算法复杂度
时间复杂度
大O复杂度表示法: 表示代码执行时间随数据规模增长的变化趋势
T(n) = O(f(n))
时间复杂度分析
- 只关注循环次数最多的那段代码
- 加法法则,总复杂度等于量级最大的那段代码的复杂度
- 乘法法则,嵌套代码的复杂度等于嵌套内外代码复杂度的乘积
常见时间复杂度量级(按数量级递增):
-
多项式量级
- 常量阶 O(1)
- 对数阶 O(logN)
- 线性阶 O(n)
- 线性对数阶 O(nlogN)
- 平方阶 O(n^2) O(n^3) O(n^k)
-
非多项式量级
- 指数阶 O(2^n)
- 阶乘阶 O(n!)
空间复杂度
表示算法 的存储空间与数据规模之间的增⻓关系
空间复杂度分析 常⻅的空间复杂度有:
- O(1)
- O(n)
- O(n2 )
像O(logn)、O(nlogn)对数阶复杂度一般都用不到;空间复杂度分析比时间复杂度分析简单
进阶复杂度分析
- 最好情况时间复杂度
- 最坏情况时间复杂度
- 平均情况时间复杂度
- 均摊时间复杂度
常见数据结构
数组
package main
import (
"errors"
"fmt"
)
/**
* 1) 数组的插入、删除、按照下标随机访问操作;
* 2)数组中的数据是int类型的;
*
*/
type Array struct {
data []int
length uint
}
func NewArray(capacity uint) *Array {
if capacity == 0 {
return nil
}
return &Array{
data: make([]int, capacity, capacity),
length: 0,
}
}
func (a *Array) Len() uint {
return a.length
}
// 越界
func (a *Array) OutOfCap(index uint) error {
if index >= uint(cap(a.data)) {
return errors.New("out of cap")
}
return nil
}
// 插入
func (a *Array) Insert(index uint, v int) error {
if a.Len() == uint(cap(a.data)) {
return errors.New("full cap")
}
// 是否越界
if err := a.OutOfCap(index); err != nil {
return err
}
for i:=a.Len(); i>index; i-- {
a.data[i] = a.data[i-1]
}
a.data[index] = v
a.length++
return nil
}
// 删除
func (a *Array) Delete(index uint) error {
// 是否越界
if err := a.OutOfCap(index); err != nil {
return err
}
for i:=index; i<a.Len()-1; i++{
a.data[i] = a.data[i+1]
}
a.data[a.Len()-1] = 0
a.length--
return nil
}
// 按照下标随机访问
func (a *Array) Find(index uint) (*int, error) {
if err := a.OutOfCap(index); err != nil {
return nil, err
}
findInt := a.data[index]
return &findInt, nil
}
// 遍历
func (a *Array) Print() {
for i := uint(0); i < uint(cap(a.data)); i++ {
fmt.Println(a.data[i])
}
}
func main() {
testArray := NewArray(10)
testArray.Insert(0, 0)
testArray.Insert(1, 1)
testArray.Insert(2, 2)
testArray.Insert(3, 3)
testArray.Delete(2)
testArray.Print()
}
数组用一块连续的内存空间,来存储相同类型的一组数据,最大的特点就是支持随机访问,但插入、删除操作也因此变得比较低效,平均情况时间复杂度为O(n)
单向链表
链表插入/删除平均情况时间复杂度为O(1),随机访问平均时间复杂度为O(n)
package main
import (
"fmt"
)
/*
* 单向链表基本操作
*/
type LinkedNode struct {
value int
next *LinkedNode
}
type LinkedList struct {
head *LinkedNode
length uint
}
func (l *LinkedList) Len() uint {
return l.length
}
// 之后插入
func (l *LinkedList) InsertAfter(p *LinkedNode, v int) bool {
if p == nil {
return false
}
originNext := p.next
linkedNode := &LinkedNode{
value: v,
next: originNext,
}
p.next = linkedNode
l.length++
return true
}
// 之前插入
func (l *LinkedList) InsertBefore(p *LinkedNode, v int) bool {
if p == nil {
return false
}
current := l.head
for current.next != nil {
if current.next == p {
break
}
current = current.next
}
linkedNode := &LinkedNode{
value: v,
next: p,
}
current.next = linkedNode
l.length++
return true
}
// 删除
func (l *LinkedList) Delete(p *LinkedNode) bool {
current := l.head
if current == p {
l.head = current.next
l.length--
return true
}
for current.next != nil {
if current.next == p {
break
}
current = current.next
}
if current.next == nil {
return false
}
current.next = p.next
l.length--
return true
}
// 查找
func (l *LinkedList) Find(index int) *LinkedNode {
current := l.head
for i := 0; i < index-1; i++ {
if current.next != nil {
current = current.next
}
}
return current
}
// 遍历
func (l *LinkedList) Print() {
current := l.head
for {
fmt.Println(current.value)
if current.next == nil {
return
}
