25 处理的词频统计
第四层:检索层(Hybrid Retrieval)
采用双路召回 + 排序融合策略:
- 语义检索:基于向量相似度,召回语义相关的文本块
- 关键词检索(BM25):基于精确词汇匹配,召回包含关键词的文本块
- Rank Fusion:使用排序融合算法(如 RRF)合并去重两路结果
- Reranking(可选):使用重排序模型(如 Cohere Reranker)对 Top-N 结果精排,选出 Top-K
第五层:生成层
将最终检索到的 Top-K 文本块注入 Prompt,供大模型生成最终答案。
四、关键优化:Prompt Caching
4.1 成本挑战
Contextual Retrieval 需要为每个文本块读取整篇文档来生成上下文。对于一篇包含数百个文本块的长文档,这意味着同一份文档需要被反复发送给大模型,产生巨大的 token 消耗。
4.2 Prompt Caching 解决方案
Anthropic 用 Prompt Caching 解决了这个问题:
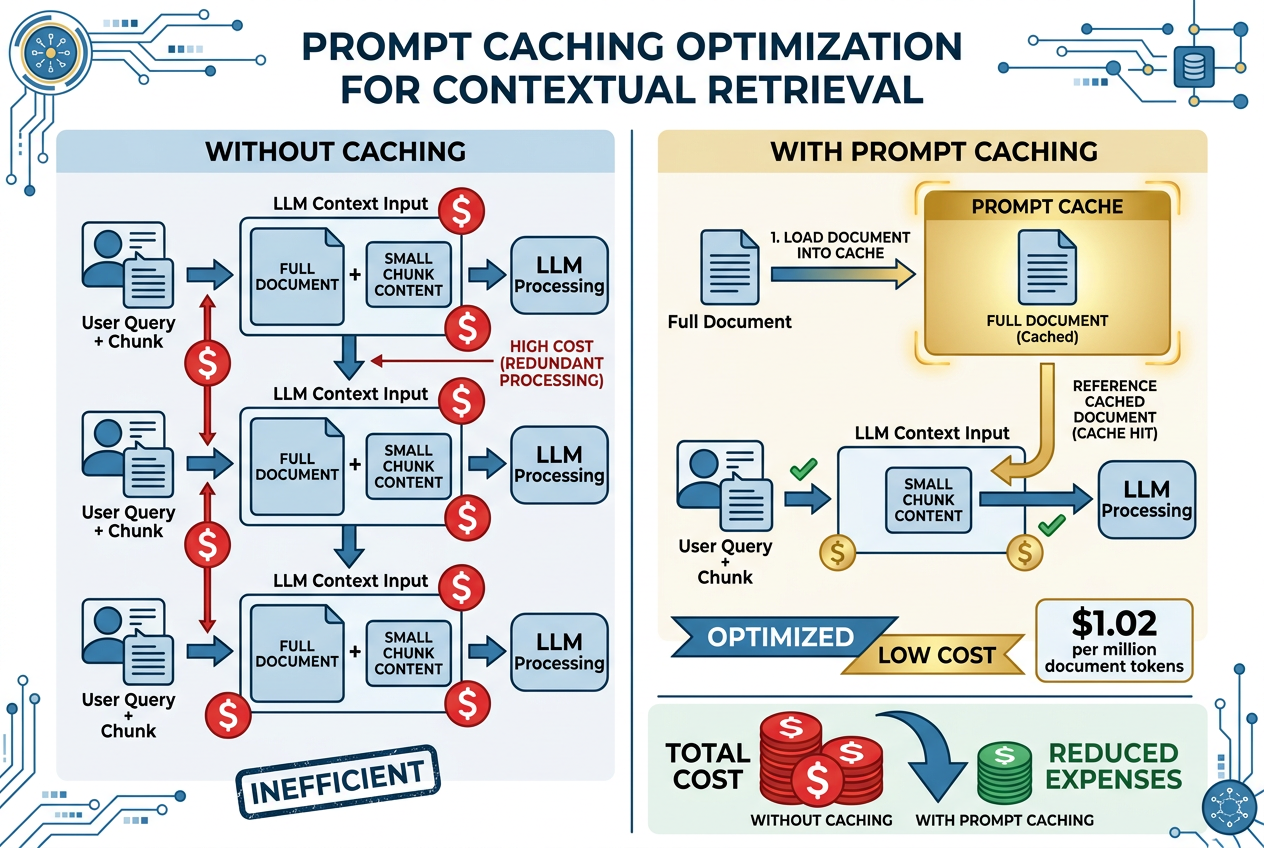
它的工作方式可以概括成三步:
- 首次请求:先把完整文档加载到 Prompt Cache 中
- 后续请求:处理同一文档的各个 chunk 时,直接引用缓存中的文档内容,只传新的 chunk
- 结果:避免反复传输整篇文档,预处理成本显著下降
4.3 成本估算
Anthropic 在原文中给出的经验值是:在结合 Claude 3 Haiku 与 Prompt Caching 的实现假设下,生成上下文化文本块的一次性预处理成本大约为:
每百万文档 token 约 1.02 美元
这个数字更适合被理解为当时方案下的成本估算,而不是一个对所有模型、语料规模和部署条件都成立的固定价格。
五、性能评估
5.1 实验设置
Anthropic 在多个领域进行了广泛测试,覆盖了:
