1 网络性能
1.1 网络协议层
ISO/OSI网络模型
应用层
表示层
会话层
传输层
网络层
链路层
物理层
TCP/IP模型
应用层 -> 应用上的协议有HTTP、DNS、FTP、POP3、SMTP、DHCP等
传输层 -> 传输的质量问题;是否面向连接,是否可靠; TCP/UDP
网络层 -> 打通底层所有网络(ip协议)
链路层 -> 解决不同网络拓扑结构导致的组网差异
物理层
TCP/IP模型实际上不负责物理层,默认已存在;
ARP协议位于哪一层?
在OSI模型中ARP协议属于链路层, 而在TCP/IP模型中,ARP协议属于网络层; 个人觉得ARP协议介于网络层和链路层之间
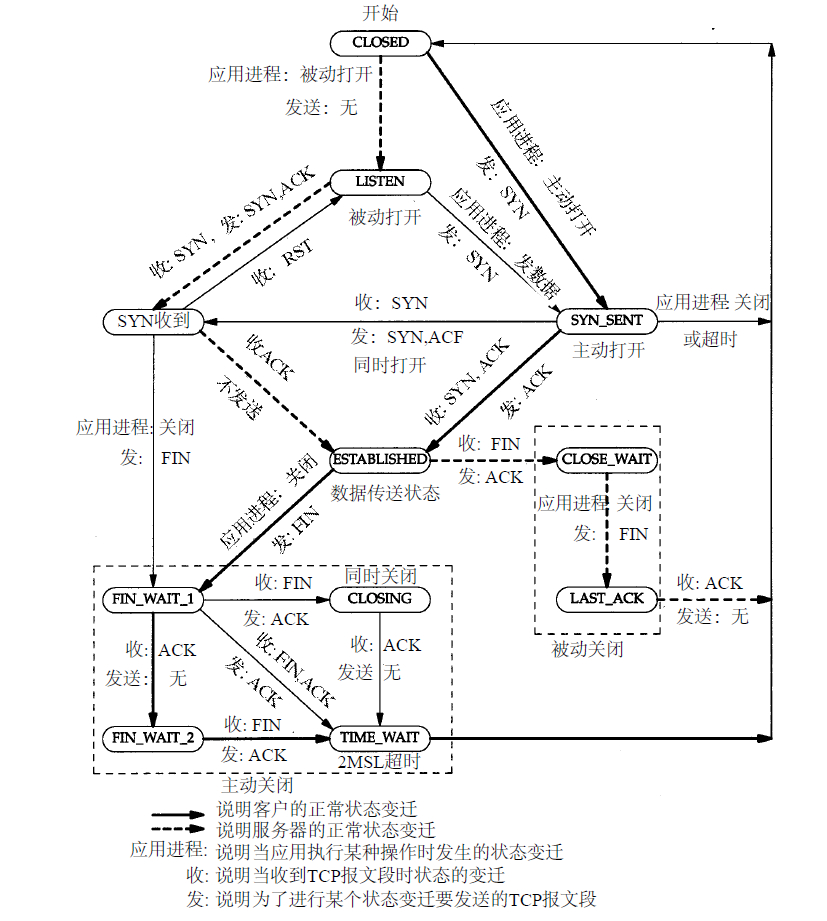
TCP/IP三次握手、四次挥手
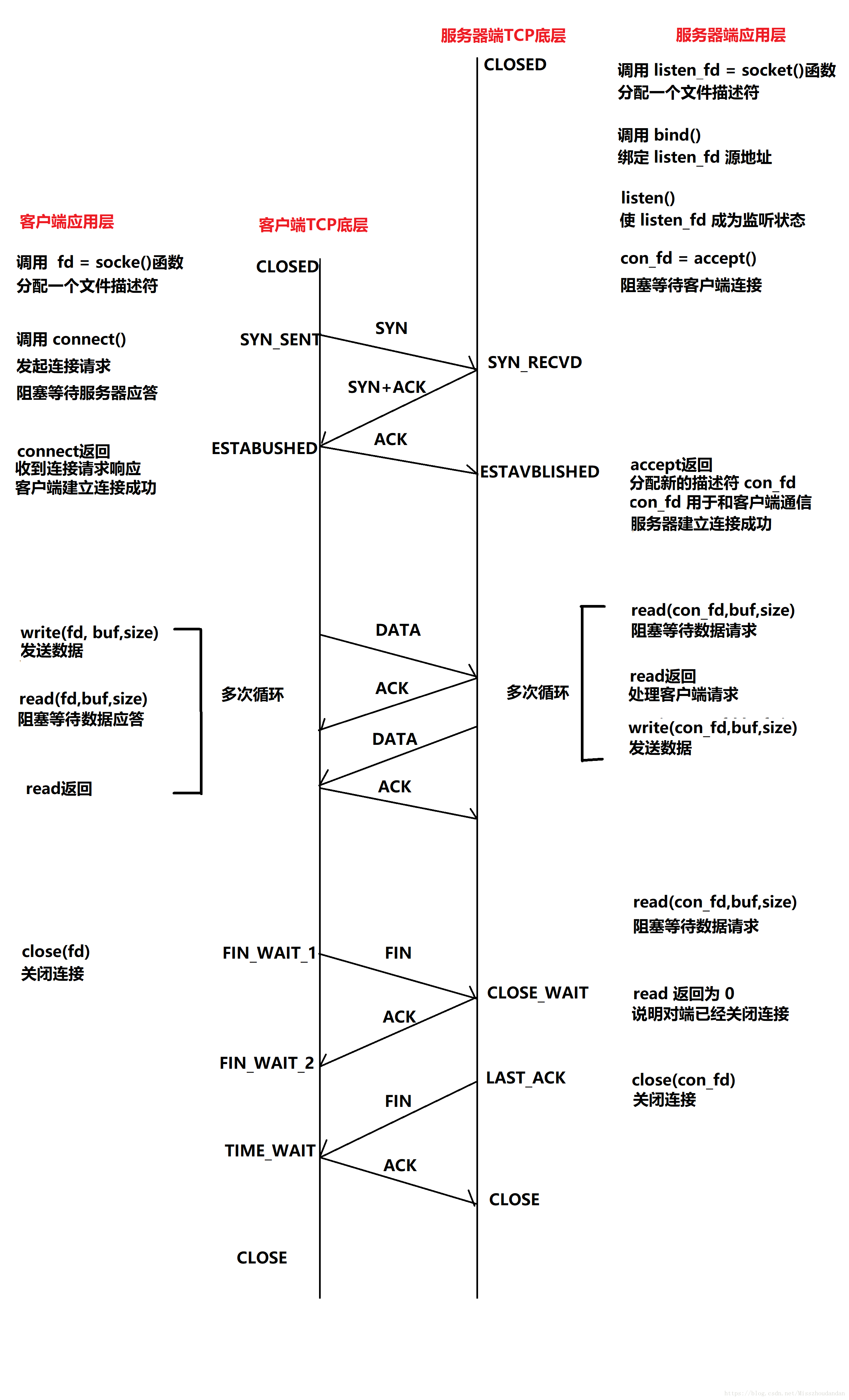
TCP/IP状态相互转化:
1.2 网络常用监控命令
unix网络三套件:netstat、ifconfig、route(net-tools包提供)
linux 内核2.4之后使用了iproute2,iproute2提供了一套可实现相同功能的新命令:ss、ip; 这套命令基于内核新模块实现,查询更高效.
1.2.1 netstat
netstat本质上用于显示socket状态,stat系列命令还有iostat、mpstat、vmstat
-a:所有socket连接 -n:不把IP反解析成域名 -t:TCP -p: 打印进程号
# netstat -antp
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
tcp 0 0 0.0.0.0:443 0.0.0.0:* LISTEN 9736/kube-proxy
tcp 0 0 0.0.0.0:5340 0.0.0.0:* LISTEN 9736/kube-proxy
tcp 0 0 0.0.0.0:17917 0.0.0.0:* LISTEN 9736/kube-proxy
# netstat -anup
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
udp 0 0 0.0.0.0:45176 0.0.0.0:* 22752/sap1015
udp 0 0 0 0.0.0.0:38712 0.0.0.0:* 22752/sap1015
显示协议栈里面比较重要的计数器
# netstat -s
Ip:
2632962443 total packets received
1168756774 forwarded
0 incoming packets discarded
1464185243 incoming packets delivered
2642503480 requests sent out
30 dropped because of missing route
Icmp:
46084310 ICMP messages received
20100 input ICMP message failed.
