defer 7个知识点
- defer的执行顺序:有多个defer的时候,是按照栈的关系来执行
- defer与return谁先谁后:return之后的语句先执行,defer后的语句后执行
函数的返回值初始化与defer间接影响
只要声明函数的返回值变量名称,就会在函数初始化时候为之赋值为0,而且在函数体作用域可见
有名函数返回值遇见defer情况
通过知识点2得知,先return,再defer,所以在执行完return之后,还要再执行defer里的语句,依然可以修改本应该返回的结果
defer遇见panic
遇到panic时,遍历本协程的defer链表,并执行defer。在执行defer过程中:遇到recover则停止panic,返回recover处继续往下执行。 如果没有遇到recover,遍历完本协程的defer链表后,向stderr抛出panic信息
defer中包含panic
panic仅有最后一个可以被revover捕获
defer下的函数参数包含子函数
func function(index int, value int) int {
fmt.Println(index)
return index
}
func main() {
defer function(1, function(3, 0))
defer function(2, function(4, 0))
}
执行顺序:function(3) -> function(4) -> function(2) -> function(1)
atomic.Value vs sync.Mutex
原子操作由底层硬件支持,而锁则由操作系统的调度器实现。锁应当用来保护一段逻辑,对于一个变量更新的保护,原子操作通常会更有效率,并且更能利用计算机多核的优势, 如果要更新的是一个复合对象,则应当使用atomic.Value封装好的实现。
进程 vs 线程 vs 协程
进程
进程是系统资源分配的最小单位, 进程包括文本段text region、数据段data region和堆栈段stack region等。 进程的创建和销毁都是系统资源级别的,因此是一种比较昂贵的操作, 进程是抢占式调度其有三个状态:等待态、就绪态、运行态。进程之间是相互隔离的, 它们各自拥有自己的系统资源, 更加安全但是也存在进程间通信不便的问题。
线程
进程是线程的载体容器,多个线程除了共享进程的资源还拥有自己的一少部分独立的资源, 因此相比进程而言更加轻量,进程内的多个线程间的通信比进程容易,但是也同样带来了同步和互斥的问题和线程安全问题, 尽管如此多线程编程仍然是当前服务端编程的主流,线程也是CPU调度的最小单位,多线程运行时就存在线程切换问题
协程
协程在有的资料中称为微线程或者用户态轻量级线程,协程调度不需要内核参与而是完全由用户态程序来决定, 因此协程对于系统而言是无感知的。协程由用户态控制就不存在抢占式调度那样强制的CPU控制权切换到其他进线程, 多个协程进行协作式调度,协程自己主动把控制权转让出去之后,其他协程才能被执行到, 这样就避免了系统切换开销提高了CPU的使用效率。
小结
- 进程/线程抢占式调度由系统内核调度,成本大效率低
- 协程协作式调度由用户态调度,成本低效率高
GPM调度
如果有大量的协程,何时让出控制权,何时恢复执行?忽然明白了抢占式调度的优势了,在抢占式调度中都是由系统内核来完成的。 我们需要一个"用户态协程调度器". Golang Goroutine是如何解决的呢?
Golang GPM模型使用一种M:N的调度器来调度任意数量的协程运行于任意数量的系统线程中, 从而保证了上下文切换的速度并且利用多核,但是增加了调度器的复杂度。
引用网络上的一张图
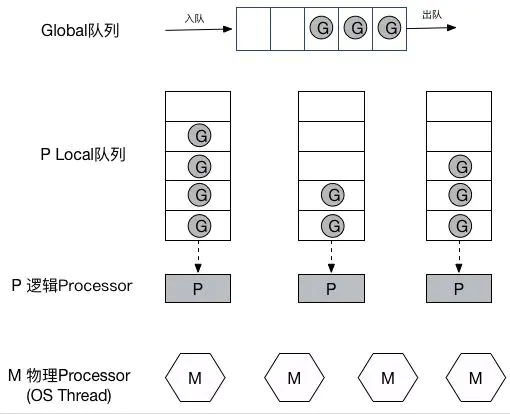
GPM调度过程简述:
新创建的Goroutine会先存放在Global全局队列中,等待Go调度器进行调度, 随后Goroutine被分配给其中的一个逻辑处理器P,并放到这个逻辑处理器对应的Local本地运行队列中, 最终等待被逻辑处理器P执行即可。 在M与P绑定后,M会不断从P的Local队列中无锁地取出G,并切换到G的堆栈执行, 当P的Local队列中没有G时,再从Global队列中获取一个G,当Global队列中也没有待运行的G时, 则尝试从其它的P窃取部分G来执行相当于P之间的负载均衡。
读写锁 vs 互斥锁 vs 死锁
死锁
两个或两个以上进程竞争资源造成的一种阻塞现象
golang 中的 sync 包实现了两种锁:
- Mutex:互斥锁
- RWMutex:读写锁,RWMutex 基于 Mutex 实现
Mutex(互斥锁)
- Mutex 为互斥锁,Lock() 加锁,Unlock() 解锁
- 在一个 goroutine 获得 Mutex 后,其他 goroutine 只能等到这个 goroutine 释放该 Mutex
- 使用 Lock() 加锁后,不能再继续对其加锁,直到利用 Unlock() 解锁后才能再加锁
- 在 Lock() 之前使用 Unlock() 会导致 panic 异常
- 已经锁定的 Mutex 并不与特定的 goroutine 相关联,这样可以利用一个 goroutine 对其加锁,再利用其他 goroutine 对其解锁
- 在同一个 goroutine 中的 Mutex 解锁之前再次进行加锁,会导致死锁
- 适用于读写不确定,并且只有一个读或者写的场景
RWMutex(读写锁)
- RWMutex 是单写多读锁,该锁可以加多个读锁或者一个写锁
- 读锁占用的情况下会阻止写,不会阻止读,多个 goroutine 可以同时获取读锁
- 写锁会阻止其他 goroutine(无论读和写)进来,整个锁由该 goroutine 独占
- 适用于读多写少的场景
- Lock() 加写锁,Unlock() 解写锁
- 如果在加写锁之前已经有其他的读锁和写锁,则 Lock() 会阻塞直到该锁可用,为确保该锁可用,已经阻塞的 Lock() 调用会从获得的锁中排除新的读取器,即写锁权限高于读锁,有写锁时优先进行写锁定
- 在 Lock() 之前使用 Unlock() 会导致 panic 异常
- RLock() 加读锁,RUnlock() 解读锁
- RLock() 加读锁时,如果存在写锁,则无法加读锁;当只有读锁或者没有锁时,可以加读锁,读锁可以加载多个
- RUnlock() 解读锁,RUnlock() 撤销单词 RLock() 调用,对于其他同时存在的读锁则没有效果
- 在没有读锁的情况下调用 RUnlock() 会导致 panic 错误
- RUnlock() 的个数不得多余 RLock(),否则会导致 panic 错误
slice扩容机制
slice扩容范例
例子1
func main() {
a := make([]int, 2, 2)
fmt.Printf("原始容量:%d\n", cap(a))
a = append(a, 1,2,3)
fmt.Printf("扩容后的容量:%d\n", cap(a))
}
例子2
func main() {
a := make([]int, 4, 4)
fmt.Printf("原始容量:%d\n", cap(a))
a = append(a, 1,2,3)
fmt.Printf("扩容后的容量:%d\n", cap(a))
}
预估扩容容量
slice预估扩容容量的源码实现go1.16.5/src/runtime/slice.go
// growslice handles slice growth during append.
// It is passed the slice element type, the old slice, and the desired new minimum capacity,
// and it returns a new slice with at least that capacity, with the old data
// copied into it.
// The new slice's length is set to the old slice's length,
// NOT to the new requested capacity.
// This is for codegen convenience. The old slice's length is used immediately
// to calculate where to write new values during an append.
// TODO: When the old backend is gone, reconsider this decision.
// The SSA backend might prefer the new length or to return only ptr/cap and save stack space.
func growslice(et *_type, old slice, cap int) slice {
......
newcap := old.cap
doublecap := newcap + newcap
if cap > doublecap {
newcap = cap
} else {
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
......
根据源码总结出来的预估扩容容量的原理是:
- 如果需要的总容量 > 原始容量 * 2,新扩容后的容量 = 需要的总容量
- 需要的总容量 <= 原始容量 * 2,且原始容量小于1024,新扩容后的容量 = 原始容量 * 2
- 需要的总容量 <= 原始容量 * 2,且原始容量大于等于1024,新扩容后的容量 = 原始容量 * 1.25^n,直到新扩容后的容量>=需要的总容量
例子1实际运行结果:
原始容量:2
扩容后的容量:6
为什么扩容后的容量不是5,而是6?