current = current.next
}
}
func main() {
n5 := &LinkedNode{value: 5, next: nil}
n4 := &LinkedNode{value: 4, next: n5}
n3 := &LinkedNode{value: 3, next: n4}
n2 := &LinkedNode{value: 2, next: n3}
n1 := &LinkedNode{value: 1, next: n2}
linkedList := &LinkedList{
head: n1,
length: 5,
}
linkedList.InsertBefore(n2, 222)
linkedList.InsertAfter(n5, 222)
tar := linkedList.Find(6)
linkedList.Delete(tar)
linkedList.Print()
}
双向链表
双向链表,之前插入和删除,不需要再遍历了
package main
import (
"fmt"
)
/*
* 双向链表基本操作
*/
type LinkedNode struct {
value int
pre *LinkedNode
next *LinkedNode
}
type LinkedList struct {
head *LinkedNode
length uint
}
func (l *LinkedList) Len() uint {
return l.length
}
// 之后插入
func (l *LinkedList) InsertAfter(p *LinkedNode, v int) bool {
if p == nil {
return false
}
lastNode := p.next
linkedNode := &LinkedNode{
pre: p,
value: v,
next: lastNode,
}
p.next = linkedNode
lastNode.pre = linkedNode
l.length++
return true
}
// 之前插入
func (l *LinkedList) InsertBefore(p *LinkedNode, v int) bool {
if p == nil {
return false
}
preNode := p.pre
linkedNode := &LinkedNode{
value: v,
pre: preNode,
next: p,
}
preNode.next = linkedNode
p.pre = linkedNode
l.length++
return true
}
// 删除
func (l *LinkedList) Delete(p *LinkedNode) bool {
// 首节点
if l.head == p {
l.head = p.next
if p.next != nil {
p.next.pre = nil
}
l.length--
return true
}
// 尾节点
if p.next == nil {
preNode := p.pre
preNode.next = nil
l.length--
return true
}
preNode := p.pre
lastNode := p.next
preNode.next = lastNode
lastNode.pre = preNode
l.length--
return true
}
// 查找
func (l *LinkedList) Find(index int) *LinkedNode {
current := l.head
for i := 0; i < index-1; i++ {
if current.next != nil {
current = current.next
}
}
return current
}
// 遍历
func (l *LinkedList) Print() {
current := l.head
for {
fmt.Println(current.value)
if current.next == nil {
return
}
current = current.next
}
}
func main() {
n5 := &LinkedNode{value: 5, next: nil}
n4 := &LinkedNode{value: 4, next: n5}
n3 := &LinkedNode{value: 3, next: n4}
n2 := &LinkedNode{value: 2, next: n3}
n1 := &LinkedNode{value: 1, next: n2}
n1.pre = nil
n2.pre = n1
n3.pre = n2
n4.pre = n3
n5.pre = n4
linkedList := &LinkedList{
head: n1,
length: 5,
}
linkedList.InsertBefore(n2, 222)
linkedList.InsertAfter(n3, 222)
tar := linkedList.Find(7)
linkedList.Delete(tar)
linkedList.Print()
}
双向循环链表
package main
import (
"fmt"
)
/*
* 双向循环链表基本操作(约瑟夫问题)
*/
type LinkedNode struct {
value int
pre *LinkedNode
next *LinkedNode
}
type LinkedList struct {
head *LinkedNode
length uint
}
func (l *LinkedList) Len() uint {
return l.length
}
// 之后插入
func (l *LinkedList) InsertAfter(p *LinkedNode, v int) bool {
if p == nil {
return false
}
lastNode := p.next
linkedNode := &LinkedNode{
pre: p,
value: v,
next: lastNode,
}
p.next = linkedNode
lastNode.pre = linkedNode
l.length++
return true
}
// 之前插入
func (l *LinkedList) InsertBefore(p *LinkedNode, v int) bool {
if p == nil {
return false
}
preNode := p.pre
linkedNode := &LinkedNode{
value: v,
pre: preNode,
next: p,
}
preNode.next = linkedNode
p.pre = linkedNode
l.length++
return true
}
// 删除
func (l *LinkedList) Delete(p *LinkedNode) bool {
if p.pre == p || p.next == p {
l.head = nil
l.length--
return true
}
preNode := p.pre
lastNode := p.next
preNode.next = lastNode
lastNode.pre = preNode
if l.head == p {
l.head = p.next
}
p.next = nil
p.pre = nil
p.value = 0