ICMP input histogram:
destination unreachable: 37132827
timeout in transit: 1
echo requests: 8951025
echo replies: 321
timestamp request: 136
45534912 ICMP messages sent
0 ICMP messages failed
ICMP output histogram:
destination unreachable: 36583239
echo request: 512
echo replies: 8951025
timestamp replies: 136
IcmpMsg:
InType0: 321
InType3: 37132827
InType8: 8951025
InType11: 1
InType13: 136
OutType0: 8951025
OutType3: 36583239
OutType8: 512
OutType14: 136
Tcp:
60003367 active connections openings
54155042 passive connection openings
3761426 failed connection attempts
9024728 connection resets received
277 connections established
1399841003 segments received
1424047510 segments send out
4446484 segments retransmited
28 bad segments received.
51218394 resets sent
Udp:
1447459 packets received
36563515 packets to unknown port received.
0 packet receive errors
37679860 packets sent
0 receive buffer errors
0 send buffer errors
UdpLite:
TcpExt:
782602 invalid SYN cookies received
572 resets received for embryonic SYN_RECV sockets
1315 packets pruned from receive queue because of socket buffer overrun
11 ICMP packets dropped because socket was locked
37257858 TCP sockets finished time wait in fast timer
285 packets rejects in established connections because of timestamp
24510697 delayed acks sent
2685 delayed acks further delayed because of locked socket
Quick ack mode was activated 6953799 times
9107 times the listen queue of a socket overflowed
9107 SYNs to LISTEN sockets dropped
1489 packets directly queued to recvmsg prequeue.
33492 bytes directly in process context from backlog
10 bytes directly received in process context from prequeue
411573977 packet headers predicted
19 packets header predicted and directly queued to user
232193954 acknowledgments not containing data payload received
332343622 predicted acknowledgments
21680 times recovered from packet loss by selective acknowledgements
Detected reordering 24 times using FACK
Detected reordering 41 times using SACK
Detected reordering 1482 times using time stamp
4753 congestion windows fully recovered without slow start
1520 congestion windows partially recovered using Hoe heuristic
13621 congestion windows recovered without slow start by DSACK
674 congestion windows recovered without slow start after partial ack
TCPLostRetransmit: 28
13 timeouts after SACK recovery
30013 fast retransmits
11251 forward retransmits
66 retransmits in slow start
1742135 other TCP timeouts
TCPLossProbes: 211831
TCPLossProbeRecovery: 26484
3 SACK retransmits failed
20791 packets collapsed in receive queue due to low socket buffer
6953811 DSACKs sent for old packets
17 DSACKs sent for out of order packets
35624 DSACKs received
1 DSACKs for out of order packets received
11249124 connections reset due to unexpected data
5562035 connections reset due to early user close
112739 connections aborted due to timeout
TCPDSACKIgnoredOld: 2
TCPDSACKIgnoredNoUndo: 15593
TCPSpuriousRTOs: 3
TCPSackMerged: 2
TCPSackShiftFallback: 296068
TCPBacklogDrop: 53
IPReversePathFilter: 106
TCPTimeWaitOverflow: 2027
TCPRcvCoalesce: 45113470
TCPOFOQueue: 229745
TCPOFOMerge: 17
TCPChallengeACK: 68796
TCPSYNChallenge: 30
TCPAutoCorking: 7149
TCPFromZeroWindowAdv: 45
TCPToZeroWindowAdv: 45
TCPWantZeroWindowAdv: 7796
TCPSynRetrans: 3335473
TCPOrigDataSent: 819593815
TCPHystartTrainDetect: 16982
TCPHystartTrainCwnd: 321758
TCPHystartDelayDetect: 10
TCPHystartDelayCwnd: 1148
TCPACKSkippedPAWS: 9
TCPACKSkippedSeq: 117
TCPACKSkippedChallenge: 5
IpExt:
InNoRoutes: 53
InMcastPkts: 190832
InOctets: 599836950972
OutOctets: 954183523224
InMcastOctets: 6869952
InNoECTPkts: 2756087476
InECT0Pkts: 4050
可以指定打印某个协议栈的信息,也可以间隔时间打印.命令格式:netstat {--statistics|-s} [--tcp|-t] [--udp|-u] [--udplite|-U] [--sctp|-S] [--raw|-w] [delay]
1.2.2 ifconfig
查看网卡信息,修改网卡信息
# ifconfig eth1
eth1: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 9.134.12.85 netmask 255.255.240.0 broadcast 9.134.15.255
inet6 fe80::5054:ff:fe02:fcf3 prefixlen 64 scopeid 0x20<link>
ether 52:54:00:02:fc:f3 txqueuelen 1000 (Ethernet)
RX packets 646798217 bytes 137039458113 (127.6 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 961762924 bytes 205863555339 (191.7 GiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
通常关注以下值,值越低,网络性能越好;如果值越高,说明当前网络可能硬件性能存在问题.
- txqueuelen: 发包的缓存队列长度(长度是包的个数)
- RX errors: 因错误的包产生的丢包
- dropped: 可能性能问题产生的丢包
- overruns: 超出负荷产生的丢包
- frame:帧错误(网卡硬件内部错误)产生的丢包
- carrier: 链路脉冲产生的丢包,比如电缆问题、强电干扰等
- collisions: 包碰撞产生的丢包
1.2.3 route
查看路由表
# route -n
Kernel IP routing table
Destination Gateway Genmask Flags Metric Ref Use Iface
0.0.0.0 1.1.0.1 0.0.0.0 UG 0 0 0 eth1
1.0.0.0 1.1.0.1 255.0.0.0 UG 0 0 0 eth1
1.1.0.0 0.0.0.0 255.255.240.0 U 0 0 0 eth1
匹配原则:精确优先匹配
发到127.0.0.1的包怎么没在route -n的路由表体现?