例子2实际运行结果:
原始容量:4
扩容后的容量:8
预估扩容容量的原理跟实际运行结果不相匹配,问题出在哪里?最终是分配一段内存大小空间出来,这个内存空间不是随意分配的,而是由golang内存管理模块决定的, 内存块大小都是固定的。
所需内存大小
golang内存管理模块,划分的内存块大小:go1.16.5/src/runtime/sizeclasses.go
// class bytes/obj bytes/span objects tail waste max waste
// 1 8 8192 1024 0 87.50%
// 2 16 8192 512 0 43.75%
// 3 24 8192 341 8 29.24%
// 4 32 8192 256 0 21.88%
// 5 48 8192 170 32 31.52%
// 6 64 8192 128 0 23.44%
// 7 80 8192 102 32 19.07%
// 8 96 8192 85 32 15.95%
// 9 112 8192 73 16 13.56%
// 10 128 8192 64 0 11.72%
// 11 144 8192 56 128 11.82%
// 12 160 8192 51 32 9.73%
// 13 176 8192 46 96 9.59%
// 14 192 8192 42 128 9.25%
// 15 208 8192 39 80 8.12%
// 16 224 8192 36 128 8.15%
// 17 240 8192 34 32 6.62%
// 18 256 8192 32 0 5.86%
// 19 288 8192 28 128 12.16%
// 20 320 8192 25 192 11.80%
// 21 352 8192 23 96 9.88%
// 22 384 8192 21 128 9.51%
// 23 416 8192 19 288 10.71%
// 24 448 8192 18 128 8.37%
// 25 480 8192 17 32 6.82%
// 26 512 8192 16 0 6.05%
// 27 576 8192 14 128 12.33%
// 28 640 8192 12 512 15.48%
// 29 704 8192 11 448 13.93%
// 30 768 8192 10 512 13.94%
// 31 896 8192 9 128 15.52%
// 32 1024 8192 8 0 12.40%
// 33 1152 8192 7 128 12.41%
// 34 1280 8192 6 512 15.55%
// 35 1408 16384 11 896 14.00%
// 36 1536 8192 5 512 14.00%
// 37 1792 16384 9 256 15.57%
// 38 2048 8192 4 0 12.45%
// 39 2304 16384 7 256 12.46%
// 40 2688 8192 3 128 15.59%
// 41 3072 24576 8 0 12.47%
// 42 3200 16384 5 384 6.22%
// 43 3456 24576 7 384 8.83%
// 44 4096 8192 2 0 15.60%
// 45 4864 24576 5 256 16.65%
// 46 5376 16384 3 256 10.92%
// 47 6144 24576 4 0 12.48%
// 48 6528 32768 5 128 6.23%
// 49 6784 40960 6 256 4.36%
// 50 6912 49152 7 768 3.37%
// 51 8192 8192 1 0 15.61%
// 52 9472 57344 6 512 14.28%
// 53 9728 49152 5 512 3.64%
// 54 10240 40960 4 0 4.99%
// 55 10880 32768 3 128 6.24%
// 56 12288 24576 2 0 11.45%
// 57 13568 40960 3 256 9.99%
// 58 14336 57344 4 0 5.35%
// 59 16384 16384 1 0 12.49%
// 60 18432 73728 4 0 11.11%
// 61 19072 57344 3 128 3.57%
// 62 20480 40960 2 0 6.87%
// 63 21760 65536 3 256 6.25%
// 64 24576 24576 1 0 11.45%
// 65 27264 81920 3 128 10.00%
// 66 28672 57344 2 0 4.91%
// 67 32768 32768 1 0 12.50%
从上图看出,内存块增长并不是规律的
匹配最合适的内存大小
所需内存大小 = 预估容量 * 元素类型大小,套用上述例子1,所需内存大小 = 5 * 8字节(一个int在64位操作系统里是64位,也就是8字节) = 40字节,
查看上图最匹配的内存空间大小是48字节,48/8=6个int的容量
Goroutine id
利用runtime.Stack可以获取全部Goroutine的栈信息,官方net/http2库中curGoroutineID函数也采用这种方式获取Goroutine id, net/http2获取Goroutine id
获取到Goroutine id,可以方便debug,这个id可以作为唯一标识,将Goroutine中调用的函数层级串联起来; 比较典型的例子:在web框架中,在日志中打印这个id,可以很方便对整个请求过程进行跟踪和分析。
package main
import (
"bytes"
"fmt"
"runtime"
"strconv"
"sync"
)
func GetGoid() uint64 {
b := make([]byte, 64)
b = b[:runtime.Stack(b, false)]
b = bytes.TrimPrefix(b, []byte("goroutine "))
b = b[:bytes.IndexByte(b, ' ')]
n, _ := strconv.ParseUint(string(b), 10, 64)
return n
}
func main() {
fmt.Println("main", GetGoid())
var wg sync.WaitGroup
for i := 0; i < 20; i++ {
i := i
wg.Add(1)
go func() {
defer wg.Done()
fmt.Println(i, GetGoid())
}()
}
wg.Wait()
}
RPC
grpc
grpc入门
入门/
├── main.go
├── protobuf
│├── hello.pb.go
│└── hello.proto
└── server
└── server.go
2 directories, 4 files
protobuf/hello.proto
syntax = "proto3";
package protobuf;
// message关键字定义一个叫String的类型
message String {
string value = 1;
}
// 定义rpc方法
service HelloService {
rpc Hello (String) returns (String);
通过protoc -I protobuf protobuf/*.proto --go_out=plugins=grpc:protobuf生成hello.pb.go
main.go
package main
import (
"context"
"fmt"
"google.golang.org/grpc"
"log"
. "test/protobuf"
)
func main() {
conn, err := grpc.Dial("localhost:1234", grpc.WithInsecure())
if err != nil {
log.Fatal(err)
}
defer conn.Close()
// protobuf生成Client
client := NewHelloServiceClient(conn)
reply, err := client.Hello(context.Background(), &String{Value: "hello"})
if err != nil {
log.Fatal(err)
}
fmt.Println(reply.GetValue())
server/server.go
package main
import (
"context"
"google.golang.org/grpc"
"log"
"net"
. "test/protobuf"
)
type HelloServiceImpl struct{}
func (p *HelloServiceImpl) Hello(ctx context.Context, args *String) (*String, error) {
reply := &String{Value: "hello:" + args.GetValue()}
return reply, nil
}
func main() {
grpcServer := grpc.NewServer()
// protobuf生成注册函数
RegisterHelloServiceServer(grpcServer, new(HelloServiceImpl))
lis, err := net.Listen("tcp", ":1234")
if err != nil {
log.Fatal(err)
}
grpcServer.Serve(lis)
grpc stream
传统rpc不适合上传/下载数据量大的场景,grpc提供了stream特性
stream/
├── main.go
├── protobuf
│ ├── hello.pb.go
│ └── hello.proto
└── server
└── server.go
2 directories, 4 files
protobuf/hello.proto
syntax = "proto3";
package protobuf;
message String {
string value = 1;
}
service HelloService {
rpc Hello (String) returns (String);
// 关键字stream启用流特性, 添加一个双向流的方法
rpc Channel (stream String) returns (stream String);
main.go
package main
import (
"context"
"fmt"
"google.golang.org/grpc"
"io"
"log"
. "test/protobuf"
"time"
)
func main() {
conn, err := grpc.Dial("localhost:1234", grpc.WithInsecure())
if err != nil {
log.Fatal(err)
}
defer conn.Close()
client := NewHelloServiceClient(conn)
// 先获取stream对象
stream, err := client.Channel(context.Background())
if err != nil {
log.Fatal(err)
}
// 模拟客户端发送数据
go func() {
for {
if err := stream.Send(&String{Value: "hi"}); err != nil {
log.Fatal(err)
}
time.Sleep(time.Second)
}
}()
// 循环接收数据
for {
reply, err := stream.Recv()
if err != nil {
if err == io.EOF {
break
}
log.Fatal(err)
}
fmt.Println(reply.GetValue())
}
}
server/server.go
package main
import (
"context"
"google.golang.org/grpc"
"io"
"log"
"net"
. "test/protobuf"
)
type HelloServiceImpl struct{}
func (p *HelloServiceImpl) Hello(ctx context.Context, args *String) (*String, error) {
reply := &String{Value: "hello:" + args.GetValue()}
return reply, nil
}
// 循环接收客户端的数据,数据重新组装后,通过stream又发给客户端;双向流数据的发送和接收是独立的
func (p *HelloServiceImpl) Channel(stream HelloService_ChannelServer) error {
for {
args, err := stream.Recv()
if err != nil {
if err == io.EOF {
return nil
}
return err
}
reply := &String{Value: "hello:" + args.GetValue()}
err = stream.Send(reply)
if err != nil {
return err
}
}
}
func main() {
grpcServer := grpc.NewServer()
RegisterHelloServiceServer(grpcServer, new(HelloServiceImpl))
lis, err := net.Listen("tcp", ":1234")
if err != nil {
log.Fatal(err)
}
grpcServer.Serve(lis)
}
http-rpc
在http协议上提供jsonrpc服务
http-rpc/server.go
package main
import (
"io"
"net/http"
"net/rpc"
"net/rpc/jsonrpc"
)
type HelloService struct {}
func (p *HelloService) Hello(request string, reply *string) error {
*reply = "hello:" + request
return nil
}
func main() {
rpc.RegisterName("HelloService", new(HelloService))
// 在处理函数中基于http.ResponseWriter和http.Request类型的参数
// 构造一个io.ReadWriteCloser类型的conn通道
http.HandleFunc("/hello", func(w http.ResponseWriter, r *http.Request) {
var conn io.ReadWriteCloser = struct {
io.Writer
io.ReadCloser
}{
ReadCloser: r.Body,
Writer: w,
}
rpc.ServeRequest(jsonrpc.NewServerCodec(conn))
})
http.ListenAndServe(":1234", nil)
}
使用curl调用
curl localhost:1234/hello -X POST \
--data '{"method":"HelloService.Hello","params":["hello"],"id":0}'
json-rpc
采用官方net/rpc/jsonrpc扩展,只要是同样的json结构,就可以进行跨语言rpc
json-rpc/
├── client
│ └── test.go
├── main.go
└── server
└── server.go
2 directories, 3 files
main.go
package main
import (
. "./server"
"log"
"net"
"net/rpc"
"net/rpc/jsonrpc"
)
func main() {
RegisterHelloService(new(HelloService))
listener, err := net.Listen("tcp", ":1234")
if err != nil {
log.Fatal("ListenTCP error:", err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Fatal("Accept error:", err)
}
// json编解码器包装
go rpc.ServeCodec(jsonrpc.NewServerCodec(conn))
}
}
server/server.go
package server
import (
"net/rpc"
)
const HelloServiceName = "path/to/pkg.HelloService"
type HelloServiceInterface interface {
Hello(request string, reply *string) error
}
func RegisterHelloService(svc HelloServiceInterface) error {
return rpc.RegisterName(HelloServiceName, svc)
}
type HelloService struct {}
func (p *HelloService) Hello(request string, reply *string) error {
*reply = "hello:" + request
return nil
}
client/test.go
package main
import (
. "../server"
"fmt"
"log"
"net"
"net/rpc"
"net/rpc/jsonrpc"
)
type HelloServiceClient struct {
*rpc.Client
}
//var _ HelloServiceInterface = (*HelloServiceClient)(nil)
func DialHelloService(network, address string) (*HelloServiceClient, error) {
// rpc连接建立在io.ReadWriteCloser接口之上
conn, err := net.Dial(network, address)
if err != nil {
return nil, err
}
// json编解码器包装
client := rpc.NewClientWithCodec(jsonrpc.NewClientCodec(conn))
return &HelloServiceClient{Client: client}, nil
}
func (p *HelloServiceClient) Hello(request string, reply *string) error {
return p.Client.Call(HelloServiceName+".Hello", request, reply)
}
func main() {
client, err := DialHelloService("tcp", "localhost:1234")
if err != nil {
log.Fatal("dialing:", err)
}
var reply string
err = client.Hello("world", &reply)
if err != nil {
log.Fatal(err)
}
fmt.Println(reply)
}
Golang官方rpc
Go官方rpc包是net/rpc, rpc方法必须满足Go rpc规则: 1.公开方法 2.只有两个序列化参数,第二个参数是指针类型 3.返回值是error类型
Golang官方rpc/
├── client
│└── test.go
├── main.go
└── server
└── server.go
2 directories, 3 files
main.go
package main
import (
. "./server"
"log"
"net"
"net/rpc"
)
func main() {
RegisterHelloService(new(HelloService))
listener, err := net.Listen("tcp", ":1234")
if err != nil {
log.Fatal("ListenTCP error:", err)
}
for {
conn, err := listener.Accept()
if err != nil {
log.Fatal("Accept error:", err)
}
go rpc.ServeConn(conn)
}
}
client/test.go
package main
import (
. "../server"
"fmt"
"log"
"net/rpc"
)
type HelloServiceClient struct {
*rpc.Client
}
var _ HelloServiceInterface = (*HelloServiceClient)(nil)
func DialHelloService(network, address string) (*HelloServiceClient, error) {
// 与rpc server建立rpc连接
c, err := rpc.Dial(network, address)
if err != nil {
return nil, err
}
return &HelloServiceClient{Client: c}, nil
}
func (p *HelloServiceClient) Hello(request string, reply *string) error {
// 调用rpc方法
return p.Client.Call(HelloServiceName+".Hello", request, reply)
}
func main() {
client, err := DialHelloService("tcp", "localhost:1234")
if err != nil {
log.Fatal("dialing:", err)
}
var reply string
err = client.Hello("world", &reply)
if err != nil {
log.Fatal(err)
}
fmt.Println(reply)
}
server/server.go
package server
import (
"net/rpc"
)
const HelloServiceName = "path/to/pkg.HelloService"
type HelloServiceInterface interface {
Hello(request string, reply *string) error
}
// rpc.Register将对象类型下所有符合Go rpc规则的方法都注册为rpc方法,
// rpc方法托管在HelloServiceName命名空间下
func RegisterHelloService(svc HelloServiceInterface) error {
return rpc.RegisterName(HelloServiceName, svc)
}
type HelloService struct {}
func (p *HelloService) Hello(request string, reply *string) error {
*reply = "hello:" + request
return nil
}
Set集合
引用来自:k8s.io/apimachinery/pkg/util/sets
package sets
import (
"reflect"
"sort"
)
// Empty is public since it is used by some pkg API objects for conversions between external
// string arrays and pkg sets, and conversion logic requires public types today.
type Empty struct{}
// sets.String is a set of strings, implemented via map[string]struct{} for minimal memory consumption.
type String map[string]Empty
// NewString creates a String from a list of values.
func NewString(items ...string) String {
ss := String{}
ss.Insert(items...)
return ss
}
// StringKeySet creates a String from a keys of a map[string](? extends interface{}).
// If the value passed in is not actually a map, this will panic.
func StringKeySet(theMap interface{}) String {
v := reflect.ValueOf(theMap)
ret := String{}
for _, keyValue := range v.MapKeys() {
ret.Insert(keyValue.Interface().(string))
}
return ret
}
// Insert adds items to the set.
func (s String) Insert(items ...string) {
for _, item := range items {
s[item] = Empty{}
}
}
// Delete removes all items from the set.
func (s String) Delete(items ...string) {
for _, item := range items {
delete(s, item)
}
}
// Has returns true if and only if item is contained in the set.
func (s String) Has(item string) bool {
_, contained := s[item]
return contained
}
// HasAll returns true if and only if all items are contained in the set.
func (s String) HasAll(items ...string) bool {
for _, item := range items {
if !s.Has(item) {
return false
}
}
return true
}
// HasAny returns true if any items are contained in the set.
func (s String) HasAny(items ...string) bool {
for _, item := range items {
if s.Has(item) {
return true
}
}
return false
}
// Difference returns a set of objects that are not in s2
// For example:
// s1 = {a1, a2, a3}
// s2 = {a1, a2, a4, a5}
// s1.Difference(s2) = {a3}
// s2.Difference(s1) = {a4, a5}
func (s String) Difference(s2 String) String {
result := NewString()
for key := range s {
if !s2.Has(key) {
result.Insert(key)
}
}
return result
}
// Union returns a new set which includes items in either s1 or s2.