- 代码库(Codebase)
- 小说(Fiction)
- ArXiv 论文
- 科学论文(Science Papers)
评估指标为 Recall@20 的补数(1 - Recall@20),即检索失败率——在 Top-20 结果中未能找到相关文档的比例。该值越低,检索效果越好。
5.2 性能对比
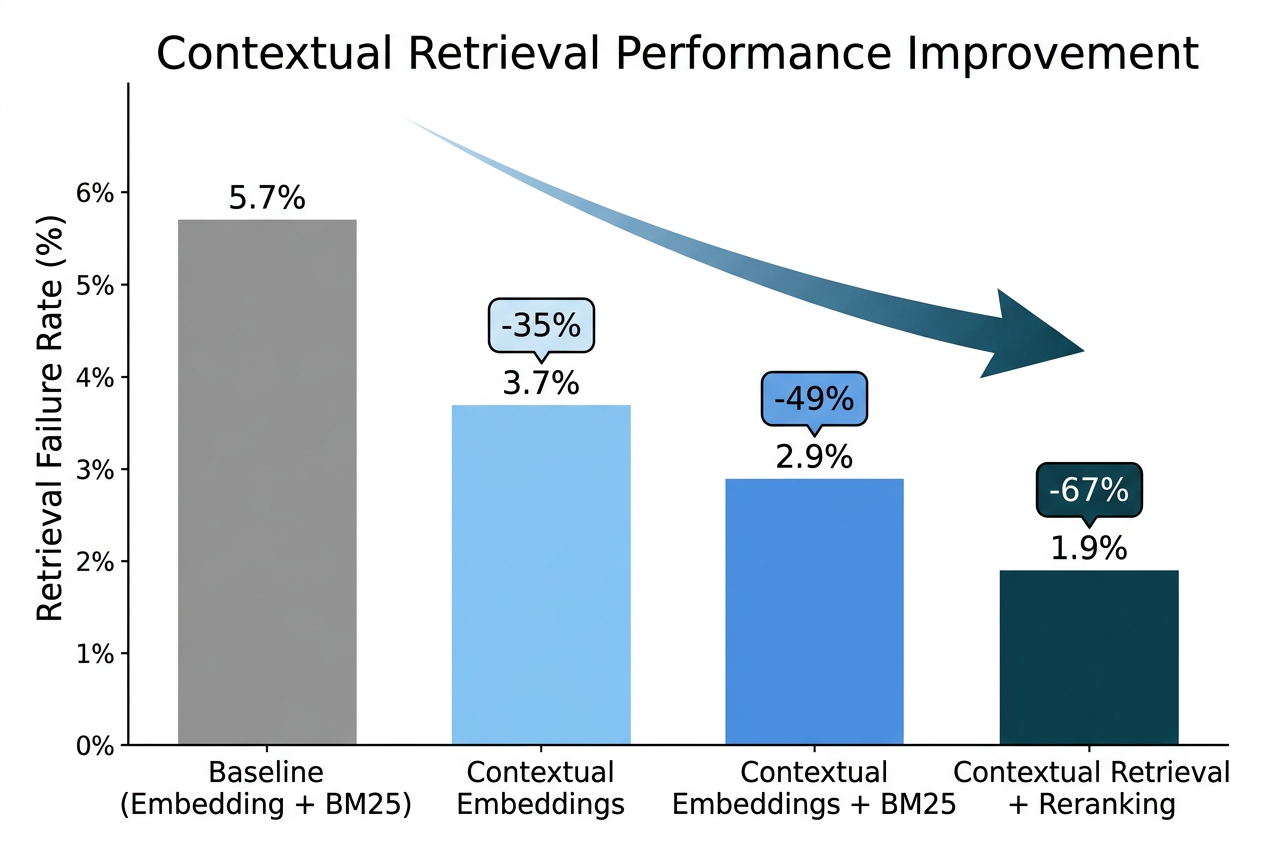
具体数据如下:
| 方法 | 检索失败率 | 相比基线提升 |
|---|---|---|
| 基线(Embedding + BM25) | 5.7% | — |
| Contextual Embeddings | 3.7% | ↓ 35% |
| Contextual Embeddings + Contextual BM25 | 2.9% | ↓ 49% |
| Contextual Retrieval + Reranking | 1.9% | ↓ 67% |
5.3 关键发现
- 效果可以叠加:BM25、上下文化处理和 reranking 的收益不是互斥关系,组合使用时效果最好。
- Top-K 不宜取得太小:Anthropic 的测试表明,把 Top-20 chunk 交给模型通常优于只给 Top-10 或 Top-5。
- 嵌入模型仍然重要:在他们的实验里,Voyage 和 Gemini 的 embedding 模型表现更突出,但最终结果仍会受到语料类型、chunk 策略和 reranking 配置影响。
- Contextual BM25 不是陪衬:失败率从 3.7% 继续降到 2.9%。如果按失败率计算,相当于在 Contextual Embeddings 的基础上又额外下降了约 21.6%;如果按相对基线的总改进幅度来描述,则总降幅从 35% 扩大到了 49%,多了 14 个百分点。
六、实践指南
6.1 适用场景
Contextual Retrieval 特别适用于以下场景:
| 场景 | 说明 |
|---|---|
| 大型知识库 | 超过 200,000 tokens(约 500 页)的内容,无法直接放入上下文窗口 |
| 高精度检索 | 客户支持机器人、法律分析助手、医疗问答系统等 |
| 技术文档查询 | 涉及特定错误代码、ID 或专业术语的场景,BM25 和上下文化结合后通常更稳 |
6.2 实施建议
1. 小数据集不一定值得上
如果知识库小于 200,000 tokens,很多时候直接利用 Prompt Caching 把整个知识库放进上下文就够了,未必需要再搭一套 RAG。
2. 先把切分策略定稳
真正影响效果的,往往不只是 embedding 模型本身,还包括:
- 块大小(建议 200-500 tokens)
- 重叠度(10-20%)
- 边界对齐方式(优先贴近段落或句子边界)
3. 上下文生成 Prompt 可以按领域定制
如果文档里有很多专业缩写、实体名或隐含背景,最好把这些信息提前写进 Prompt。对金融、法律、代码库这类专业语料来说,这一步通常比“泛化 Prompt”更稳。
<document>
{{WHOLE_DOCUMENT}}
</document>
<domain_context>
This is a financial earnings report. Key terms include:
- YoY: Year over Year
- QoQ: Quarter over Quarter
- EBITDA: Earnings Before Interest, Taxes, Depreciation, Amortization
</domain_context>
<chunk>
{{CHUNK_CONTENT}}
</chunk>
Please give a short succinct context to situate this chunk...