#系统默认存在不止一张路由表,打印全部路由表的规则可看到
# ip route show table all |grep 127.0.0.1
broadcast 127.0.0.0 dev lo table local proto kernel scope link src 127.0.0.1
local 127.0.0.0/8 dev lo table local proto kernel scope host src 127.0.0.1
local 127.0.0.1 dev lo table local proto kernel scope host src 127.0.0.1
broadcast 127.255.255.255 dev lo table local proto kernel scope link src 127.0.0.1
路由表定义在/etc/iproute2/rt_tables,可支持256个路由表,系统默认带有0(unspec)、253(default)、254(main)、255(local)路由表
1.2.4 ss
# ss -antp
State Recv-Q Send-Q Local Address:Port Peer Address:Port
LISTEN 0 128 *:443 *:* users:(("kube-proxy",pid=9736,fd=17))
LISTEN 0 128 *:5340 *:* users:(("kube-proxy",pid=9736,fd=15))
LISTEN 0 128 *:17917 *:* users:(("kube-proxy",pid=9736,fd=16))
LISTEN 0 128 *:35517 *:*
# ss -anup
State Recv-Q Send-Q Local Address:Port Peer Address:Port
UNCONN 0 0 *:8472 *:*
UNCONN 0 0 1.1.1.1:45176 *:* users:(("sap1015",pid=22752,fd=13))
UNCONN 0 0 1.1.1.1:38712 *:* users:(("sap1015",pid=22752,fd=14))
UNCONN 0 0 *:7315 *:* users:(("dhclient",pid=3779,fd=20))
UNCONN 0 0 127.0.0.1:48555 *:* users:(("sap1015",pid=22752,fd=10))
显示所有处于建立状态的ssh连接
ss -o state established '( dport = :ssh or sport = :ssh )'
可以根据状态过滤显示,其它可用的状态有:established, syn-sent, syn-recv, fin-wait-1, fin-wait-2, time-wait, closed, close-wait, last-ack, listen and closing
1.2.5 ip
查看网卡网络地址
# ip address show|ls
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
valid_lft forever preferred_lft forever
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP group default qlen 1000
link/ether 52:54:00:02:fc:f3 brd ff:ff:ff:ff:ff:ff
inet 9.134.12.85/20 brd 9.134.15.255 scope global eth1
valid_lft forever preferred_lft forever
inet6 fe80::5054:ff:fe02:fcf3/64 scope link
valid_lft forever preferred_lft forever
查看网卡mac地址
# ip link show|ls
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth1: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc mq state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:02:fc:f3 brd ff:ff:ff:ff:ff:ff
查看arp缓存
# ip neigh show|ls
172.20.0.17 dev v-h28edb3920 lladdr ee:7a:dd:24:73:ee REACHABLE
172.17.0.2 dev docker0 lladdr 02:42:ac:11:00:02 STALE
查看路由表
# ip route show
default via 1.1.0.1 dev eth1
1.0.0.0/8 via 1.1.0.1 dev eth1
1.1.0.0/20 dev eth1 proto kernel scope link src 1.1.1.85
查看策略路由
# ip rule show
0: from all lookup local
32766: from all lookup main
32767: from all lookup default
可以加32768条策略路由
1.2.6 tc
网络资源隔离用tc来实现
# tc qdisc ls
qdisc noqueue 0: dev lo root refcnt 2
qdisc mq 0: dev eth1 root
qdisc pfifo_fast 0: dev eth1 parent :2 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc pfifo_fast 0: dev eth1 parent :1 bands 3 priomap 1 2 2 2 1 2 0 0 1 1 1 1 1 1 1 1
qdisc noqueue 0: dev docker0 root refcnt 2
qdisc noqueue 0: dev flannel.1 root refcnt 2
1.2.7 sar
sar号称系统状态检测的"瑞士军刀",支持系统网络/内存/CPU/磁盘检测
显示网络统计信息
# sar -n DEV 1
Linux 3.10.0-862.11.6.el7.x86_64 (ice) 12/14/2020 _x86_64_ (8 CPU)
02:30:48 PM IFACE rxpck/s txpck/s rxkB/s txkB/s rxcmp/s txcmp/s rxmcst/s
02:30:49 PM v-h2c6f7989a 1.00 1.00 0.04 0.04 0.00 0.00 0.00
02:30:49 PM v-h1015e1139 7.00 7.00 1.17 2.30 0.00 0.00 0.00
02:30:49 PM v-hcd1540d8b 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:30:49 PM v-h1ce426bc4 5.00 5.00 0.42 0.45 0.00 0.00 0.00
02:30:49 PM v-h36f57a7fa 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:30:49 PM v-h116a4956b 401.00 219.00 34.72 53.83 0.00 0.00 0.00
02:30:49 PM v-h3a0f0ebe8 8.00 11.00 0.56 10.86 0.00 0.00 0.00
02:30:49 PM v-h55d00ad6f 0.00 0.00 0.00 0.00 0.00 0.00 0.00
-n:表示跟网络相关,后面可以加DEV, EDEV, NFS, NFSD, SOCK, IP, EIP, ICMP, EICMP, TCP, ETCP, UDP, SOCK6, IP6, EIP6, ICMP6, EICMP6, UDP6.
1.2.8 tcpdump
抓包工具
1.2.9 nmap
扫描端口工具
扫描本地80端口
# nmap -sT -p 80 127.0.0.1
Starting Nmap 6.40 ( http://nmap.org ) at 2020-12-14 15:41 CST
Nmap scan report for VM-12-85-centos (127.0.0.1)
Host is up (0.000073s latency).
PORT STATE SERVICE
80/tcp closed http
Nmap done: 1 IP address (1 host up) scanned in 0.02 seconds
扫描参数区别:
-sS/sT/sA/sW/sM: TCP SYN/Connect()/ACK/Window/Maimon scans
-sU: UDP Scan
-sN/sF/sX: TCP Null, FIN, and Xmas scans
--scanflags <flags>: Customize TCP scan flags
-sI <zombie host[:probeport]>: Idle scan
-sY/sZ: SCTP INIT/COOKIE-ECHO scans
-sO: IP protocol scan
-b <FTP relay host>: FTP bounce scan
1.2.10 ping
# ping -f -c 1000 -s 1472 9.135.22.34
PING 9.135.22.34 (9.135.22.34) 1472(1500) bytes of data.
--- 9.135.22.34 ping statistics ---
1000 packets transmitted, 1000 received, 0% packet loss, time 149ms
rtt min/avg/max/mdev = 0.107/0.123/0.981/0.030 ms, ipg/ewma 0.149/0.123 ms
-f: 洪泛ping
-c: 指定包的个数
-s: 指定数据包的长度,可用于测试网卡的MTU设置,MTU一般为1500=数据包长度+数据包头28字节(ip首部20字节+icmp包头8字节)
1.3 套接字socket
# man socket
SOCKET(2) Linux Programmer's Manual SOCKET(2)
NAME
socket - create an endpoint for communication
SYNOPSIS
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
int socket(int domain, int type, int protocol);
常用domain有:
- AF_UNIX, AF_LOCAL: Local communication
- AF_INET: IPv4 Internet protocols
- AF_INET6: IPv6 Internet protocols
常用type有:
- SOCK_STREAM: 表示TCP
- SOCK_DGRAM: 表示UDP
- SOCK_RAW: 类似ICMP
查看支持的socket函数协议有哪些
# man protocols
# cat /etc/protocols
# /etc/protocols:
# $Id: protocols,v 1.11 2011/05/03 14:45:40 ovasik Exp $
#
# Internet (IP) protocols
#
# from: @(#)protocols 5.1 (Berkeley) 4/17/89
#
# Updated for NetBSD based on RFC 1340, Assigned Numbers (July 1992).
# Last IANA update included dated 2011-05-03
#
# See also http://www.iana.org/assignments/protocol-numbers
ip 0 IP # internet protocol, pseudo protocol number
hopopt 0 HOPOPT # hop-by-hop options for ipv6
icmp 1 ICMP # internet control message protocol
igmp 2 IGMP # internet group management protocol
ggp 3 GGP # gateway-gateway protocol
ipv4 4 IPv4 # IPv4 encapsulation
st 5 ST # ST datagram mode
tcp 6 TCP # transmission control protocol
cbt 7 CBT # CBT, Tony Ballardie <A.Ballardie@cs.ucl.ac.uk>
如下是跟性能相关的socket参数
1.3.1 SO_LINGER
改变close行为
SO_LINGER
Sets or gets the SO_LINGER option. The argument is a linger structure.
struct linger {
int l_onoff; /* linger active */
int l_linger; /* how many seconds to linger for */
};
当l_onoff为1,l_linger为0,意味着client端发起close的时候,直接发rst包,不再等待WAIT状态。可以提升性能,避免系统上出现太多的FIN_WAIT,TIME_WAIT状态.
/proc/sys/net/ipv4/tcp_max_tw_buckets这个参数决定了内核维护多少个TIME_WAIT状态. 当然也可以通过调小tcp_max_tw_buckets的值来提升性能,如:
echo 8192 > /proc/sys/net/ipv4/tcp_max_tw_buckets
通过man 7 socket可以看到这些参数的
1.3.2 SO_RCVBUF
socket buf接收缓存大小
# cat /proc/sys/net/core/rmem_default
262144
# cat /proc/sys/net/core/rmem_max
16777216
未设置SO_RCVBUF的话,使用rmem_default;设置SO_RCVBUF的话,比较SO_RCVBUF*2和rmem_max的值,取较小者作为SO_RCVBUF的值
1.3.3 SO_SNDBUF
socket buf发送缓存大小; 作用和SO_RCVBUF类似; 未设置SO_SNDBUF的话,使用wmem_default; 设置SO_SNDBUF的话,比较SO_SNDBUF*2和wmem_max的值,取较小者作为SO_SNDBUF的值
1.3.4 SO_REUSEPORT
多个进程监听同一个端口(内核3.9特性)
注:/proc/sys/net/core这下面跟socket设置相关的参数
1.3.5 listen - backlog
listen的backlog指的是三次握手过程进入EStablished状态之后未被accept处理完的队列长度,通过man listen可以看到函数说明;backlog参数会受到
/proc/sys/net/core/somaxconn影响,取较小者为准. 除了listen的backlog之外,还有syn backlog半连接队列:/proc/sys/net/ipv4/tcp_max_syn_backlog,
最大半连接队列这个值一般不会设置得太大,当达到最大半连接队列后,可通过echo 1 > /proc/sys/net/ipv4/tcp_syncookies设置tcp_syncookies来优化,
实质是通过cpu换内存的方式,当最大半连接队列耗尽后,对后续的半连接进行哈希后存储起来.