// For example:
// s1 = {a1, a2}
// s2 = {a3, a4}
// s1.Union(s2) = {a1, a2, a3, a4}
// s2.Union(s1) = {a1, a2, a3, a4}
func (s1 String) Union(s2 String) String {
result := NewString()
for key := range s1 {
result.Insert(key)
}
for key := range s2 {
result.Insert(key)
}
return result
}
// Intersection returns a new set which includes the item in BOTH s1 and s2
// For example:
// s1 = {a1, a2}
// s2 = {a2, a3}
// s1.Intersection(s2) = {a2}
func (s1 String) Intersection(s2 String) String {
var walk, other String
result := NewString()
if s1.Len() < s2.Len() {
walk = s1
other = s2
} else {
walk = s2
other = s1
}
for key := range walk {
if other.Has(key) {
result.Insert(key)
}
}
return result
}
// IsSuperset returns true if and only if s1 is a superset of s2.
func (s1 String) IsSuperset(s2 String) bool {
for item := range s2 {
if !s1.Has(item) {
return false
}
}
return true
}
// Equal returns true if and only if s1 is equal (as a set) to s2.
// Two sets are equal if their membership is identical.
// (In practice, this means same elements, order doesn't matter)
func (s1 String) Equal(s2 String) bool {
return len(s1) == len(s2) && s1.IsSuperset(s2)
}
type sortableSliceOfString []string
func (s sortableSliceOfString) Len() int { return len(s) }
func (s sortableSliceOfString) Less(i, j int) bool { return lessString(s[i], s[j]) }
func (s sortableSliceOfString) Swap(i, j int) { s[i], s[j] = s[j], s[i] }
// List returns the contents as a sorted string slice.
func (s String) List() []string {
res := make(sortableSliceOfString, 0, len(s))
for key := range s {
res = append(res, key)
}
sort.Sort(res)
return []string(res)
}
// UnsortedList returns the slice with contents in random order.
func (s String) UnsortedList() []string {
res := make([]string, 0, len(s))
for key := range s {
res = append(res, key)
}
return res
}
// Returns a single element from the set.
func (s String) PopAny() (string, bool) {
for key := range s {
s.Delete(key)
return key, true
}
var zeroValue string
return zeroValue, false
}
// Len returns the size of the set.
func (s String) Len() int {
return len(s)
}
func lessString(lhs, rhs string) bool {
return lhs < rhs
}
网络开发
netlink库操作
引用来自:github.com/coreos/flannel/pkg/ip/iface.go
package ip
import (
"errors"
"fmt"
"net"
"syscall"
"github.com/vishvananda/netlink"
)
func getIfaceAddrs(iface *net.Interface) ([]netlink.Addr, error) {
link := &netlink.Device{
netlink.LinkAttrs{
Index: iface.Index,
},
}
return netlink.AddrList(link, syscall.AF_INET)
}
func GetIfaceIP4Addr(iface *net.Interface) (net.IP, error) {
addrs, err := getIfaceAddrs(iface)
if err != nil {
return nil, err
}
// prefer non link-local addr
var ll net.IP
for _, addr := range addrs {
if addr.IP.To4() == nil {
continue
}
if addr.IP.IsGlobalUnicast() {
return addr.IP, nil
}
if addr.IP.IsLinkLocalUnicast() {
ll = addr.IP
}
}
if ll != nil {
// didn't find global but found link-local. it'll do.
return ll, nil
}
return nil, errors.New("No IPv4 address found for given interface")
}
func GetIfaceIP4AddrMatch(iface *net.Interface, matchAddr net.IP) error {
addrs, err := getIfaceAddrs(iface)
if err != nil {
return err
}
for _, addr := range addrs {
// Attempt to parse the address in CIDR notation
// and assert it is IPv4
if addr.IP.To4() != nil {
if addr.IP.To4().Equal(matchAddr) {
return nil
}
}
}
return errors.New("No IPv4 address found for given interface")
}
func GetDefaultGatewayIface() (*net.Interface, error) {
routes, err := netlink.RouteList(nil, syscall.AF_INET)
if err != nil {
return nil, err
}
for _, route := range routes {
if route.Dst == nil || route.Dst.String() == "0.0.0.0/0" {
if route.LinkIndex <= 0 {
return nil, errors.New("Found default route but could not determine interface")
}
return net.InterfaceByIndex(route.LinkIndex)
}
}
return nil, errors.New("Unable to find default route")
}
func GetInterfaceByIP(ip net.IP) (*net.Interface, error) {
ifaces, err := net.Interfaces()
if err != nil {
return nil, err
}
for _, iface := range ifaces {
err := GetIfaceIP4AddrMatch(&iface, ip)
if err == nil {
return &iface, nil
}
}
return nil, errors.New("No interface with given IP found")
}
func DirectRouting(ip net.IP) (bool, error) {
routes, err := netlink.RouteGet(ip)
if err != nil {
return false, fmt.Errorf("couldn't lookup route to %v: %v", ip, err)
}
if len(routes) == 1 && routes[0].Gw == nil {
// There is only a single route and there's no gateway (i.e. it's directly connected)
return true, nil
}
return false, nil
}
// EnsureV4AddressOnLink ensures that there is only one v4 Addr on `link` and it equals `ipn`.
// If there exist multiple addresses on link, it returns an error message to tell callers to remove additional address.
func EnsureV4AddressOnLink(ipn IP4Net, link netlink.Link) error {
addr := netlink.Addr{IPNet: ipn.ToIPNet()}
existingAddrs, err := netlink.AddrList(link, netlink.FAMILY_V4)
if err != nil {
return err
}
// flannel will never make this happen. This situation can only be caused by a user, so get them to sort it out.
if len(existingAddrs) > 1 {
return fmt.Errorf("link has incompatible addresses. Remove additional addresses and try again. %#v", link)
}
// If the device has an incompatible address then delete it. This can happen if the lease changes for example.
if len(existingAddrs) == 1 && !existingAddrs[0].Equal(addr) {
if err := netlink.AddrDel(link, &existingAddrs[0]); err != nil {
return fmt.Errorf("failed to remove IP address %s from %s: %s", ipn.String(), link.Attrs().Name, err)
}
existingAddrs = []netlink.Addr{}
}
// Actually add the desired address to the interface if needed.
if len(existingAddrs) == 0 {
if err := netlink.AddrAdd(link, &addr); err != nil {
return fmt.Errorf("failed to add IP address %s to %s: %s", ipn.String(), link.Attrs().Name, err)
}
}
return nil
}
三元表达式
package main
func If(condition bool, trueVal, falseVal interface{}) interface{} {
if condition {
return trueVal
}
return falseVal
}
func main() {
a, b := 2, 3
max := If(a > b, a, b).(int)
println(max)
}
结构体优雅赋值
package main
//参数定义在结构体内部
type Op struct {
userInfo *models.UserInfo
pagination *models.Pagination
state string
}
type OpOption func(*Op)
//变量赋值給实例
func (op *Op) applyOpts(opts []OpOption) {
for _, opt := range opts {
opt(op)
}
}
func WithUserInfo(userInfo *models.UserInfo) OpOption {
return func(op *Op) { op.userInfo = userInfo }
}
func WithPagination(pagination *models.Pagination) OpOption {
return func(op *Op) { op.pagination = pagination }
}
func WithState(state string) OpOption {
return func(op *Op) { op.state = state }
}
func OpGet(opts ...OpOption) Op {
ret := Op{}
ret.applyOpts(opts)
return ret
}
函数
回调函数
回调函数:本质是通过函数指针调用的函数,如函数1作为参数传递给函数2,函数1叫做回调函数,函数2叫做中间函数,调用2的函数叫做起始函数.
回调示例(来自知乎):
有一家旅馆提供叫醒服务,但是要求旅客自己决定叫醒的方法。可以是打客房电话,也可以是派服务员去敲门,睡得死怕耽误事的,还可以要求往自己头上浇盆水。 这里,“叫醒”这个行为是旅馆提供的,相当于中间函数,但是叫醒的方式是由旅客决定并告诉旅馆的,也就是回调函数。而旅客告诉旅馆怎么叫醒自己的动作, 也就是把回调函数传入中间函数的动作,称为登记回调函数(to register a callback function)
你到一个商店买东西,刚好你要的东西没有货,于是你在店员那里留下了你的电话,过了几天店里有货了,店员就打了你的电话,然后你接到电话后就到店里去取了货。 在这个例子里, 你的电话号码就叫回调函数 ,你把电话留给店员就叫登记回调函数,店里后来有货了叫做触发了回调关联的事件 ,店员给你打电话叫做调用回调函数 , 你到店里去取货叫做响应回调事件 。
回调函数类型:
- 阻塞式回调(同步回调)(下面这个例子就是阻塞式回调)
- 延迟式回调(异步回调)
知乎上关于回调的理解不错的帖子: https://www.zhihu.com/question/19801131
package main
import "fmt"
//回调函数
func XX(x int) int {
return x * x
}
//中间函数
//接受一个生成平方数的函数作为参数
func returnXXNumber(x int, getXXNumber func(int) int) int {
return getXXNumber(x)
}
//起始函数
func main() {
x := 2
fmt.Println(returnXXNumber(x, XX))
}
闭包函数
闭包:官方解释(译文)Go函数可以是一个闭包。闭包是一个函数值,它引用了函数体之外的变量。 这个函数可以对这个引用的变量进行访问和赋值;换句话说这个函数被"绑定"在这个变量上。
作用:是缩小变量作用域,降低对全局变量污染的概率
package main
import "fmt"
func add() func(int) int {
sum := 0
return func(x int) int {
sum += x
return sum
}
}
func main() {
//add()就是一个闭包,并赋值给pos和neg,pos的闭包函数和neg的闭包函数被绑定在各自的sum变量上;
//两个闭包函数的sum变量之间没有任何关系
pos, neg := add(), add()
for i := 0; i < 5; i++ {
fmt.Println(
pos(i),
neg(-i),
)
}
}
闭包实现的斐波那契数列
package main
//fibonacci函数完成核心算法、核心数据存储, 不负责for循环
func fibonacci() func() int {
b1 := 1
b2 := 0
bc := 0
return func() int {
bc = b1 + b2
b1 = b2
b2 = bc
return bc
}
}
func main() {
f := fibonacci()
for i := 0; i < 10; i++ {
fmt.Println(f())
}
}
分布式锁
etcd分布式锁
etcd client v3版本中的concurrency包实现了分布式锁, 大致思路是:
- createReVision最小的客户端获得锁
- createReVision越小越早获得锁,部分关键代码如下
等待比当前客户端创建的key的revision小的key的客户端释放锁 // wait for deletion revisions prior to myKey hdr, werr := waitDeletes(ctx, client, m.pfx, m.myRev-1)
引用来自: https://github.com/etcd-io/etcd/blob/master/clientv3/example_kv_test.go
package main
import (
"context"
"fmt"
"log"
"strings"
"time"
"github.com/coreos/etcd/clientv3"
"github.com/coreos/etcd/clientv3/concurrency"
)
var (
endpoints = "http://10.10.10.10:52379"
)
func main() {
cli, err := clientv3.New(clientv3.Config{
Endpoints: strings.Split(endpoints, ","),
DialTimeout: 3 * time.Second,
})
if err != nil {
panic(err)
}
defer cli.Close()
// create two separate sessions for lock competition
s1, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s1.Close()
m1 := concurrency.NewMutex(s1, "/my-lock/")
s2, err := concurrency.NewSession(cli)
if err != nil {
log.Fatal(err)
}
defer s2.Close()
m2 := concurrency.NewMutex(s2, "/my-lock/")
// acquire lock for s1
if err := m1.Lock(context.TODO()); err != nil {
log.Fatal(err)
}
fmt.Println("acquired lock for s1")
m2Locked := make(chan struct{})
go func() {
defer close(m2Locked)
// wait until s1 is locks /my-lock/
if err := m2.Lock(context.TODO()); err != nil {
log.Fatal(err)
}
}()
if err := m1.Unlock(context.TODO()); err != nil {
log.Fatal(err)
}
fmt.Println("released lock for s1")
<-m2Locked
fmt.Println("acquired lock for s2")
// Output:
// acquired lock for s1
// released lock for s1
// acquired lock for s2
}
分页
分页逻辑:
if page > 0 && pageSize > 0 {
Db = Db.Limit(pageSize).Offset((page - 1) * pageSize)
}
接口层分页
func CommonPaginate(x interface{}, offset int, limit int) (int, int) {
xLen := reflect.ValueOf(x).Len()
if offset+1 > xLen {
offset = xLen - 1
if offset < 0 {
offset = 0
}
}
end := offset + limit
if end > xLen {
end = xLen
}
return offset, end
}
发布-订阅模式
引用来自:moby项目提供pubsub简单实现
package main
import (
"fmt"
"github.com/moby/moby/pkg/pubsub"
"strings"
"sync"
"time"
)
func main() {
p := pubsub.NewPublisher(100*time.Millisecond, 10)
golang := p.SubscribeTopic(func(v interface{}) bool {
if key, ok := v.(string); ok {
if strings.HasPrefix(key, "golang:") {
return true
}
}
return false
})
docker := p.SubscribeTopic(func(v interface{}) bool {
if key, ok := v.(string); ok {
if strings.HasPrefix(key, "docker:") {