4. 成本与延迟要分开看
| 环节 | 成本特征 | 说明 |
|---|---|---|
| 上下文生成 | 一次性成本 | 发生在文档入库阶段,结合 Prompt Caching 后通常可控 |
| 向量检索 | 低运行时成本 | 与传统 RAG 接近 |
| BM25 检索 | 低运行时成本 | 与传统 BM25 接近 |
| Reranking | 额外运行时成本 | 精度更高,但会带来额外延迟与调用成本 |
6.3 哪些场景不一定适合
并不是所有 RAG 系统都值得接入 Contextual Retrieval。至少下面几类场景,需要先算清楚账:
- 知识库很小:如果语料本来就能直接塞进上下文窗口,做 chunk 上下文化通常是多此一举。
- 语料更新非常频繁:Contextual Retrieval 的成本主要在入库前处理。如果文档变动极快,反复生成上下文和重建索引的代价会比较高。
- 数据本身高度结构化:对于表格、数据库记录、明确 schema 的业务数据,SQL、过滤检索或知识图谱往往更直接,不一定要先转成 chunk 再增强。
- 入库链路要求极强实时性:如果系统要求新文档秒级可检索,那么额外增加一次 LLM 上下文化步骤,可能会让索引延迟超出预算。
七、技术总结
7.1 核心优势
如果只看工程价值,我觉得 Contextual Retrieval 至少有三点值得记住:
第一,它确实在补传统 RAG 最容易漏掉的一块。
- 传统 RAG 的问题,经常不是“没做混合检索”,而是 chunk 在切分后已经失去足够语境。
- Contextual Retrieval 做的事很直接:先把这部分最小必要信息补回去,再让 embedding 和 BM25 发挥作用。
第二,它改动的位置很合适。
- 它主要发生在索引前处理阶段,不需要推翻现有 RAG 的检索与生成主流程。
- 如果系统本来就有向量库、BM25 和 reranking,接入成本通常比重写检索链路低得多。
第三,它不是只在单一语料上奏效。
- Anthropic 的实验覆盖了代码库、小说和论文等不同类型文档,说明这套方法不是只对某一类文本有效。
- 它和 BM25、Hybrid Search、Reranking 的关系也不是替代,而是可以叠加。
7.2 与其他技术的关系
Contextual Retrieval 不是用来替代现有 RAG 优化技术的。更准确地说,它是在把“被切碎以后不好检索的 chunk”先处理成“更适合被检索的 chunk”,然后再把这些结果交给原有链路:
| 技术 | 关系 | 说明 |
|---|---|---|
| 向量嵌入 | 增强 | 上下文化后的嵌入通常更容易保留实体、主题和章节定位信息 |
| BM25 | 增强 | 上下文化后的 chunk 往往包含更多可命中的关键词 |
| Hybrid Search | 兼容 | 很适合放进双路召回架构,和向量检索、BM25 一起工作 |
| Reranking | 叠加 | 上下文化改善召回输入,reranking 再做精排,两者收益通常可叠加 |
| Query Rewriting | 正交 | 一个改 query,一个改 chunk,本质上优化的是检索两端 |
7.3 展望
我更愿意把 Contextual Retrieval 看成一种很朴素、但很有启发性的思路:与其在检索阶段拼命补救,不如在索引阶段先把数据处理成更容易被检索的样子。
这件事说到底是在提醒我们,RAG 优化不只是“换一个更强模型”或者“多加一层排序器”。很多时候,问题就出在输入数据本身。顺着这个方向往下走,后面值得继续看的至少有几件事:
- 多模态文档的上下文化处理
- 跨文档的关联上下文生成
- 面向持续更新知识库的增量式上下文化机制
参考资料
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