1.3.6 文件描述符
全局可打开最大文件描述符数量:/proc/sys/fs/file-max
单进程可打开最大文件描述符数量:ulimit -n
查看当前文件描述符使用情况
# cat /proc/sys/fs/file-nr
2400 0 65535000
2400表示已用的文件描述符,65535000为总共可使用的文件描述符,0为可回收利用的文件描述符
1.4 TCP
TCP是面向可靠连接, TCP还有超时重传机制,还有排序的机制,有发送的窗口,有窗口大小等等
TCP使用了三种基础机制来实现面向连接的服务: 1 使用序列号进行标记,以便TCP接收服务在向目的应用传递数据之前修正错序的报文排序; 2 TCP使用确认,校验,和定时器系统提供可靠性。 3 TCP在应用层数据上附加了一个报头,报头包括序列号字段和这些机制的其他一些必要信息,如叫做端口号的地址字段,该字段可以标识数据的源点和目标应用程序。
TCP传输就像打电话,两边要喊“喂”,确保双方都听到的情况下,才说内容,如果某句话对方没有听清楚, 对方会要求你重新说一次,直至对方清楚为止,打电话就是要双方说的每一句话都清清楚楚,而且收听者逻辑和意思是和讲话者保持一致的。
UDP传输就像寄信,我只管把信写好,只管把信投到信箱里,至于投到信箱之后,邮递员什么时候来取,多少天到达, 邮递员在邮递的过程中会不会弄丢,我是没有办法控制的,我能做的,只是把这封信投出去。
1.4.1 重传机制
TCP 实现可靠传输的方式之一, TCP针对数据包丢失的情况,会用重传机制解决
常见的重传机制:
- 超时重传
- 快速重传
- SACK
- D-SACK
1.4.1.1 超时重传
超时重传:在发送数据时,设定一个定时器,当超过指定的时间后,没有收到对方的 ACK 确认应答报文,就会重发该数据
TCP 会在以下两种情况发生超时重传:
- 数据包丢失
- 确认应答丢失
1.4.1.2 快速重传
快速重传:不以时间为驱动,而是以数据驱动重传
快速重传的工作方式是当收到三个相同的 ACK 报文时,会在定时器过期之前,重传丢失的报文段。 快速重传机制只解决了一个问题,就是超时时间的问题,但是它依然面临着另外一个问题。就是重传的时候,是重传之前的一个,还是重传所有的问题。
1.4.1.3 SACK
TCP 头部「选项」字段里加一个 SACK 的东西,它可以将缓存的地图发送给发送方, 这样发送方就可以知道哪些数据收到了,哪些数据没收到,知道了这些信息,就可以只重传丢失的数据。
三次同样的ACK就会触发重传机制,要支持 SACK,必须双方都要支持。在Linux下,可以通过net.ipv4.tcp_sack参数打开这个功能(Linux 2.4后默认打开)
1.4.1.4 D-SACK
D-SACK,其主要使用了 SACK 来告诉「发送方」有哪些数据被重复接收了
D-SACK的作用:
- 可以让「发送方」知道,是发出去的包丢了,还是接收方回应的 ACK 包丢了;
- 可以知道是不是「发送方」的数据包被网络延迟了;
- 可以知道网络中是不是把「发送方」的数据包给复制了;
在 Linux 下可以通过net.ipv4.tcp_dsack参数开启/关闭这个功能(Linux 2.4 后默认打开)
1.4.2 滑动窗口
为什么要有滑动窗口?
TCP 是每发送一个数据,都要进行一次确认应答。当上一个数据包收到了应答了, 再发送下一个。这样的传输方式有一个缺点:数据包的往返时间越长,通信的效率就越低。 为解决这个问题,TCP 引入了窗口这个概念。即使在往返时间较长的情况下,它也不会降低网络通信的效率。 那么有了窗口,就可以指定窗口大小,窗口大小就是指无需等待确认应答,而可以继续发送数据的最大值。 窗口的实现实际上是操作系统开辟的一个缓存空间,发送方主机在等到确认应答返回之前,必须在缓冲区中保留已发送的数据。如果按期收到确认应答,此时数据就可以从缓存区清除。
TCP 头里有一个字段叫 Window,也就是窗口大小。这个字段是接收端告诉发送端自己还有多少缓冲区可以接收数据。 于是发送端就可以根据这个接收端的处理能力来发送数据,而不会导致接收端处理不过来。通常窗口的大小是由接收方的窗口大小来决定的。 窗口分发送窗口和接收窗口
1.4.3 流量控制
为什么需要流量控制?
发送方不能无脑的发数据给接收方,要考虑接收方处理能力。 如果一直无脑的发数据给对方,但对方处理不过来,那么就会导致触发重发机制,从而导致网络流量的无端的浪费。
TCP 提供一种机制可以让「发送方」根据「接收方」的实际接收能力控制发送的数据量,这就是所谓的流量控制。
1.4.4 拥塞控制
为什么需要拥塞控制?
拥塞控制,控制的目的就是避免「发送方」的数据填满整个网络。而流量控制是避免「发送方」的数据填满「接收方」的缓存,但是并不知道网络的中发生了什么。 为了在「发送方」调节所要发送数据的量,定义了一个叫做「拥塞窗口」的概念
拥塞窗口cwnd,是发送方维护的一个的状态变量,它会根据网络的拥塞程度动态变化的。 引入拥塞窗口后,发送窗口的值是swnd = min(cwnd, rwnd),也就是拥塞窗口和接收窗口中的最小值
拥塞窗口 cwnd 变化的规则:
- 只要网络中没有出现拥塞,cwnd 就会增大;
- 但网络中出现了拥塞,cwnd 就减少;
如何判断网络是否出现了拥塞?