return true
}
}
return false
})
go p.Publish("hi")
go p.Publish("golang: https://golang.org")
go p.Publish("docker: https://www.docker.com/")
time.Sleep(1)
wg := &sync.WaitGroup{}
wg.Add(2)
go func() {
defer func() {
wg.Done()
}()
fmt.Println("golang topic:", <-golang)
}()
go func() {
defer func() {
wg.Done()
}()
fmt.Println("docker topic:", <-docker)
}()
wg.Wait()
}
定时器
自定义定时器
自定义一种定时器执行任务的job机制,在time Ticker基础上的升级版,大体思路是:
- 定义一个Periodic接口类型
- 定义一个refreshData结构体,实现Periodic接口
- 定义一个DoPeriodic函数,遍历Periodic类型列表
引用来自:https://github.com/helm/monocular
package main
import (
"fmt"
"time"
)
type Periodic interface {
Do() error
Frequency() time.Duration
Name() string
FirstRun() bool
}
type PeriodicCanceller func()
func DoPeriodic(pSlice []Periodic) PeriodicCanceller {
doneCh := make(chan struct{})
for _, p := range pSlice {
go func(p Periodic) {
if p.FirstRun() {
err := p.Do()
if err != nil {
fmt.Printf("periodic job ran and returned error (%s)\n", err)
} else {
fmt.Printf("periodic job %s ran\n", p.Name())
}
}
ticker := time.NewTicker(p.Frequency())
for {
select {
case <-ticker.C:
err := p.Do()
if err != nil {
fmt.Printf("periodic job ran and returned error (%s)\n", err)
}
case <-doneCh:
ticker.Stop()
return
}
}
}(p)
}
return func() {
close(doneCh)
}
}
func NewRefreshData(frequency time.Duration, name string, firstRun bool) Periodic {
return &refreshData{
frequency: frequency,
name: name,
firstRun: firstRun,
}
}
type refreshData struct {
frequency time.Duration
name string
firstRun bool
}
func (r *refreshData) Do() error {
fmt.Printf("time: %s, %s Do xxx\n", time.Now(), r.name)
return nil
}
func (r *refreshData) Frequency() time.Duration {
return r.frequency
}
func (r *refreshData) FirstRun() bool {
return r.firstRun
}
func (r *refreshData) Name() string {
return r.name
}
func main() {
var refreshInterval = 3
freshness := time.Duration(refreshInterval) * time.Second
periodicRefresh := NewRefreshData(freshness, "refresh", false)
newPeriodicRefresh := NewRefreshData(5*time.Second, "test", true)
toDo := []Periodic{periodicRefresh, newPeriodicRefresh}
DoPeriodic(toDo)
select {
}
}
time Ticker实现
比较通用的做法:通过time Ticker获取一个time的channel
package main
import (
"fmt"
"time"
)
func main() {
var (
DefaultInterval = 1
)
done := make(chan bool)
ticker := time.NewTicker(time.Duration(DefaultInterval) * time.Second)
fmt.Println("begin!")
go func() {
for {
select {
case <- done:
fmt.Println("stop!")
ticker.Stop()
return
case <- ticker.C:
fmt.Printf("time: %s, msg: trigger the periodic timer.\n", time.Now())
}
}
}()
time.Sleep(5*time.Second)
done <- true
fmt.Println("end!")
}
k8s定时器实现
引用来自: k8s.io/apimachinery/pkg/util/wait/wait.go
/*
Copyright 2014 The Kubernetes Authors.
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
*/
package wait
import (
"context"
"errors"
"math"
"math/rand"
"sync"
"time"
"k8s.io/apimachinery/pkg/util/runtime"
"k8s.io/utils/clock"
)
// For any test of the style:
// ...
// <- time.After(timeout):
// t.Errorf("Timed out")
// The value for timeout should effectively be "forever." Obviously we don't want our tests to truly lock up forever, but 30s
// is long enough that it is effectively forever for the things that can slow down a run on a heavily contended machine
// (GC, seeks, etc), but not so long as to make a developer ctrl-c a test run if they do happen to break that test.
var ForeverTestTimeout = time.Second * 30
// NeverStop may be passed to Until to make it never stop.
var NeverStop <-chan struct{} = make(chan struct{})
// Group allows to start a group of goroutines and wait for their completion.
type Group struct {
wg sync.WaitGroup
}
func (g *Group) Wait() {
g.wg.Wait()
}
// StartWithChannel starts f in a new goroutine in the group.
// stopCh is passed to f as an argument. f should stop when stopCh is available.
func (g *Group) StartWithChannel(stopCh <-chan struct{}, f func(stopCh <-chan struct{})) {
g.Start(func() {
f(stopCh)
})
}
// StartWithContext starts f in a new goroutine in the group.
// ctx is passed to f as an argument. f should stop when ctx.Done() is available.
func (g *Group) StartWithContext(ctx context.Context, f func(context.Context)) {
g.Start(func() {
f(ctx)
})
}
// Start starts f in a new goroutine in the group.
func (g *Group) Start(f func()) {
g.wg.Add(1)
go func() {
defer g.wg.Done()
f()
}()
}
// Forever calls f every period for ever.
//
// Forever is syntactic sugar on top of Until.
func Forever(f func(), period time.Duration) {
Until(f, period, NeverStop)
}
// Until loops until stop channel is closed, running f every period.
//
// Until is syntactic sugar on top of JitterUntil with zero jitter factor and
// with sliding = true (which means the timer for period starts after the f
// completes).
func Until(f func(), period time.Duration, stopCh <-chan struct{}) {
JitterUntil(f, period, 0.0, true, stopCh)
}
// UntilWithContext loops until context is done, running f every period.
//
// UntilWithContext is syntactic sugar on top of JitterUntilWithContext
// with zero jitter factor and with sliding = true (which means the timer
// for period starts after the f completes).
func UntilWithContext(ctx context.Context, f func(context.Context), period time.Duration) {
JitterUntilWithContext(ctx, f, period, 0.0, true)
}
// NonSlidingUntil loops until stop channel is closed, running f every
// period.
//
// NonSlidingUntil is syntactic sugar on top of JitterUntil with zero jitter
// factor, with sliding = false (meaning the timer for period starts at the same
// time as the function starts).
func NonSlidingUntil(f func(), period time.Duration, stopCh <-chan struct{}) {
JitterUntil(f, period, 0.0, false, stopCh)
}
// NonSlidingUntilWithContext loops until context is done, running f every
// period.
//
// NonSlidingUntilWithContext is syntactic sugar on top of JitterUntilWithContext
// with zero jitter factor, with sliding = false (meaning the timer for period
// starts at the same time as the function starts).
func NonSlidingUntilWithContext(ctx context.Context, f func(context.Context), period time.Duration) {
JitterUntilWithContext(ctx, f, period, 0.0, false)
}
// JitterUntil loops until stop channel is closed, running f every period.
//
// If jitterFactor is positive, the period is jittered before every run of f.
// If jitterFactor is not positive, the period is unchanged and not jittered.
//
// If sliding is true, the period is computed after f runs. If it is false then
// period includes the runtime for f.
//
// Close stopCh to stop. f may not be invoked if stop channel is already
// closed. Pass NeverStop to if you don't want it stop.
func JitterUntil(f func(), period time.Duration, jitterFactor float64, sliding bool, stopCh <-chan struct{}) {
BackoffUntil(f, NewJitteredBackoffManager(period, jitterFactor, &clock.RealClock{}), sliding, stopCh)
}
// BackoffUntil loops until stop channel is closed, run f every duration given by BackoffManager.
//
// If sliding is true, the period is computed after f runs. If it is false then
// period includes the runtime for f.
func BackoffUntil(f func(), backoff BackoffManager, sliding bool, stopCh <-chan struct{}) {
var t clock.Timer
for {
select {
case <-stopCh:
return
default:
}
if !sliding {
t = backoff.Backoff()
}
func() {
defer runtime.HandleCrash()
f()
}()
if sliding {
t = backoff.Backoff()
}
// NOTE: b/c there is no priority selection in golang
// it is possible for this to race, meaning we could
// trigger t.C and stopCh, and t.C select falls through.
// In order to mitigate we re-check stopCh at the beginning
// of every loop to prevent extra executions of f().
select {
case <-stopCh:
if !t.Stop() {
<-t.C()
}
return
case <-t.C():
}
}
}
// JitterUntilWithContext loops until context is done, running f every period.
//
// If jitterFactor is positive, the period is jittered before every run of f.
// If jitterFactor is not positive, the period is unchanged and not jittered.
//
// If sliding is true, the period is computed after f runs. If it is false then
// period includes the runtime for f.
//
// Cancel context to stop. f may not be invoked if context is already expired.
func JitterUntilWithContext(ctx context.Context, f func(context.Context), period time.Duration, jitterFactor float64, sliding bool) {
JitterUntil(func() { f(ctx) }, period, jitterFactor, sliding, ctx.Done())
}
// Jitter returns a time.Duration between duration and duration + maxFactor *
// duration.
//
// This allows clients to avoid converging on periodic behavior. If maxFactor
// is 0.0, a suggested default value will be chosen.
func Jitter(duration time.Duration, maxFactor float64) time.Duration {
if maxFactor <= 0.0 {
maxFactor = 1.0
}
wait := duration + time.Duration(rand.Float64()*maxFactor*float64(duration))
return wait
}
// ErrWaitTimeout is returned when the condition exited without success.
var ErrWaitTimeout = errors.New("timed out waiting for the condition")
// ConditionFunc returns true if the condition is satisfied, or an error
// if the loop should be aborted.
type ConditionFunc func() (done bool, err error)
// ConditionWithContextFunc returns true if the condition is satisfied, or an error
// if the loop should be aborted.
//
// The caller passes along a context that can be used by the condition function.
type ConditionWithContextFunc func(context.Context) (done bool, err error)
// WithContext converts a ConditionFunc into a ConditionWithContextFunc
func (cf ConditionFunc) WithContext() ConditionWithContextFunc {
return func(context.Context) (done bool, err error) {
return cf()
}
}
// runConditionWithCrashProtection runs a ConditionFunc with crash protection
func runConditionWithCrashProtection(condition ConditionFunc) (bool, error) {
return runConditionWithCrashProtectionWithContext(context.TODO(), condition.WithContext())
}
// runConditionWithCrashProtectionWithContext runs a
// ConditionWithContextFunc with crash protection.
func runConditionWithCrashProtectionWithContext(ctx context.Context, condition ConditionWithContextFunc) (bool, error) {
defer runtime.HandleCrash()
return condition(ctx)
}
// Backoff holds parameters applied to a Backoff function.
type Backoff struct {
// The initial duration.
Duration time.Duration
// Duration is multiplied by factor each iteration, if factor is not zero
// and the limits imposed by Steps and Cap have not been reached.
// Should not be negative.
// The jitter does not contribute to the updates to the duration parameter.