l.length--
return true
}
// 查找
func (l *LinkedList) Find(index int) *LinkedNode {
current := l.head
for i := 0; i < index-1; i++ {
if current.next != nil {
current = current.next
}
}
return current
}
// 遍历
func (l *LinkedList) Print() {
current := l.head
for i:= 0; i<int(l.Len()); i++ {
fmt.Println(current.value)
if current.next == nil {
return
}
current = current.next
}
}
func main() {
n5 := &LinkedNode{value: 5}
n4 := &LinkedNode{value: 4}
n3 := &LinkedNode{value: 3}
n2 := &LinkedNode{value: 2}
n1 := &LinkedNode{value: 1}
n1.pre = n5
n2.pre = n1
n3.pre = n2
n4.pre = n3
n5.pre = n4
n1.next = n2
n2.next = n3
n3.next = n4
n4.next = n5
n5.next = n1
linkedList := &LinkedList{
head: n1,
length: 5,
}
linkedList.InsertBefore(n2, 222)
linkedList.InsertAfter(n3, 222)
tar := linkedList.Find(1)
linkedList.Delete(tar)
linkedList.Print()
}
进阶链表
- 单链表反转
- 链表中环的检测
- 两个有序的链表合并
- 删除链表倒数第n个结点
- 求链表的中间结点
// 反转
/*
* 使用p和q两个指针配合工作,使得两个节点间的指向反向,同时用r记录剩下的链表
*/
func (l *LinkedList) Reverse() {
if nil == l.head || nil == l.head.next {
return
}
p := l.head
q := p.next
p.next = nil
for {
r := q.next
q.next = p
p = q
q = r
if r == nil {
break
}
}
l.head = p
}
顺序栈
package main
import (
"fmt"
)
/*
* 基于数组的顺序栈
*/
type Stack struct {
length int
size int
items []string
}
func (s *Stack) Len() int {
return s.length
}
func NewStack(size int) *Stack {
return &Stack{
length: 0,
size: size,
items: make([]string, size),
}
}
// 入栈
func (s *Stack) Push(item string) bool {
if s.length == s.size {
return false
}
s.items[s.length] = item
s.length++
return true
}
// 出栈
func (s *Stack) Pop() string {
if s.length == 0 {
return ""
}
item := s.items[s.length-1]
s.items = s.items[:s.length-1]
s.length--
return item
}
// 遍历
func (s *Stack) Print() {
for i:=0; i<s.length; i++ {
fmt.Println(s.items[i])
}
}
func main() {
s := NewStack(10)
s.Push("1")
s.Push("2")
s.Push("3")
fmt.Println("origin:")
s.Print()
s.Pop()
s.Pop()
fmt.Println("now:")
s.Print()
}
链式栈
package main
import (
"fmt"
)
/*
* 基于链表的非顺序栈
*/
type LinkedNode struct {
value int
next *LinkedNode
}
type Stack struct {
head *LinkedNode
length int
size int
}
func NewStack(head *LinkedNode, size int) *Stack {
return &Stack{
head: head,
length: 0,
size: size,
}
}
func (s *Stack) Len() int {
return s.length
}
// 入栈
func (s *Stack) Push(v int) bool {
if s.length == s.size {
return false
}
linkedNode := &LinkedNode{
value: v,
next: nil,
}
if s.head == nil {
s.head = linkedNode
return true
}
tail := s.head
for tail.next != nil {
tail = tail.next
}
tail.next = linkedNode
s.length++
return true
}
// 出栈
func (s *Stack) Pop() *int {
beforeTail := new(LinkedNode)
tail := s.head
if tail == nil {
return nil
}
beforeTail = tail
for tail.next != nil {
beforeTail = tail
tail = tail.next
}
beforeTail.next = nil
s.length--
return &tail.value
}
// 遍历
func (s *Stack) Print() {
current := s.head
for {
fmt.Println(current.value)
if current.next == nil {
return
}
current = current.next
}
}
func main() {
n5 := &LinkedNode{value: 5, next: nil}
n4 := &LinkedNode{value: 4, next: n5}
n3 := &LinkedNode{value: 3, next: n4}
n2 := &LinkedNode{value: 2, next: n3}
n1 := &LinkedNode{value: 1, next: n2}
s := NewStack(n1, 5)
s.Push(6)
s.Push(10)
s.Push(11)
s.Pop()
s.Print()
}
顺序队列
package main
import (
"fmt"
)
/*
* 基于数组的顺序队列
*/
type Queue struct {
length int
size int
items []string
}