发生了超时重传,就会认为网络出现了用拥塞。
拥塞控制主要算法:
- 慢启动
- 拥塞避免
- 拥塞发生
- 快速恢复
socket编程TCP_CONGESTION参数来决定拥塞控制算法,也可以通过/proc/sys/net/ipv4/tcp_allowed_congestion_control查看当前可用的拥塞控制算法
# cat /proc/sys/net/ipv4/tcp_allowed_congestion_control
cubic reno
Reno算法进入拥塞避免后每经过一个 RTT窗口才加 1,拥塞窗口增长太慢,导致在高速网络下不能充分利用网络带宽。所以为了解决这个问题,BIC和 CUBIC算法逐步被提了出来。
除了reno和cubic之外,还有Google出品的BBR,BBR全称 bottleneck bandwidth and round-trip propagation time。基于包丢失检测的 Reno、NewReno 或者 cubic 为代表,其主要问题有 Buffer bloat 和长肥管道两种。 和这些算法不同,bbr算法会时间窗口内的最大带宽max_bw和最小RTT min_rtt,并以此计算发送速率和拥塞窗口。
1.4.4.1 慢启动
TCP 在刚建立连接完成后,首先是有个慢启动的过程,这个慢启动的意思就是一点一点的提高发送数据包的数量。 慢启动的算法记住一个规则就行:当发送方每收到一个 ACK,拥塞窗口 cwnd 的大小就会加 1。
慢启动会一直增长吗? 有一个叫慢启动门限 ssthresh (slow start threshold)状态变量。
- 当 cwnd < ssthresh 时,使用慢启动算法。
- 当 cwnd >= ssthresh 时,就会使用「拥塞避免算法」。
1.4.4.2 拥塞避免
当拥塞窗口 cwnd 「超过」慢启动门限 ssthresh 就会进入拥塞避免算法。(一般来说 ssthresh 的大小是 65535 字节) 拥塞避免算法就是将原本慢启动算法的指数增长变成了线性增长,还是增长阶段,但是增长速度缓慢了一些。 一直增长着后,网络就会慢慢进入了拥塞的状况了,于是就会出现丢包现象,这时就需要对丢失的数据包进行重传。 当触发了重传机制,也就进入了「拥塞发生算法」
拥塞避免的规则是:每当收到一个 ACK 时,cwnd 增加 1/cwnd。
1.4.4.3 拥塞发生
- 发生超时重传的拥塞发生算法,ssthresh 和 cwnd 的值会发生变化:
- ssthresh 设为 cwnd/2,
- cwnd 重置为 1
接着,就重新开始慢启动,慢启动是会突然减少数据流的。这真是一旦「超时重传」,马上回到解放前。但是这种方式太激进了,反应也很强烈,会造成网络卡顿。
- 发生快速重传的拥塞发生算法, TCP 认为这种情况不严重,因为大部分没丢,只丢了一小部分,则 ssthresh 和 cwnd 变化如下:
- cwnd = cwnd/2 ,也就是设置为原来的一半;
- ssthresh = cwnd;
- 进入快速恢复算法
1.4.4.4 快速恢复
快速重传和快速恢复算法一般同时使用,快速恢复算法是认为,你还能收到 3 个重复 ACK 说明网络也不那么糟糕,所以没有必要像 RTO 超时那么强烈。 进入快速恢复算法如下:
- 拥塞窗口 cwnd = ssthresh + 3 ( 3 的意思是确认有 3 个数据包被收到了);
- 重传丢失的数据包;
- 如果再收到重复的 ACK,那么 cwnd 增加 1;
- 如果收到新数据的 ACK 后,把 cwnd 设置为第一步中的 ssthresh 的值, 原因是该 ACK 确认了新的数据,说明从 duplicated ACK 时的数据都已收到,该恢复过程已经结束, 可以回到恢复之前的状态了,也即再次进入拥塞避免状态;
1.4.5 BBR
内核版本是Linux 4.9及以上的系统已经内置BBR但默认为关闭状态
echo "net.ipv4.tcp_congestion_control=bbr" >> /etc/sysctl.conf
sysctl -p
可以用tc模拟一个大延时网络,通过eth1的包延时2秒
tc qd add dev eth1 root netem delay 2000ms
取消操作
tc qd del dev eth1 root netem delay 2000ms
1.4.6 常用TCP Option
TCP_NODELAY: TCP包被标志为psh,小包也直接发送,不用等积累到大包再一起发送
TCP_CORK: 这个包尽量放在缓存里,等待其它包一起发送
1.5 UDP
面向无连接不可靠
1.6 iptables conntrack
nf_conntrack(在老版本的 Linux 内核中叫 ip_conntrack)是一个内核模块,用于跟踪一个连接的状态的。 连接状态跟踪可以供其他模块使用,最常见的两个使用场景是 iptables 的 nat 的 state 模块。 iptables的nat通过规则来修改目的/源地址,但光修改地址不行,我们还需要能让回来的包能路由到最初的来源主机。 这就需要借助 nf_conntrack 来找到原来那个连接的记录才行。而 state 模块则是直接使用 nf_conntrack 里记录的连接的状态来匹配用户定义的相关规则。 例如下面这条 INPUT 规则用于放行 80 端口上的状态为NEW的连接上的包。
iptables -A INPUT -p tcp -m state --state NEW -m tcp --dport 80 -j ACCEPT。
nf_conntrack模块常用命令
查看nf_conntrack表当前连接数
cat /proc/sys/net/netfilter/nf_conntrack_count
查看nf_conntrack表最大连接数
cat /proc/sys/net/netfilter/nf_conntrack_max
通过dmesg可以查看nf_conntrack的状况:
dmesg |grep nf_conntrack
查看存储conntrack条目的哈希表大小,此为只读文件
cat /proc/sys/net/netfilter/nf_conntrack_buckets
查看nf_conntrack的TCP连接记录时间
cat /proc/sys/net/netfilter/nf_conntrack_tcp_timeout_established
通过内核参数查看命令,查看所有参数配置
sysctl -a | grep nf_conntrack
通过conntrack命令行工具查看conntrack的内容
yum install -y conntrack
conntrack -L
加载对应跟踪模块
[root@plop ~]# modprobe /proc/net/nf_conntrack_ipv4
[root@plop ~]# lsmod | grep nf_conntrack
nf_conntrack_ipv4 9506 0
nf_defrag_ipv4 1483 1 nf_conntrack_ipv4
nf_conntrack_ipv6 8748 2
nf_defrag_ipv6 11182 1 nf_conntrack_ipv6
nf_conntrack 79758 3 nf_conntrack_ipv4,nf_conntrack_ipv6,xt_state
ipv6 317340 28 sctp,ip6t_REJECT,nf_conntrack_ipv6,nf_defrag_ipv6
移除 nf_conntrack 模块
$ sudo modprobe -r xt_NOTRACK nf_conntrack_netbios_ns nf_conntrack_ipv4 xt_state
$ sudo modprobe -r nf_conntrack
查看当前的连接数:
grep nf_conntrack /proc/slabinfo
查出目前 nf_conntrack 的排名:
cat /proc/net/nf_conntrack | cut -d ' ' -f 10 | cut -d '=' -f 2 | sort | uniq -c | sort -nr | head -n 10
查看ip contrack记录, 与conntrack -L内容一样
# cat /proc/net/nf_conntrack
1.7 网卡多队列
查看网卡硬中断
# cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3 CPU4 CPU5 CPU6 CPU7 CPU8 CPU9 CPU10 CPU11 CPU12 CPU13 CPU14 CPU15
0: 106 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IO-APIC-edge timer
1: 10 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IO-APIC-edge i8042
4: 403 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IO-APIC-edge serial
6: 3 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IO-APIC-edge floppy
8: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IO-APIC-edge rtc0
9: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IO-APIC-fasteoi acpi
11: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 IO-APIC-fasteoi uhci_hcd:usb1, virtio3
查看26号网卡中断
# cat /proc/irq/26/smp_affinity
ffff
这是个16进制表示,转化为二进制,分别对应cpu核心数,启用即为1
在没有网卡多队列的前提下,还可以设置RPS和RFS,在内核层面实现负载均衡
# cat /sys/class/net/eth1/queues/rx-0/rps_cpus
ffff
1.8 tc
2 内存
系统ps aux的RSS内存总和很小,free查看已耗尽内存了,消耗花在内核上?通过slabtop可以看到内核内存消耗情况
slabtop
2.1 常用内存状态监控命令
虚拟机内存地址 vs 物理内存地址
Buddy系统
slab
3 cpu性能
3.1 常用cpu状态监控命令
3.1.1 top
top - 19:11:29 up 2 days, 4:24, 6 users, load average: 1.98, 1.88, 2.18
Tasks: 620 total, 2 running, 618 sleeping, 0 stopped, 0 zombie
%Cpu0 : 5.4 us, 3.4 sy, 0.0 ni, 86.6 id, 4.4 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu1 : 7.1 us, 6.8 sy, 0.0 ni, 84.4 id, 1.4 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu2 : 7.1 us, 10.5 sy, 0.0 ni, 80.7 id, 1.4 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu3 : 7.1 us, 10.4 sy, 0.0 ni, 80.8 id, 1.0 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu4 : 4.4 us, 4.1 sy, 0.0 ni, 91.2 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu5 : 3.3 us, 3.0 sy, 0.0 ni, 93.0 id, 0.3 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu6 : 6.4 us, 4.4 sy, 0.0 ni, 88.6 id, 0.3 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu7 : 3.4 us, 4.4 sy, 0.0 ni, 91.9 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu8 : 5.1 us, 4.7 sy, 0.0 ni, 89.2 id, 0.3 wa, 0.0 hi, 0.7 si, 0.0 st