Factor float64
// The sleep at each iteration is the duration plus an additional
// amount chosen uniformly at random from the interval between
// zero and `jitter*duration`.
Jitter float64
// The remaining number of iterations in which the duration
// parameter may change (but progress can be stopped earlier by
// hitting the cap). If not positive, the duration is not
// changed. Used for exponential backoff in combination with
// Factor and Cap.
Steps int
// A limit on revised values of the duration parameter. If a
// multiplication by the factor parameter would make the duration
// exceed the cap then the duration is set to the cap and the
// steps parameter is set to zero.
Cap time.Duration
}
// Step (1) returns an amount of time to sleep determined by the
// original Duration and Jitter and (2) mutates the provided Backoff
// to update its Steps and Duration.
func (b *Backoff) Step() time.Duration {
if b.Steps < 1 {
if b.Jitter > 0 {
return Jitter(b.Duration, b.Jitter)
}
return b.Duration
}
b.Steps--
duration := b.Duration
// calculate the next step
if b.Factor != 0 {
b.Duration = time.Duration(float64(b.Duration) * b.Factor)
if b.Cap > 0 && b.Duration > b.Cap {
b.Duration = b.Cap
b.Steps = 0
}
}
if b.Jitter > 0 {
duration = Jitter(duration, b.Jitter)
}
return duration
}
// contextForChannel derives a child context from a parent channel.
//
// The derived context's Done channel is closed when the returned cancel function
// is called or when the parent channel is closed, whichever happens first.
//
// Note the caller must *always* call the CancelFunc, otherwise resources may be leaked.
func contextForChannel(parentCh <-chan struct{}) (context.Context, context.CancelFunc) {
ctx, cancel := context.WithCancel(context.Background())
go func() {
select {
case <-parentCh:
cancel()
case <-ctx.Done():
}
}()
return ctx, cancel
}
// BackoffManager manages backoff with a particular scheme based on its underlying implementation. It provides
// an interface to return a timer for backoff, and caller shall backoff until Timer.C() drains. If the second Backoff()
// is called before the timer from the first Backoff() call finishes, the first timer will NOT be drained and result in
// undetermined behavior.
// The BackoffManager is supposed to be called in a single-threaded environment.
type BackoffManager interface {
Backoff() clock.Timer
}
type exponentialBackoffManagerImpl struct {
backoff *Backoff
backoffTimer clock.Timer
lastBackoffStart time.Time
initialBackoff time.Duration
backoffResetDuration time.Duration
clock clock.Clock
}
// NewExponentialBackoffManager returns a manager for managing exponential backoff. Each backoff is jittered and
// backoff will not exceed the given max. If the backoff is not called within resetDuration, the backoff is reset.
// This backoff manager is used to reduce load during upstream unhealthiness.
func NewExponentialBackoffManager(initBackoff, maxBackoff, resetDuration time.Duration, backoffFactor, jitter float64, c clock.Clock) BackoffManager {
return &exponentialBackoffManagerImpl{
backoff: &Backoff{
Duration: initBackoff,
Factor: backoffFactor,
Jitter: jitter,
// the current impl of wait.Backoff returns Backoff.Duration once steps are used up, which is not
// what we ideally need here, we set it to max int and assume we will never use up the steps
Steps: math.MaxInt32,
Cap: maxBackoff,
},
backoffTimer: nil,
initialBackoff: initBackoff,
lastBackoffStart: c.Now(),
backoffResetDuration: resetDuration,
clock: c,
}
}
func (b *exponentialBackoffManagerImpl) getNextBackoff() time.Duration {
if b.clock.Now().Sub(b.lastBackoffStart) > b.backoffResetDuration {
b.backoff.Steps = math.MaxInt32
b.backoff.Duration = b.initialBackoff
}
b.lastBackoffStart = b.clock.Now()
return b.backoff.Step()
}
// Backoff implements BackoffManager.Backoff, it returns a timer so caller can block on the timer for exponential backoff.
// The returned timer must be drained before calling Backoff() the second time
func (b *exponentialBackoffManagerImpl) Backoff() clock.Timer {
if b.backoffTimer == nil {
b.backoffTimer = b.clock.NewTimer(b.getNextBackoff())
} else {
b.backoffTimer.Reset(b.getNextBackoff())
}
return b.backoffTimer
}
type jitteredBackoffManagerImpl struct {
clock clock.Clock
duration time.Duration
jitter float64
backoffTimer clock.Timer
}
// NewJitteredBackoffManager returns a BackoffManager that backoffs with given duration plus given jitter. If the jitter
// is negative, backoff will not be jittered.
func NewJitteredBackoffManager(duration time.Duration, jitter float64, c clock.Clock) BackoffManager {
return &jitteredBackoffManagerImpl{
clock: c,
duration: duration,
jitter: jitter,
backoffTimer: nil,
}
}
func (j *jitteredBackoffManagerImpl) getNextBackoff() time.Duration {
jitteredPeriod := j.duration
if j.jitter > 0.0 {
jitteredPeriod = Jitter(j.duration, j.jitter)
}
return jitteredPeriod
}
// Backoff implements BackoffManager.Backoff, it returns a timer so caller can block on the timer for jittered backoff.
// The returned timer must be drained before calling Backoff() the second time
func (j *jitteredBackoffManagerImpl) Backoff() clock.Timer {
backoff := j.getNextBackoff()
if j.backoffTimer == nil {
j.backoffTimer = j.clock.NewTimer(backoff)
} else {
j.backoffTimer.Reset(backoff)
}
return j.backoffTimer
}
// ExponentialBackoff repeats a condition check with exponential backoff.
//
// It repeatedly checks the condition and then sleeps, using `backoff.Step()`
// to determine the length of the sleep and adjust Duration and Steps.
// Stops and returns as soon as:
// 1. the condition check returns true or an error,
// 2. `backoff.Steps` checks of the condition have been done, or
// 3. a sleep truncated by the cap on duration has been completed.
// In case (1) the returned error is what the condition function returned.
// In all other cases, ErrWaitTimeout is returned.
func ExponentialBackoff(backoff Backoff, condition ConditionFunc) error {
for backoff.Steps > 0 {
if ok, err := runConditionWithCrashProtection(condition); err != nil || ok {
return err
}
if backoff.Steps == 1 {
break
}
time.Sleep(backoff.Step())
}
return ErrWaitTimeout
}
// Poll tries a condition func until it returns true, an error, or the timeout
// is reached.
//
// Poll always waits the interval before the run of 'condition'.
// 'condition' will always be invoked at least once.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
//
// If you want to Poll something forever, see PollInfinite.
func Poll(interval, timeout time.Duration, condition ConditionFunc) error {
return PollWithContext(context.Background(), interval, timeout, condition.WithContext())
}
// PollWithContext tries a condition func until it returns true, an error,
// or when the context expires or the timeout is reached, whichever
// happens first.
//
// PollWithContext always waits the interval before the run of 'condition'.
// 'condition' will always be invoked at least once.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
//
// If you want to Poll something forever, see PollInfinite.
func PollWithContext(ctx context.Context, interval, timeout time.Duration, condition ConditionWithContextFunc) error {
return poll(ctx, false, poller(interval, timeout), condition)
}
// PollUntil tries a condition func until it returns true, an error or stopCh is
// closed.
//
// PollUntil always waits interval before the first run of 'condition'.
// 'condition' will always be invoked at least once.
func PollUntil(interval time.Duration, condition ConditionFunc, stopCh <-chan struct{}) error {
ctx, cancel := contextForChannel(stopCh)
defer cancel()
return PollUntilWithContext(ctx, interval, condition.WithContext())
}
// PollUntilWithContext tries a condition func until it returns true,
// an error or the specified context is cancelled or expired.
//
// PollUntilWithContext always waits interval before the first run of 'condition'.
// 'condition' will always be invoked at least once.
func PollUntilWithContext(ctx context.Context, interval time.Duration, condition ConditionWithContextFunc) error {
return poll(ctx, false, poller(interval, 0), condition)
}
// PollInfinite tries a condition func until it returns true or an error
//
// PollInfinite always waits the interval before the run of 'condition'.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
func PollInfinite(interval time.Duration, condition ConditionFunc) error {
return PollInfiniteWithContext(context.Background(), interval, condition.WithContext())
}
// PollInfiniteWithContext tries a condition func until it returns true or an error
//
// PollInfiniteWithContext always waits the interval before the run of 'condition'.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
func PollInfiniteWithContext(ctx context.Context, interval time.Duration, condition ConditionWithContextFunc) error {
return poll(ctx, false, poller(interval, 0), condition)
}
// PollImmediate tries a condition func until it returns true, an error, or the timeout
// is reached.
//
// PollImmediate always checks 'condition' before waiting for the interval. 'condition'
// will always be invoked at least once.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
//
// If you want to immediately Poll something forever, see PollImmediateInfinite.
func PollImmediate(interval, timeout time.Duration, condition ConditionFunc) error {
return PollImmediateWithContext(context.Background(), interval, timeout, condition.WithContext())
}
// PollImmediateWithContext tries a condition func until it returns true, an error,
// or the timeout is reached or the specified context expires, whichever happens first.
//
// PollImmediateWithContext always checks 'condition' before waiting for the interval.
// 'condition' will always be invoked at least once.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
//
// If you want to immediately Poll something forever, see PollImmediateInfinite.
func PollImmediateWithContext(ctx context.Context, interval, timeout time.Duration, condition ConditionWithContextFunc) error {
return poll(ctx, true, poller(interval, timeout), condition)
}
// PollImmediateUntil tries a condition func until it returns true, an error or stopCh is closed.
//
// PollImmediateUntil runs the 'condition' before waiting for the interval.
// 'condition' will always be invoked at least once.
func PollImmediateUntil(interval time.Duration, condition ConditionFunc, stopCh <-chan struct{}) error {
ctx, cancel := contextForChannel(stopCh)
defer cancel()
return PollImmediateUntilWithContext(ctx, interval, condition.WithContext())
}
// PollImmediateUntilWithContext tries a condition func until it returns true,
// an error or the specified context is cancelled or expired.
//
// PollImmediateUntilWithContext runs the 'condition' before waiting for the interval.
// 'condition' will always be invoked at least once.
func PollImmediateUntilWithContext(ctx context.Context, interval time.Duration, condition ConditionWithContextFunc) error {
return poll(ctx, true, poller(interval, 0), condition)
}
// PollImmediateInfinite tries a condition func until it returns true or an error
//
// PollImmediateInfinite runs the 'condition' before waiting for the interval.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
func PollImmediateInfinite(interval time.Duration, condition ConditionFunc) error {
return PollImmediateInfiniteWithContext(context.Background(), interval, condition.WithContext())
}
// PollImmediateInfiniteWithContext tries a condition func until it returns true
// or an error or the specified context gets cancelled or expired.
//
// PollImmediateInfiniteWithContext runs the 'condition' before waiting for the interval.
//
// Some intervals may be missed if the condition takes too long or the time
// window is too short.
func PollImmediateInfiniteWithContext(ctx context.Context, interval time.Duration, condition ConditionWithContextFunc) error {
return poll(ctx, true, poller(interval, 0), condition)
}
// Internally used, each of the the public 'Poll*' function defined in this
// package should invoke this internal function with appropriate parameters.
// ctx: the context specified by the caller, for infinite polling pass
// a context that never gets cancelled or expired.
// immediate: if true, the 'condition' will be invoked before waiting for the interval,
// in this case 'condition' will always be invoked at least once.
// wait: user specified WaitFunc function that controls at what interval the condition
// function should be invoked periodically and whether it is bound by a timeout.
// condition: user specified ConditionWithContextFunc function.
func poll(ctx context.Context, immediate bool, wait WaitWithContextFunc, condition ConditionWithContextFunc) error {
if immediate {
done, err := runConditionWithCrashProtectionWithContext(ctx, condition)
if err != nil {
return err
}
if done {
return nil
}
}
select {
case <-ctx.Done():
// returning ctx.Err() will break backward compatibility
return ErrWaitTimeout
default:
return WaitForWithContext(ctx, wait, condition)
}
}
// WaitFunc creates a channel that receives an item every time a test
// should be executed and is closed when the last test should be invoked.
type WaitFunc func(done <-chan struct{}) <-chan struct{}
// WithContext converts the WaitFunc to an equivalent WaitWithContextFunc
func (w WaitFunc) WithContext() WaitWithContextFunc {
return func(ctx context.Context) <-chan struct{} {
return w(ctx.Done())
}
}
// WaitWithContextFunc creates a channel that receives an item every time a test
// should be executed and is closed when the last test should be invoked.