%Cpu9 : 6.7 us, 2.7 sy, 0.0 ni, 90.3 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu10 : 4.0 us, 3.0 sy, 0.0 ni, 92.6 id, 0.3 wa, 0.0 hi, 0.0 si, 0.0 st
%Cpu11 : 5.4 us, 4.0 sy, 0.0 ni, 90.3 id, 0.0 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu12 : 8.1 us, 6.4 sy, 0.0 ni, 84.9 id, 0.3 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu13 : 7.4 us, 3.7 sy, 0.0 ni, 88.2 id, 0.3 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu14 : 4.7 us, 3.4 sy, 0.0 ni, 91.3 id, 0.3 wa, 0.0 hi, 0.3 si, 0.0 st
%Cpu15 : 8.4 us, 8.4 sy, 0.0 ni, 82.6 id, 0.3 wa, 0.0 hi, 0.3 si, 0.0 st
KiB Mem : 65713160 total, 9549144 free, 13793352 used, 42370664 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 50337096 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
10726 root 20 0 304928 47148 18592 S 21.6 0.1 635:17.50 grunt
25750 root 20 0 304832 52676 18588 R 21.6 0.1 621:35.81 grunt
21521 root 20 0 2745488 200540 37888 S 11.6 0.3 424:19.46 kubelet
通过man top可以查看具体字段表示含义
3.1.2 mpstat
每隔1秒采集cpu1的使用统计
# mpstat -P 1 1
Linux 3.10.0-862.11.6.el7.x86_64 (VM-67-5-centos) 02/04/21 _x86_64_ (16 CPU)
19:22:20 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
19:22:21 1 6.12 0.00 4.08 2.04 0.00 0.00 0.00 0.00 0.00 87.76
19:22:22 1 4.12 0.00 3.09 1.03 0.00 0.00 0.00 0.00 0.00 91.75
19:22:23 1 7.07 0.00 4.04 2.02 0.00 1.01 0.00 0.00 0.00 85.86
19:22:24 1 8.08 0.00 6.06 3.03 0.00 1.01 0.00 0.00 0.00 81.82
- irq:硬中断,中断处理的上半部
- soft:中断处理的下半部,软中断是其实现的一种方式
3.1.3 sar
每隔1秒采集cpu1的使用统计
# sar -P 1 1
Linux 3.10.0-862.11.6.el7.x86_64 (VM-67-5-centos) 02/04/21 _x86_64_ (16 CPU)
19:20:01 CPU %user %nice %system %iowait %steal %idle
19:20:02 1 6.12 0.00 4.08 7.14 0.00 82.65
19:20:03 1 6.12 0.00 5.10 6.12 0.00 82.65
19:20:04 1 8.16 0.00 4.08 1.02 0.00 86.73
19:20:05 1 11.11 0.00 5.05 2.02 0.00 81.82
3.1.4 perf
采集指令缓存里面的指令比率样本,可以看到cpu消耗在哪方面比较多;在做进程级别的性能优化可能会用到这个
# perf top
Samples: 19K of event 'cpu-clock', Event count (approx.): 4101070129
10.40% [kernel] [k] __do_softirq
9.19% [kernel] [k] _raw_spin_unlock_irqrestore
6.50% kubelet [.] 0x00000000000e8fa3
5.07% [kernel] [k] finish_task_switch
3.96% [kernel] [k] run_timer_softirq
2.57% ld-musl-x86_64.so.1 [.] 0x00000000000525ed
2.29% kube-apiserver [.] 0x000000000003603b
2.16% kube-controller-manager [.] 0x0000000000037544
3.1.5 pidstat
每隔1秒采集进程11957的cpu使用统计
# pidstat -p 11957 1
Linux 3.10.0-862.11.6.el7.x86_64 (VM-67-5-centos) 02/04/21 _x86_64_ (16 CPU)
19:36:46 UID PID %usr %system %guest %CPU CPU Command
19:36:47 0 11957 1.00 1.00 0.00 2.00 9 etcd
19:36:48 0 11957 6.00 1.00 0.00 7.00 9 etcd
19:36:49 0 11957 9.00 1.00 0.00 10.00 11 etcd
19:36:50 0 11957 1.00 1.00 0.00 2.00 0 etcd
3.1.6 uptime
# uptime
17:14:57 up 2 days, 2:27, 8 users, load average: 2.44, 2.34, 2.10
2.44, 2.34, 2.19分别对应1分钟、5分钟、15分钟当前执行队列中等待cpu的R状态进程有多少个, 值越高,说明系统繁忙
3.1.7 /proc/cpuinfo
# cat /proc/cpuinfo
processor : 0
vendor_id : GenuineIntel
cpu family : 6
model : 94
model name : Intel(R) Xeon(R) Gold 6133 CPU @ 2.50GHz
stepping : 3
microcode : 0x1
cpu MHz : 2494.130
cache size : 28160 KB
physical id : 0
siblings : 16
core id : 0
cpu cores : 16
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ss ht syscall nx pdpe1gb rdtscp lm constant_tsc rep_good nopl eagerfpu pni pclmulqdq ssse3 fma cx16 pcid sse4_1 sse4_2 x2apic movbe popcnt tsc_deadline_timer aes xsave avx f16c rdrand hypervisor lahf_lm abm 3dnowprefetch fsgsbase bmi1 hle avx2 smep bmi2 erms invpcid rtm mpx rdseed adx smap xsaveopt xsavec xgetbv1 arat
bogomips : 4988.26
clflush size : 64
cache_alignment : 64
address sizes : 46 bits physical, 48 bits virtual
power management:
cpu运算能力指标:
- cpu MHz: 主频率2494.130
- bogomips: 4988.26,测量预估当前cpu每秒可以跑多少百万个cpu指令(预估的是整型运算)
3.2 NUMA
NUMA ( Non-Uniform Memory Access),非均匀访问存储模型, 这种模型的是为了解决smp扩容性很差而提出的技术方案,如果说smp相当于多个cpu连接一个内存池导致请求经常发生冲突的话, numa就是将cpu的资源分开,以node为单位进行切割,每个node里有着独有的core,memory等资源, 这也就导致了cpu在性能使用上的提升,但是同样存在问题就是2个node之间的资源交互非常慢, 当cpu增多的情况下,性能提升的幅度并不是很高。所以可以看到很多明明有很多core的服务器却只有2个node区。
numa状态查看
# numactl -H
available: 2 nodes (0-1)
# node0的cpu核心是哪些
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 64089 MB
node 0 free: 12875 MB
# node1的cpu核心是哪些
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 32225 MB
node 1 free: 3696 MB
node distances:
node 0 1
0: 10 21
1: 21 10
这个矩阵怎么看呢?node0访问node0是10,node0访问node1是21,意味着跨node访问速度只有node本地访问速度的一半
显示numa node间的访问次数
# numastat
node0 node1
#节点内的访问次数
numa_hit 57633266847 52827434391
#节点没访问到的次数
numa_miss 5005867871 388568
#跨节点的访问次数
numa_foreign 388568 5005867871
interleave_hit 38143 37553
local_node 57656666307 52823299884
other_node 4982468411 4523075
理论上,如果foreign越高,说明跨node访问比较多,有可能是应用程序就是这样设计的
3.3 中断
中断本质就是cpu的异步机制,中断是一种使CPU中止正在执行的程序而转去处理特殊事件的操作, 这些引起中断的事件称为中断源,它们可能是来自外设的输入输出请求,也可能是计算机的一些异常事故或其它内部原因。 比如键盘/鼠标操作,就是中断事件;中断发送给中断控制器(现在都是可编程中断控制器),中断控制器产生一个事件告诉cpu, 现在做什么都先停下,先处理这个事件. 网卡发送/接收包会产生大量的中断,每一个包都是一个中断事件.
当前系统支持的中断
cat /proc/interrupts
root@xiabingyao-LC0:~# mpstat -P 1
Linux 5.4.0-58-generic (xiabingyao-LC0) 2021年02月07日 _x86_64_ (48 CPU)
14时19分56秒 CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
14时19分56秒 1 3.25 0.00 1.61 0.09 0.00 0.56 0.00 0.16 0.00 94.33
中断分为中断上半部(硬件中断)和中断下半部(中断下半部有多种,软中断是其中一种);中断是一种比较昂贵的资源,不一定要全部走完内核协议栈所有过程, 要尽量缩短中断处理的时间;如网卡收到一个包,内核保证所有的硬中断(irq)先处理,当没有更多的硬中断事件的时候,内核有余力的情况下就去处理软中断(如解包、把包发给应用程序等); 网卡处理能力出现瓶颈的时候,往往是irq不高,soft高.
3.3.1 timer中断
一个cpu如何实现进程并发执行?基于时间片的cpu调度,时间片切分基于timer中断来设计,每隔一个时间片的时间发一个中断,让cpu停止下来去处理其它的
# vmstat 1
procs -----------memory---------- ---swap-- -----io---- -system-- ------cpu-----
r b 交换 空闲 缓冲 缓存 si so bi bo in cs us sy id wa st
1 0 0 16585568 1992240 21967532 0 0 0 53 0 0 4 2 94 0 0
1 0 0 16581756 1992240 21967592 0 0 0 1540 8769 16732 3 1 96 0 0
1 0 0 16582336 1992240 21967728 0 0 0 40 6992 14211 3 1 97 0 0
1 0 0 16582848 1992240 21967732 0 0 0 0 5598 11326 3 0 97 0 0
1 0 0 16585544 1992240 21968000 0 0 0 168 8168 16166 3 0 96 0 0
1 0 0 16584456 1992240 21967748 0 0 0 0 7030 14329 3 1 96 0 0
3 0 0 16584452 1992240 21967756 0 0 0 96 6190 13049 3 0 97 0 0
2 0 0 16582648 1992240 21967764 0 0 0 4 5295 10501 3 0 97 0 0
2 0 0 16572040 1992240 21968028 0 0 0 96 7127 14023 5 1 94 0 0
2 0 0 16560732 1992240 21967776 0 0 0 28 7608 14079 5 0 95 0 0
- in即interupt,每秒钟中断的次数
- cs即context switch,每秒钟上下文切换的次数
查看当前的时钟中断频率是多少
# cat /boot/config-5.8.0-41-generic |grep CONFIG_HZ
# CONFIG_HZ_PERIODIC is not set
# CONFIG_HZ_100 is not set
CONFIG_HZ_250=y
# CONFIG_HZ_300 is not set
# CONFIG_HZ_1000 is not set
CONFIG_HZ=250
这里时钟中断频率是每秒250次,还有300,1000的值,配置为250可能是为了吞吐量
系统性能调整的实质:系统性能上限取决于硬件的性能,性能调整就像一个天平的两端,一端是吞吐量,另一端是响应速度.
3.4 调度器
3.4.1 O(n)调度器
2.4版本的Linux内核使用的调度算法非常简单和直接,由于每次在寻找下一个任务时需要遍历系统中所有的任务(链表)
3.4.2 O(1)调度器
在2.6版本的内核中加入了全新的调度算法,它能够在常数时间内调度任务
从系统层面来看应用程序,应用程序分为IO消耗类型和CPU消耗类型,可以用nice和renice来调整进程的静态优先级,
内核维护了一个进程动态优先级的值,top这边看到的PR字段,
top - 17:25:45 up 2:01, 4 users, load average: 1.92, 2.48, 2.60
Tasks: 629 total, 1 running, 628 sleeping, 0 stopped, 0 zombie
%Cpu(s): 7.9 us, 2.8 sy, 0.0 ni, 87.3 id, 0.9 wa, 0.0 hi, 0.9 si, 0.2 st
KiB Mem : 32779308 total, 19690788 free, 6345328 used, 6743192 buff/cache
KiB Swap: 0 total, 0 free, 0 used. 25745752 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
32160 1337 20 0 574988 187132 11952 S 74.6 0.6 26:48.93 nginx
32340 root 20 0 305092 48904 18592 S 27.1 0.1 30:41.41 grunt
17846 root 20 0 939828 353524 5824 S 22.1 1.1 15:52.85 fluentd
想获得更高的优先级,可以把一个进程调整为实时进程,系统会优先让实时进程响应速度变快
root@xiabingyao-LC0:~# chrt -h
显示或更改某个进程的实时调度属性。
设置策略:
chrt [选项] <优先级> <命令> [<参数>...]
chrt [选项] --pid <优先级> <pid>
获取策略
chrt [选项] -p <pid>
策略选项:
-b, --batch 将策略设置为 SCHED_BATCH
-d, --deadline 将策略设置为 SCHED_DEADLINE
-f, --fifo 将策略设置为 SCHED_FIFO
-i, --idle 将策略设置为 SCHED_IDLE
-o, --other 将策略设置为 SCHED_OTHER
-r, --rr 将策略设置为 SCHED_RR (默认)
调度选项:
-R, --reset-on-fork 为 FIFO 或 RR 设置 SCHED_RESET_ON_FORK
-T, --sched-runtime <ns> DEADLINE 的运行时参数
-P, --sched-period <ns> DEADLINE 的周期参数
-D, --sched-deadline <ns> DEADLINE 的截止时间参数
其他选项:
-a, --all-tasks 对指定 pid 的所有任务(线程) 操作
-m, --max 显示最小和最大有效优先级
-p, --pid 对指定且存在的 pid 操作
-v, --verbose 显示状态信息
-h, --help display this help
-V, --version display version
进程状态
~# man ps
PROCESS STATE CODES
Here are the different values that the s, stat and state output specifiers (header
"STAT" or "S") will display to describe the state of a process:
D uninterruptible sleep (usually IO)
I Idle kernel thread
R running or runnable (on run queue)
S interruptible sleep (waiting for an event to complete)
T stopped by job control signal
t stopped by debugger during the tracing
W paging (not valid since the 2.6.xx kernel)
X dead (should never be seen)
Z defunct ("zombie") process, terminated but not reaped by its parent
For BSD formats and when the stat keyword is used, additional characters may be
displayed:
< high-priority (not nice to other users)
N low-priority (nice to other users)
L has pages locked into memory (for real-time and custom IO)
s is a session leader
l is multi-threaded (using CLONE_THREAD, like NPTL pthreads do)
+ is in the foreground process group
- D状态进程:不可被打断休眠,通常是在等待IO事件,如果被打断的话,有可能就会出现内存、磁盘数据不一致的现象
- Z状态进程:僵尸进程,什么是僵尸进程?子进程退出,父进程没回收。僵尸进程是进程退出的正常状态,介于子进程退出之后与父进程回收之前, 不正常的是父进程没回收子进程;僵尸进程会占用pid,不会占用内存/cpu。
僵尸进程处理方式:找到它的父进程,把父进程杀死,这里面利用到孤儿进程的概念(父进程先于子进程,此时子进程就会被1号进程收养); 如果kill父进程也不行的话,只能重启了。
Linux里的进程和线程,从调度器角度来看的话,都是平等的,线程也会被调度执行;在Linux没有线程的说法,线程又称轻量级进程, 在Linux里进程和线程的区别是:是否共享同一个进程资源。
3.4.3 CFS调度器
CFS的全称是Complete Fair Scheduler,也就是完全公平调度器。从2.6.23开始被作为默认调度器; 它实现了一个基于权重的公平队列算法,从而将CPU时间分配给多个任务(每个任务的权重和它的nice值有关,nice值越低,权重值越高)。 每个任务都有一个关联的虚拟运行时间vruntime,它表示一个任务所使用的CPU时间除以其优先级得到的值。 相同优先级和相同vruntime的两个任务实际运行的时间也是相同的,这就意味着CPU资源是由它们均分了。 为了保证所有任务能够公平推进,每当需要抢占当前任务时,CFS总会挑选出vruntime最小的那个任务运行。
cfs相关的性能调整参数都在/proc/sys/kernel/目录下以sched_开头
~# cat /proc/sys/kernel/sched_