//
// When the specified context gets cancelled or expires the function
// stops sending item and returns immediately.
type WaitWithContextFunc func(ctx context.Context) <-chan struct{}
// WaitFor continually checks 'fn' as driven by 'wait'.
//
// WaitFor gets a channel from 'wait()'', and then invokes 'fn' once for every value
// placed on the channel and once more when the channel is closed. If the channel is closed
// and 'fn' returns false without error, WaitFor returns ErrWaitTimeout.
//
// If 'fn' returns an error the loop ends and that error is returned. If
// 'fn' returns true the loop ends and nil is returned.
//
// ErrWaitTimeout will be returned if the 'done' channel is closed without fn ever
// returning true.
//
// When the done channel is closed, because the golang `select` statement is
// "uniform pseudo-random", the `fn` might still run one or multiple time,
// though eventually `WaitFor` will return.
func WaitFor(wait WaitFunc, fn ConditionFunc, done <-chan struct{}) error {
ctx, cancel := contextForChannel(done)
defer cancel()
return WaitForWithContext(ctx, wait.WithContext(), fn.WithContext())
}
// WaitForWithContext continually checks 'fn' as driven by 'wait'.
//
// WaitForWithContext gets a channel from 'wait()'', and then invokes 'fn'
// once for every value placed on the channel and once more when the
// channel is closed. If the channel is closed and 'fn'
// returns false without error, WaitForWithContext returns ErrWaitTimeout.
//
// If 'fn' returns an error the loop ends and that error is returned. If
// 'fn' returns true the loop ends and nil is returned.
//
// context.Canceled will be returned if the ctx.Done() channel is closed
// without fn ever returning true.
//
// When the ctx.Done() channel is closed, because the golang `select` statement is
// "uniform pseudo-random", the `fn` might still run one or multiple times,
// though eventually `WaitForWithContext` will return.
func WaitForWithContext(ctx context.Context, wait WaitWithContextFunc, fn ConditionWithContextFunc) error {
waitCtx, cancel := context.WithCancel(context.Background())
defer cancel()
c := wait(waitCtx)
for {
select {
case _, open := <-c:
ok, err := runConditionWithCrashProtectionWithContext(ctx, fn)
if err != nil {
return err
}
if ok {
return nil
}
if !open {
return ErrWaitTimeout
}
case <-ctx.Done():
// returning ctx.Err() will break backward compatibility
return ErrWaitTimeout
}
}
}
// poller returns a WaitFunc that will send to the channel every interval until
// timeout has elapsed and then closes the channel.
//
// Over very short intervals you may receive no ticks before the channel is
// closed. A timeout of 0 is interpreted as an infinity, and in such a case
// it would be the caller's responsibility to close the done channel.
// Failure to do so would result in a leaked goroutine.
//
// Output ticks are not buffered. If the channel is not ready to receive an
// item, the tick is skipped.
func poller(interval, timeout time.Duration) WaitWithContextFunc {
return WaitWithContextFunc(func(ctx context.Context) <-chan struct{} {
ch := make(chan struct{})
go func() {
defer close(ch)
tick := time.NewTicker(interval)
defer tick.Stop()
var after <-chan time.Time
if timeout != 0 {
// time.After is more convenient, but it
// potentially leaves timers around much longer
// than necessary if we exit early.
timer := time.NewTimer(timeout)
after = timer.C
defer timer.Stop()
}
for {
select {
case <-tick.C:
// If the consumer isn't ready for this signal drop it and
// check the other channels.
select {
case ch <- struct{}{}:
default:
}
case <-after:
return
case <-ctx.Done():
return
}
}
}()
return ch
})
}
// ExponentialBackoffWithContext works with a request context and a Backoff. It ensures that the retry wait never
// exceeds the deadline specified by the request context.
func ExponentialBackoffWithContext(ctx context.Context, backoff Backoff, condition ConditionFunc) error {
for backoff.Steps > 0 {
select {
case <-ctx.Done():
return ctx.Err()
default:
}
if ok, err := runConditionWithCrashProtection(condition); err != nil || ok {
return err
}
if backoff.Steps == 1 {
break
}
waitBeforeRetry := backoff.Step()
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(waitBeforeRetry):
}
}
return ErrWaitTimeout
}
捕获Goroutine异常
无缓冲channel实现
定义一个包含Error的struct,再定义一个无缓冲的channel实现同步传递
package main
type Result struct {
Error error
}
func updateNode(node string) error {
return nil
}
func main() {
nodeList := make([]string, 10)
checkStatus := func(done <-chan interface{}, nodeList ...string) <-chan Result {
results := make(chan Result)
go func() {
defer close(results)
for _, node := range nodeList {
var result Result
// update node
err := updateNode(node)
result = Result{Error: err}
select {
case <- done:
return
case results <- result:
}
}
}()
return results
}
done := make(chan interface{})
defer close(done)
for result := range checkStatus(done, nodeList...) {
if result.Error != nil {
panic(result.Error)
}
}
}
sync errgroup实现
使用sync包提供的errgroup, errgroup提供同步,error收集,可使用context取消正处于任务中运行的goroutines. errgroup可直接看源码,源码比较简短
package main
func main() {
ctx, cancel := context.WithTimeout(context.Background(), thresholdTime)
defer cancel()
g, ctx := errgroup.WithContext(ctx)
if felixLive {
g.Go(func() error {
if err := checkFelixHealth(ctx, felixLivenessEp, "liveness"); err != nil {
return fmt.Errorf("calico/node is not ready: Felix is not live: %+v", err)
}
return nil
})
}
if birdLive {
g.Go(func() error {
if err := checkServiceIsLive([]string{"confd", "bird"}); err != nil {
return fmt.Errorf("calico/node is not ready: bird/confd is not live: %+v", err)
}
return nil
})
}
if bird6Live {
g.Go(func() error {
if err := checkServiceIsLive([]string{"confd", "bird6"}); err != nil {
return fmt.Errorf("calico/node is not ready: bird6/confd is not live: %+v", err)
}
return nil
})
}
if felixReady {
g.Go(func() error {
if err := checkFelixHealth(ctx, felixReadinessEp, "readiness"); err != nil {
return fmt.Errorf("calico/node is not ready: felix is not ready: %+v", err)
}
return nil
})
}
if bird {
g.Go(func() error {
if err := checkBIRDReady("4", thresholdTime); err != nil {
return fmt.Errorf("calico/node is not ready: BIRD is not ready: %+v", err)
}
return nil
})
}
if bird6 {
g.Go(func() error {
if err := checkBIRDReady("6", thresholdTime); err != nil {
return fmt.Errorf("calico/node is not ready: BIRD6 is not ready: %+v", err)
}
return nil
})
}
if err := g.Wait(); err != nil {
fmt.Printf("%s", err)
os.Exit(1)
}
}
加锁Slice实现
定义一个error类型的Slice, 通过加读写锁对它进行操作
引用来自:kubernetes/pkg/scheduler/core/generic_scheduler.go的代码片段
package main
func main() {
/*
var (
mu = sync.Mutex{}
wg = sync.WaitGroup{}
errs []error
)
appendError := func(err error) {
mu.Lock()
defer mu.Unlock()
errs = append(errs, err)
}
results := make([]schedulerapi.HostPriorityList, len(priorityConfigs), len(priorityConfigs))
// DEPRECATED: we can remove this when all priorityConfigs implement the
// Map-Reduce pattern.
for i := range priorityConfigs {
if priorityConfigs[i].Function != nil {
wg.Add(1)
go func(index int) {
defer wg.Done()
var err error
results[index], err = priorityConfigs[index].Function(pod, nodeNameToInfo, nodes)
if err != nil {
appendError(err)
}
}(i)
} else {
results[i] = make(schedulerapi.HostPriorityList, len(nodes))
}
}
// Wait for all computations to be finished.
wg.Wait()
if len(errs) != 0 {
return schedulerapi.HostPriorityList{}, errors.NewAggregate(errs)
}
*/
}
goroutine池
通过sync.WaitGroup + channel控制数量
引用来自:k8s.io/client-go/util/workqueue/parallelizer.go
package workqueue
import (
"context"
"sync"
utilruntime "k8s.io/apimachinery/pkg/util/runtime"
)
type DoWorkPieceFunc func(piece int)
type options struct {
chunkSize int
}
type Options func(*options)
// WithChunkSize allows to set chunks of work items to the workers, rather than
// processing one by one.
// It is recommended to use this option if the number of pieces significantly
// higher than the number of workers and the work done for each item is small.
func WithChunkSize(c int) func(*options) {
return func(o *options) {
o.chunkSize = c
}
}
// ParallelizeUntil is a framework that allows for parallelizing N
// independent pieces of work until done or the context is canceled.
func ParallelizeUntil(ctx context.Context, workers, pieces int, doWorkPiece DoWorkPieceFunc, opts ...Options) {
if pieces == 0 {
return
}
o := options{}
for _, opt := range opts {
opt(&o)
}
chunkSize := o.chunkSize
if chunkSize < 1 {
chunkSize = 1
}
chunks := ceilDiv(pieces, chunkSize)
toProcess := make(chan int, chunks)
for i := 0; i < chunks; i++ {
toProcess <- i
}
//不影响读
close(toProcess)
var stop <-chan struct{}
if ctx != nil {
stop = ctx.Done()
}
if chunks < workers {
workers = chunks
}
wg := sync.WaitGroup{}
wg.Add(workers)
for i := 0; i < workers; i++ {
go func() {
defer utilruntime.HandleCrash()
defer wg.Done()
//并发从channel中读取
for chunk := range toProcess {
start := chunk * chunkSize
end := start + chunkSize
if end > pieces {
end = pieces
}
for p := start; p < end; p++ {
select {
case <-stop:
return
default:
doWorkPiece(p)
}
}
}
}()
}
wg.Wait()
}
func ceilDiv(a, b int) int {
return (a + b - 1) / b
}
无锁栈
atomic实现
package main
import (
"sync/atomic"
"unsafe"
)
// LFStack 无锁栈
// 使用链表实现
type LFStack struct {
head unsafe.Pointer // 栈顶
}
// Node 节点
type Node struct {
val int32
next unsafe.Pointer
}
// NewLFStack NewLFStack
func NewLFStack() *LFStack {
n := unsafe.Pointer(&Node{})
return &LFStack{head: n}
}
// Push 入栈
func (s *LFStack) Push(v int32) {
n := &Node{val: v}
for {
// 先取出栈顶
old := atomic.LoadPointer(&s.head)
n.next = old
if atomic.CompareAndSwapPointer(&s.head, old, unsafe.Pointer(n)) {
return
}
}
}
// Pop 出栈,没有数据时返回 nil
func (s *LFStack) Pop() int32 {
for {
// 先取出栈顶
old := atomic.LoadPointer(&s.head)
if old == nil {
return 0
}
oldNode := (*Node)(old)
// 取出下一个节点
next := atomic.LoadPointer(&oldNode.next)
// 重置栈顶
if atomic.CompareAndSwapPointer(&s.head, old, next) {
return oldNode.val
}
}
}
消费者-生产者-工作队列模式
channel实现
一个任务的执行过程如下:
- JobQueue <- work 新任务入队
- job := <-JobQueue: 调度中心收到任务
- jobChannel := <-d.WorkerPool 从工作者池取到一个工作者
- jobChannel <- job 任务给到工作者
- job := <-w.JobChannel 工作者取出任务
- {{1}} 执行任务
- w.WorkerPool <- w.JobChannel 工作者在放回工作者池
package main
import (
"fmt"
"reflect"
"runtime"
"time"
)
var (
MaxWorker = 10
)
type Payload struct {
Num int
}
//待执行的工作
type Job struct {
Payload Payload
}
//任务channal
var JobQueue chan Job
//执行任务的工作者单元
type Worker struct {
WorkerPool chan chan Job //工作者池--每个元素是一个工作者的私有任务channal
JobChannel chan Job //每个工作者单元包含一个任务管道 用于获取任务
quit chan bool //退出信号
no int //编号
}
//创建一个新工作者单元
func NewWorker(workerPool chan chan Job, no int) Worker {
fmt.Println("创建了工作者", no)
return Worker{
WorkerPool: workerPool,
JobChannel: make(chan Job),
quit: make(chan bool),
no: no,
}
}
//循环监听任务和结束信号
func (w Worker) Start() {
go func() {
for {
// register the current worker into the worker queue.
w.WorkerPool <- w.JobChannel
fmt.Println("w.WorkerPool <- w.JobChannel", w)
select {
case job := <-w.JobChannel:
fmt.Println("job := <-w.JobChannel")
// 收到任务
fmt.Println(job)
time.Sleep(100 * time.Second)
case <-w.quit:
// 收到退出信号
return
}
}
}()
}
// 停止信号
func (w Worker) Stop() {
go func() {
w.quit <- true
}()
}
//调度中心
type Dispatcher struct {
//工作者池
WorkerPool chan chan Job
//工作者数量
MaxWorkers int
}
//创建调度中心
func NewDispatcher(maxWorkers int) *Dispatcher {
pool := make(chan chan Job, maxWorkers)
return &Dispatcher{WorkerPool: pool, MaxWorkers: maxWorkers}
}
//工作者池的初始化
func (d *Dispatcher) Run() {
// starting n number of workers
for i := 1; i < d.MaxWorkers+1; i++ {
worker := NewWorker(d.WorkerPool, i)
worker.Start()
}
go d.dispatch()
}
//调度
func (d *Dispatcher) dispatch() {
for {
select {
case job := <-JobQueue:
fmt.Println("job := <-JobQueue:")
go func(job Job) {
//等待空闲worker (任务多的时候会阻塞这里)
jobChannel := <-d.WorkerPool
fmt.Println("jobChannel := <-d.WorkerPool", reflect.TypeOf(jobChannel))
// 将任务放到上述woker的私有任务channal中
jobChannel <- job
fmt.Println("jobChannel <- job")
}(job)
}
}
}
func main() {
JobQueue = make(chan Job, 10)
dispatcher := NewDispatcher(MaxWorker)
dispatcher.Run()
time.Sleep(1 * time.Second)
go addQueue()
time.Sleep(1000 * time.Second)
}
func addQueue() {
for i := 0; i < 20; i++ {
// 新建一个任务
payLoad := Payload{Num: i}
work := Job{Payload: payLoad}
// 任务放入任务队列channal
JobQueue <- work
fmt.Println("JobQueue <- work", i)
fmt.Println("当前协程数:", runtime.NumGoroutine())
time.Sleep(100 * time.Millisecond)
}
}
控制并发数的channel实现
在job_worker基础上扩展,增加DispatchNumControl分发控制数,activeAccount worker活跃数控制, 不过会丢部分job
引用来自:http://blog.cocosdever.com/2018/08/22/goroutine-channel-Job-Worker-mode
package main
import (
"fmt"
"runtime"
"time"
)
// 定义一些全局常量
var (
MaxWorker = 10
MaxDispatchNumControl = 20
)
// Payload 任务里面的负载
type Payload struct {
Num int
}
// Job 任务结构体
type Job struct {
Payload Payload
}
// JobQueue 定义全局Job队列, 新增加的任务就丢进该任务队列即可
var JobQueue chan Job
// WorkerList 工作单元切片
var WorkerList []*Worker
//用于控制并发处理的协程数
var DispatchNumControl chan bool
func Limit(job Job) bool {
select {
case <-time.After(time.Millisecond * 100):
fmt.Println("我很忙")
return false
case DispatchNumControl <- true:
// 任务放入全局任务队列channal
JobQueue <- job
return true
}
}
// Worker 工作者单元, 用于执行Job的单元, 数量有限, 由调度中心分配
type Worker struct {
WorkerPool chan chan Job //存放JobChan的池子
JobChan chan Job
quit chan bool
No int
}
// NewWorker 创建工作单元
func NewWorker(workerPool chan chan Job, no int) *Worker {
fmt.Println("创建了工作者", no)
return &Worker{
WorkerPool: workerPool,
JobChan: make(chan Job),
quit: make(chan bool),
No: no,
}
}
// Start 开始工作
func (w *Worker) Start() {
go func() {
for {
// 注册JobChan到工作池中, 然后开始工作循环
w.WorkerPool <- w.JobChan
fmt.Println("w.WorkerPool <- w.JobChan | w:", w)
//如果有工作进来就执行工作, 收到退出信号就退出
select {
case job := <-w.JobChan:
//收到job, 开始工作
fmt.Println("job := <-w.JobChan")
fmt.Println(job)
//完成之后释放控制中心额度
<-DispatchNumControl
time.Sleep(5 * time.Second)
case <-w.quit:
fmt.Println("<-w.Quit | w:", w)
return
}
}
}()
}
// Stop 暂停工作
func (w *Worker) Stop() {
go func() {
w.quit <- true
}()
}
// Dispatcher 调度中心, 用于创建工作单元Worker, 安排Worker执行Job
type Dispatcher struct {
WorkerPool chan chan Job
MaxWorkers int
ActiveCount int
}
// NewDispatcher 创建调度中心
func NewDispatcher(max int) *Dispatcher {
return &Dispatcher{
WorkerPool: make(chan chan Job, max),
MaxWorkers: max,
}
}
// Run 根据MaxWorkers, 创建工作者, 同时让工作者运行起来
func (d *Dispatcher) Run() {
for i := 0; i < d.MaxWorkers; i++ {
worker := NewWorker(d.WorkerPool, i)
worker.Start()
// 将工作单元存进切片中
WorkerList[i] = worker
d.ActiveCount++
}
go d.dispatcher()
}
// dispatcher 读取全局job队列, 开始分配任务
func (d *Dispatcher) dispatcher() {
for {
select {
case job := <-JobQueue:
go func(job Job) {
// 从池中找到一个空闲的JobChan, 如果没有空闲的就会堵塞
jobChan := <-d.WorkerPool
fmt.Println("jobChan := <-d.WorkerPool")
//把job丢给工作者
jobChan <- job
//每次丢进一个job给工作者之后, 就删除一个工作者, 直到工作者数量维持在5个
fmt.Println("d.ActiveCount: ", d.ActiveCount)
if d.ActiveCount > 5 {
worker := WorkerList[d.ActiveCount-1]
fmt.Println("worker := WorkerList[d.ActiveCount-1] | worker: ", worker)
worker.Stop()
d.ActiveCount--
}
}(job)
}
}
}
// AddQueue 往全局队列中添加job
func AddQueue(n int) {
for i := 0; i < n; i++ {
job := Job{Payload{i}}
fmt.Println("JobQueue <- job", job)
// 只有在DispatchNumControl缓冲还未满的时候, 才能将job加入到JobQueue中
// 因为一旦加入到JobQueue之后, 系统立马会将job从队头取出, 分配一个协程去单独处理后续的工作
// 为了避免协程数量过多, 所以使用Lmit函数做总体控制
if Limit(job) {
fmt.Println("任务成功加入全局队列")
} else {
fmt.Println("全局队列已满, 暂不处理任务")
i--
}
fmt.Println("当前协程数:", runtime.NumGoroutine())
time.Sleep(200 * time.Millisecond)
}
}
func main() {
DispatchNumControl = make(chan bool, MaxDispatchNumControl)
JobQueue = make(chan Job)
WorkerList = make([]*Worker, 10)
disp := NewDispatcher(MaxWorker)
disp.Run()
time.Sleep(1 * time.Second)
AddQueue(100)
fmt.Println()
time.Sleep(1000 * time.Second)
}
gin教程
引用来自:https://github.com/gin-gonic/gin/blob/master/README.md
泛型编程
Go 1.17版本开始支持泛型,再也不需要使用反射来实现了
初体验
使用[T any]来声明一个泛型,一个通用函数可实现打印不同类型的变量
package main
import "fmt"
func print[T any](arr []T) {
for _, v := range arr {
fmt.Println(v)
}
}
func main() {
str := []string{"a", "b", "c"}
flat := []float64{1.1, 1.2, 1.3}
nums := []int{1, 2, 3}
print(str)
print(flat)
print(nums)
}
运行需要加上-gcflags=-G=3编译参数(golang 1.18版本会成为默认)
go run -gcflags=-G=3 ./main.go
一个泛型实现的通用查询函数,使用[T comparable]的格式,comparable是一个接口类型,要求我们的类型需要支持==的操作
package main
import "fmt"
func find[T comparable](arr []T, target T) {
for k, v := range arr {
if v == target {
fmt.Printf("found %v at %d\n", target, k)
}
}
}
func main() {
find([]int{1,2,3}, 2)
find([]string{"a","bcd","efg"}, "a")
}
这个find函数依赖于数组,对于其它数据结构,比如链表、栈等需要重写
泛型栈
package main
import "fmt"
type stack [T any] []T
func(s *stack[T]) push(elem T) {
*s = append(*s, elem)
}
func(s *stack[T]) pop() {
if len(*s) > 0 {
*s = (*s)[:len(*s)-1]
}
}
//判断栈是否为空
func(s *stack[T]) top() *T{
if len(*s) > 0 {
return &(*s)[len(*s)-1]
}
return nil
}
func(s *stack[T]) len() int{
return len(*s)
}
func(s *stack[T]) print() {
for _, elem := range *s {
fmt.Println(elem)
}
}
func main() {
ss := stack[string]{}
ss.push("a")
ss.push("b")
ss.push("c")
ss.print()
fmt.Printf("stack top is - %v\n", *ss.top())
ss.pop()
ss.pop()
ss.print()
}
为什么函数名都是小写?当前Go泛型函数不支持被其它包引用
泛型双向链表
package main
import (
"fmt"
)
type node[T comparable] struct {
data T
prev *node[T]
next *node[T]
}
type list[T comparable] struct {
head, tail *node[T]
len int
}
func(l *list[T]) isEmpty() bool {
return l.head == nil && l.tail == nil
}
//从头插入
func(l *list[T]) add(data T) {
n := &node[T]{
data: data,
prev: nil,
next: l.head,
}
if l.isEmpty() {
l.head = n
l.tail = n
}
l.head.prev = n
l.head = n
}
//从尾插入
func (l *list[T]) push(data T) {
n := &node[T] {
data : data,
prev : l.tail,
next : nil,
}
if l.isEmpty() {
l.head = n
l.tail = n
}
l.tail.next = n
l.tail = n
}
//删除一个节点,注意边界处理
func (l *list[T]) del(data T) {
for p := l.head; p != nil; p = p.next {
if data == p.data {
if p == l.head {
l.head = p.next
}
if p == l.tail {
l.tail = p.prev
}
if p.prev != nil {
p.prev.next = p.next
}
if p.next != nil {
p.next.prev = p.prev
}
return
}
}
}
func (l *list[T]) print() {
if l.isEmpty() {
fmt.Println("linklist is empty.")
return
}
for p := l.head; p != nil; p = p.next {
fmt.Printf("[%v]-->", p.data)
}
fmt.Println("end")
}
func main() {
l := list[int]{}
l.add(1)
l.add(2)
l.push(3)
l.push(4)
l.add(5)
l.print()
l.del(1)
l.del(3)
l.print()
}
泛型Map
package main
import (
"fmt"
"strings"
)
func fMap[T1 any, T2 any](arr []T1, f func(T1) T2) []T2 {
s := make([]T2, len(arr))
for k,v := range arr {
s[k] = f(v)
}
return s
}
func main() {
strs := []string{"I", "am", "yao"}
upstrs := fMap(strs, func(s string) string {
return strings.ToUpper(s)
})
fmt.Println(upstrs)
}
- T1: 需要处理的数据类型
- T2: 处理后的数据类型
- f func(T1) T2):T1经过的函数然后转变为T2
泛型Reduce
数组求和
package main
import (
"fmt"
)
func fReduce[T1 any, T2 any](arr []T1, init T2, f func(T1, T2) T2) T2 {
s := init
for _, v := range arr {
s = f(v, s)
}
return s
}
func main() {
nums := []int{0,1,2,3,4}
sum := fReduce(nums, 0, func(result, elem int) int {
return result + elem
})
fmt.Printf("Sum = %d \n", sum)
}
泛型Filter
package main
import (
"fmt"
)
func fFilter[T any](arr []T, in bool, f func(T) bool) []T {
s := []T{}
for _, v := range arr {
target := f(v)
if (in && target) || (!in && !target) {
s = append(s, v)
}
}
return s
}
func fFilterTrue[T any](arr []T, f func(T) bool) []T {
return fFilter(arr, true, f)
}
func fFilterFalse[T any](arr []T, f func(T) bool) []T {
return fFilter(arr, false, f)
}
func main() {
nums := []int{0,1,2,3,4,5}
result := fFilterTrue(nums, func (elem int) bool {
return elem % 2 == 1
})
fmt.Println(result)
result = fFilterFalse(nums, func (elem int) bool {
return elem % 2 == 1
})
fmt.Println(result)
}
优雅关闭Goroutine
返回ctx的SignalHandler
var onlyOneSignalHandler = make(chan struct{})
// SetupSignalHandler registers for SIGTERM and SIGINT. A stop channel is returned
// which is closed on one of these signals. If a second signal is caught, the program
// is terminated with exit code 1.
func SetupSignalHandler() context.Context {
close(onlyOneSignalHandler) // panics when called twice
ctx, cancel := context.WithCancel(context.Background())
c := make(chan os.Signal, 2)
signal.Notify(c, shutdownSignals...)
go func() {
<-c
cancel()
<-c
os.Exit(1) // second signal. Exit directly.