sched_autogroup_enabled sched_min_granularity_ns sched_tunable_scaling
sched_cfs_bandwidth_slice_us sched_nr_migrate sched_util_clamp_max
sched_child_runs_first sched_rr_timeslice_ms sched_util_clamp_min
sched_domain/ sched_rt_period_us sched_wakeup_granularity_ns
sched_latency_ns sched_rt_runtime_us
sched_migration_cost_ns sched_schedstats
~# cat /proc/sys/kernel/sched_latency_ns
24000000
sched_latency_ns:预期延时事件,这个值就确定了一个新建进程首先会在这个时间段内一定会被调度上, 每个进程分到的执行时间= sched_latency_ns / N(当前系统R状态进程个数)
~# cat /proc/sys/kernel/sched_min_granularity_ns
3000000
当每个进程分到的执行时间小于sched_min_granularity_ns的时候,每个进程分到的最小执行时间=sched_min_granularity_ns;通过以上两个参数设置,可以 起到cfs性能调整作用。
cfs本身是一个调度队列,基于红黑树实现;
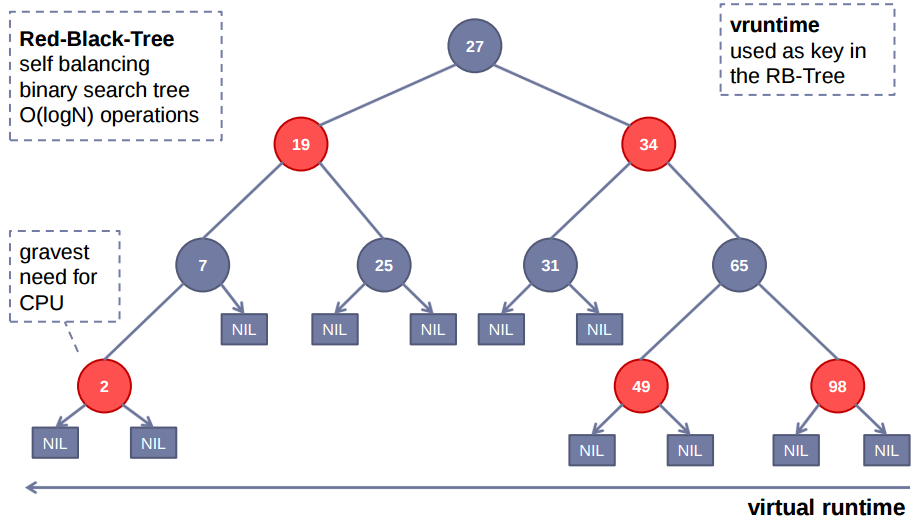
红黑树使用一个key值来排序,vruntime是cfs调度器记录每一个进程现在占用cpu运行的时间是多少,用这个cpu时间作为红黑树的key值; key值越小排在左子树,key值越大排在右子树,红黑树有自平衡的特点,O(logN)的时间复杂度;cfs调度器如何调度进程?每次都找key值最小的 那个进程来执行,比如左子树那边2号,优先拿出来执行就会增加2号的vruntime,从整个红黑树来看,最终这些进程运行的vruntime会变成一样大的, 从而保证了cfs调度是完全公平调度。cpu消耗型进程会一直消耗cpu,所以在红黑树里会一直处于右子树;io消耗型进程会一直释放cpu,vruntime涨得 比较慢,所以在红黑树里会一直处于左子树;所以就天然形成io消耗型进程优先级更高。有了cfs之后,cgroup限制进程的cpu使用率就变得容易了。
父进程fork出一个子进程,哪个优先执行? 通过一个参数可以控制
~# cat /proc/sys/kernel/sched_child_runs_first
0
打开的话即子进程优先执行,关闭的话取决于调度器在平台上的实现(有可能子进程不先执行,也有可能子进程先执行)
sched_yield系统调用可以主动让出cpu,有点像python的yield协程实现
~# man sched_yield
SCHED_YIELD(2) Linux Programmer's Manual SCHED_YIELD(2)
NAME
sched_yield - yield the processor
SYNOPSIS
#include <sched.h>
int sched_yield(void);
DESCRIPTION
sched_yield() causes the calling thread to relinquish the CPU. The thread is
moved to the end of the queue for its static priority and a new thread gets to
run.
RETURN VALUE
On success, sched_yield() returns 0. On error, -1 is returned, and errno is set
appropriately.
ERRORS
In the Linux implementation, sched_yield() always succeeds.
CONFORMING TO
POSIX.1-2001, POSIX.1-2008.
3.5 cgroup
cgroup cpu绑定例子
#1. 创建test目录
~# mkdir /sys/fs/cgroup/cpuset/test
~# ls /sys/fs/cgroup/cpuset/test/
cgroup.clone_children cpuset.effective_cpus cpuset.memory_migrate cpuset.mems tasks
cgroup.procs cpuset.effective_mems cpuset.memory_pressure cpuset.sched_load_balance
cpuset.cpu_exclusive cpuset.mem_exclusive cpuset.memory_spread_page cpuset.sched_relax_domain_level
cpuset.cpus cpuset.mem_hardwall cpuset.memory_spread_slab notify_on_release
#2. 绑定在第1,2个核上
~# cat /sys/fs/cgroup/cpuset/test/cpuset.cpus
~# echo "1,2" > !$
echo "1,2" > /sys/fs/cgroup/cpuset/test/cpuset.cpus
~# cat !$
cat /sys/fs/cgroup/cpuset/test/cpuset.cpus
1-2
#3. 启用cpuset功能
# mems是一个功能开关,影响的是numa,可以指定在哪个numa节点运行;如果未设置相当于没启用cpuset功能
root@xiabingyao-LC0:~# cat /sys/fs/cgroup/cpuset/test/cpuset.mems
~# numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 24 25 26 27 28 29 30 31 32 33 34 35
node 0 size: 64089 MB
node 0 free: 12516 MB
node 1 cpus: 12 13 14 15 16 17 18 19 20 21 22 23 36 37 38 39 40 41 42 43 44 45 46 47
node 1 size: 32225 MB
node 1 free: 3246 MB
node distances:
node 0 1
0: 10 21
1: 21 10
~# echo "0-1" > /sys/fs/cgroup/cpuset/test/cpuset.mems
~# cat /sys/fs/cgroup/cpuset/test/cpuset.mems
0-1
#4. 绑定一个进程或一组进程运行在这个cgroup里
~# cgexec -g cpuset:test <具体程序命令>
centos系统也提供自动化配置cgroup的方式
# vim /etc/cgconfig.conf
# By default, we expect systemd mounts everything on boot,
# so there is not much to do.
# See man cgconfig.conf for further details, how to create groups
# on system boot using this file.
group test {
cpuset {
cpuset.cpus = "1,2";
cpuset.mems = "0-1";
}
}
# systemctl restart cgconfig
自动创建test cpuset cgrogup
查看其它cgroup cpu配置参数
# ls /sys/fs/cgroup/cpu/cpu
cpu.cfs_period_us cpu.rt_period_us cpu.stat cpuacct.usage
cpu.cfs_quota_us cpu.rt_runtime_us cpuacct.stat cpuacct.usage_percpu
cpu.cfs_relax_thresh_sec cpu.shares cpuacct.uptime
# cat /sys/fs/cgroup/cpu/cpu.cfs_period_us
100000
# cat /sys/fs/cgroup/cpu/cpu.cfs_quota_us
-1
- cpu.cfs_quota_us:比如限制一个进程最多占用cpu不超过50%,-1表示没有限制
- cpu.shares:多个cpu cgroup之间权重比例,比如2:1
- cpu.cfs_periods_us:这个值是针对单个核心的,如果cfs_period_us=cfs_quota_us, quota里的限制可以发挥出100%的cpu性能;如果cfs_period_us=cfs_quota_us*2,quota里的限制只能发挥出单个核心50%的cpu性能; 如果cfs_period_us=cfs_quota_us / 2 * 总核心数,说明quota里的限制可以发挥出所有核心50%的cpu性能;
# echo "1200000" > /sys/fs/cgroup/cpu/test/cpu.cfs_quota_us
# cgexec -g cpu:test <具体程序命令>
参考链接
- TCP 重传、滑动窗口、流量控制、拥塞控制
- 万字详文:TCP 拥塞控制详解
- iptables之nf_conntrack模块
- cpu三大架构 numa smp mpp
- 论文学习之 Linux Kernel 调度器
- HTTPS使用非对称+对称组合加密
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