}()
return ctx
}
检测结构体是否有这个方法
不使用reflect检测结构体是否有这个方法
package main
import "fmt"
type A int
type B int
func (b B) M(x int) string {
return fmt.Sprint(b, ": ", x)
}
func check(v interface{}) bool {
_, has := v.(interface{M(int) string})
return has
}
func main() {
var a A = 123
var b B = 789
fmt.Println(check(a)) // false
fmt.Println(check(b)) // true
}
json.Decoder vs json.Unmarshal
- Use json.Decoder if your data is coming from an io.Reader stream, or you need to decode multiple values from a stream of data.
- Use json.Unmarshal if you already have the JSON data in memory.
如果是从http请求的流中读取,使用json.Decoder; 如果json数据已在内存中,使用json.Unmarshal
interface判断为nil
package main
import "fmt"
func main(){
var a interface{} = nil
var b interface{} = (*string)(nil)
fmt.Println(a==nil)
fmt.Println(b==nil)
}
输出为
true
false
为什么会出现这样的结果呢?跟interface的底层结构有关,一个接口包括动态类型和动态值。通过x!=nil只是判断了动态类型,并没有判断动态值;
显式指明nil,动态类型和动态值都为nil,所以输出true;使用强制类型指明(*string)nil,动态类型不为nil,动态值为nil,所以输出为false.
interface底层实现:分为两种struct来表示,iface和eface
eface表示不含method的interface结构(empty interface)
type eface struct {
_type *_type
data unsafe.Pointer
}
type _type struct {
size uintptr // type size
ptrdata uintptr // size of memory prefix holding all pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldalign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
alg *typeAlg // algorithm table
gcdata *byte // garbage collection data
str nameOff // string form
ptrToThis typeOff // type for pointer to this type, may be zero
}
iface表示non-empty interface的底层实现, non-empty要包含method
type iface struct {
tab *itab
data unsafe.Pointer
}
// layout of Itab known to compilers
// allocated in non-garbage-collected memory
// Needs to be in sync with
// ../cmd/compile/internal/gc/reflect.go:/^func.dumptypestructs.
type itab struct {
inter *interfacetype
_type *_type
link *itab
bad int32
inhash int32 // has this itab been added to hash?
fun [1]uintptr // variable sized
}
可以借助反射来判断
func IsNil(i interface{}) bool {
vi := reflect.ValueOf(i)
if vi.Kind() == reflect.Ptr {
return vi.IsNil()
}
return false
}
自动转化时间格式
func (b *T) MarshalJSON() ([]byte, error) {
type tmp T
return json.Marshal(&struct {
*tmp
CreatedAt string `json:"created_at"`
UpdatedAt string `json:"updated_at"`
ExpireTime string `json:"expire_time"`
}{
tmp: (*tmp)(b),
CreatedAt: b.CreatedAt.Local().Format(DefaultTimeFormat),
UpdatedAt: b.UpdatedAt.Local().Format(DefaultTimeFormat),
ExpireTime: b.ExpireTime.Local().Format(DefaultTimeFormat),
})
}
func (b *T) UnmarshalJSON(data []byte) error {
type tmp T
origin := &struct {
*tmp
CreatedAt string `json:"created_at"`
UpdatedAt string `json:"updated_at"`
ExpireTime string `json:"expire_time"`
}{
tmp: (*tmp)(b),
}
if err := json.Unmarshal(data, origin); err != nil {
return err
}
createdAt, err := time.Parse(DefaultTimeFormat, origin.CreatedAt)
if err != nil {
return err
}
b.CreatedAt = createdAt
updatedAt, err := time.Parse(DefaultTimeFormat, origin.UpdatedAt)
if err != nil {
return err
}
b.UpdatedAt = updatedAt
expireTime, err := time.Parse(DefaultTimeFormat, origin.ExpireTime)
if err != nil {
return err
}
b.ExpireTime = expireTime
return nil
}
如何计算结构体占用的空间
package main
import (
"fmt"
"unsafe"
)
type test1 struct {
num1 int
num2 int
}
type test2 struct {
num1 int16
num2 int32
}
func main() {
fmt.Println(unsafe.Sizeof(test1{}))
fmt.Println(unsafe.Sizeof(test2{}))
}
运行结果:
16
8
test1结构体int类型在64位机器上占8字节,test1结构占16字节;test2结构体int16占2字节,int32占4字节,总共6字节。为什么不是8字节? 这是因为内存对齐的缘故,CPU 访问内存时,并不是逐个字节访问,而是以字长(word size)为单位访问。比如32位的CPU ,字长为4字节。 这么设计的目的,是减少 CPU 访问内存的次数,加大CPU访问内存的吞吐量。合理的内存对齐可以提高内存读写的性能,并且便于实现变量操作的原子性。
unsafe库提供Alignof方法查看一个类型的对齐值(对齐系数、对齐倍数),golang官方文档有针对这个的说明,总结:
- 对于任意类型的变量 x ,unsafe.Alignof(x) 至少为 1。
- 对于 struct 结构体类型的变量 x,计算x每一个字段f的unsafe.Alignof(x.f),unsafe.Alignof(x)等于其中的最大值。但至少为1
- 对于 array 数组类型的变量 x,unsafe.Alignof(x) 等于构成数组的元素类型的对齐倍数。 没有任何字段的空 struct{} 和没有任何元素的 array 占据的内存空间大小为 0,不同的大小为 0 的变量可能指向同一块地址。
struct内存对齐技巧
合理放置变量位置减少内存占用
package main
import (
"fmt"
"unsafe"
)
//假设字长为4字节
type test1 struct {
a int8 //a和下面的b加起来为3字节,补齐1个字节凑齐一个字长
b int16
c int32 //c刚好一个字长
}
type test2 struct {
a int8 //a和下面的b加起来超过一个字长的字节,所以a单独补齐3个字节
c int32 //c刚好一个字长
b int16 //b补齐2个字节,凑齐一个字长
}
func main() {
fmt.Println(unsafe.Sizeof(test1{})) // 8
fmt.Println(unsafe.Sizeof(test2{})) // 12
}
运行结果为8和12
空struct{}的对齐
struct{}作为其它struct最后一个字段时,需要填充额外的内存保证安全
package main
import (
"fmt"
"unsafe"
)
type test1 struct {
c int32
a struct{}
}
type test2 struct {
a struct{}
c int32
}
func main() {
fmt.Println(unsafe.Sizeof(test1{})) // 8
fmt.Println(unsafe.Sizeof(test2{})) // 4
}
运行结果为8和4,test1的struct{}额外占用一个字长
sync.Pool临时对象池
为什么需要sync.Pool?保存和复用临时对象,减少内存分配,降低GC压力。
import (
"sync"
"testing"
)
type A struct {
Name string
}
func (a *A) Reset() {
a.Name = ""
}
var pool = sync.Pool{
New: func() interface{} {
return new(A)
},
}
func BenchmarkWithoutPool(b *testing.B) {
var a *A
b.ReportAllocs()
b.ResetTimer()
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
a = new(A)
a.Name = "tink"
}
}
}
func BenchmarkWithPool(b *testing.B) {
var a *A
b.ReportAllocs()
b.ResetTimer()
for i := 0; i < b.N; i++ {
for j := 0; j < 10000; j++ {
a = pool.Get().(*A)
a.Reset()
a.Name = "tink"
pool.Put(a)
}
}
}
# go test -benchmem -run=^$ -bench .
goos: darwin
goarch: amd64
pkg: test/syncpool
cpu: Intel(R) Core(TM) i7-4770HQ CPU @ 2.20GHz
BenchmarkWithoutPool-8 3955 307508 ns/op 160000 B/op 10000 allocs/op
BenchmarkWithPool-8 7032 148487 ns/op 0 B/op 0 allocs/op
PASS
ok test/syncpool 3.491s
运行耗时节省了一半以上,内存分配为0,内存分配次数也为0
注册模式
slice方式注册,来自github.com/bitpoke/mysql-operator代码片段
多controller运行例子:
// Setup all Controllers
if err := controller.AddToManager(mgr); err != nil {
log.Error(err, "unable to setup controllers")
os.Exit(1)
}
定义一个AddToManagerFuncs变量存放函数组,AddToManager遍历AddToManagerFuncs,并执行其函数
// AddToManagerFuncs is a list of functions to add all Controllers to the Manager
var AddToManagerFuncs []func(manager.Manager) error
// AddToManager adds all Controllers to the Manager
func AddToManager(m manager.Manager) error {
for _, f := range AddToManagerFuncs {
if err := f(m); err != nil {
return err
}
}
return nil
}
同级目录下不同的controller的init函数有注册AddToManagerFuncs的实现
//add_mysqlcontroller.go
func init() {
// AddToManagerFuncs is a list of functions to create controllers and add them to a manager.
AddToManagerFuncs = append(AddToManagerFuncs, mysqlcluster.Add)
}
//add_nodecontroller.go
func init() {
// AddToManagerFuncs is a list of functions to create controllers and add them to a manager.
AddToManagerFuncs = append(AddToManagerFuncs, node.Add)
}
Note: 看到有大量项目使用下划线声明变量,mysql-operator项目中也存在
var _ reconcile.Reconciler = &ReconcileMysqlCluster{},这是一种接口断言,否则编译报错
二级缓存常见实现
引用左耳朵耗子的:缓存更新的套路
Cache Aside模式
- 失效:应用程序先从cache取数据,没有得到,则从数据库中取数据,成功后,放到缓存中。
- 命中:应用程序从cache中取数据,取到后返回。
- 更新:先把数据存到数据库中,成功后,再让缓存失效。
Read Through模式
查询操作中更新缓存
Write Through模式
更新数据时发生。当有数据更新的时候,如果没有命中缓存,直接更新数据库,然后返回。 如果命中了缓存,则更新缓存,然后再由Cache自己更新数据库
Write Back模式
在更新数据的时候,只更新缓存,不更新数据库,缓存会异步地批量更新数据库
for range的坑
func main() {
arr1 := []int{1, 2, 3}
arr2 := make([]*int, len(arr1))
for i, v := range arr1 {
arr2[i] = &v
}
for _, v := range arr2 {
fmt.Println(*v)
}
}
输出结果
3
3
3
原因是v变量在for range中只会被初始化一次,后面都是复用这个临时变量,v的指针地址始终是同一个地址;建议可以用slice下标避免这个问题
参考链接
- golang中的defer必掌握的7知识点golang中的defer必掌握的7知识点
- Go 语言标准库中 atomic.Value 的前世今生
- 浅谈协程和Go语言的Goroutine
- https://liudanking.com/performance/golang-%E8%8E%B7%E5%8F%96-goroutine-id-%E5%AE%8C%E5%85%A8%E6%8C%87%E5%8D%97/
- https://chai2010.cn/advanced-go-programming-book/ch3-asm/ch3-08-goroutine-id.html
- GO编程模式: 泛型编程
- Go Tips 101
- Size and alignment guarantees - golang spec 的unsafe.Alignof
- Go 语言高性能编程
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师真诚赞赏,手留余香
使用微信扫描二维码完成支付