func (s *Queue) Len() int {
return s.length
}
func NewQueue(size int) *Queue {
return &Queue{
length: 0,
size: size,
items: make([]string, size),
}
}
// 入队列
func (s *Queue) Push(item string) bool {
if s.length == s.size {
return false
}
s.items[s.length] = item
s.length++
return true
}
// 出队列
func (s *Queue) Pop() string {
if s.length == 0 {
return ""
}
item := s.items[0]
s.items = s.items[1:]
s.length--
return item
}
// 遍历
func (s *Queue) Print() {
for i:=0; i<s.length; i++ {
fmt.Println(s.items[i])
}
}
func main() {
s := NewQueue(10)
fmt.Println("origin:")
s.Push("1")
s.Push("2")
s.Push("3")
s.Print()
s.Pop()
fmt.Println("now:")
s.Print()
}
链式队列
package main
import (
"fmt"
)
/*
* 基于链表的非顺序队列
*/
type LinkedNode struct {
value int
next *LinkedNode
}
type Queue struct {
head *LinkedNode
length int
size int
}
func NewQueue(head *LinkedNode, size int) *Queue {
return &Queue{
head: head,
length: 0,
size: size,
}
}
func (q *Queue) Len() int {
return q.length
}
// 入队列
func (q *Queue) Push(v int) bool {
if q.length == q.size {
return false
}
linkedNode := &LinkedNode{
value: v,
next: nil,
}
if q.head == nil {
q.head = linkedNode
return true
}
tail := q.head
for tail.next != nil {
tail = tail.next
}
tail.next = linkedNode
q.length++
return true
}
// 出队列
func (q *Queue) Pop() *int {
if q.head == nil {
return nil
}
popValue := q.head.value
q.head = q.head.next
q.length--
return &popValue
}
// 遍历
func (q *Queue) Print() {
current := q.head
for {
fmt.Println(current.value)
if current.next == nil {
return
}
current = current.next
}
}
func main() {
n5 := &LinkedNode{value: 5, next: nil}
n4 := &LinkedNode{value: 4, next: n5}
n3 := &LinkedNode{value: 3, next: n4}
n2 := &LinkedNode{value: 2, next: n3}
n1 := &LinkedNode{value: 1, next: n2}
q := NewQueue(n1, 5)
q.Push(6)
q.Push(10)
q.Push(11)
q.Pop()
q.Print()
}
循环队列
基于数组实现的队列,在出队列的时候会有数据搬迁;循环队列可以不用数据搬迁
package main
import (
"fmt"
)
/*
* 基于数组的循环队列,分别用head、tail记录队列头部、尾部位置
*/
type Queue struct {
size int
head int
tail int
items []interface{}
}
func NewQueue(size int) *Queue {
return &Queue{
size: size,
head: 0,
tail: 0,
items: make([]interface{}, size),
}
}
// 是否满队列
func (s *Queue) IsFull() bool {
if s.head == (s.tail+1) % s.size {
return true
}
return false
}
// 是否空队列
func (s *Queue) IsEmpty() bool {
if s.head == s.tail {
return true
}
return false
}
// 入队列
func (s *Queue) Push(item interface{}) bool {
if s.IsFull() {
return false
}
s.items[s.tail] = item
s.tail = (s.tail+1) % s.size
return true
}
// 出队列
func (s *Queue) Pop() interface{} {
if s.IsEmpty() {
return false
}
item := s.items[s.head]
s.head = (s.head+1) % s.size
return item
}
// 遍历
func (s *Queue) String() string {
if s.IsEmpty() {
return "empty queue"
}
result := "head"
var i = s.head
for true {
result += fmt.Sprintf("<-%+v", s.items[i])
i = (i + 1) % s.size
if i == s.tail {
break
}
}
result += "<-tail"
return result
}
func main() {
s := NewQueue(10)
fmt.Println("origin:")
s.Push("1")
s.Push("2")
s.Push("3")
fmt.Println(s)
s.Pop()
fmt.Println("now:")
fmt.Println(s)
}
算法
bitmap(位图)
/*
BitMap解决海量数据寻找重复、判断个别元素是否在海量数据当中
(来自《编程珠玑》):给一台普通PC,2G内存,要求处理一个包含40亿个不重复并且没有排过序的无符号的int整数,
给出一个整数,问如果快速地判断这个整数是否在文件40亿个数据当中?
问题思考:
40亿个int占(40亿*4)/1024/1024/1024 大概为14.9G左右,很明显内存只有2G,放不下,
因此不可能将这40亿数据放到内存中计算。
要快速的解决这个问题最好的方案就是将数据搁内存了,所以现在的问题就在如何在2G内存空间以内存储着40亿整数。
一个int整数在golang中是占4个字节的即要32bit位,如果能够用一个bit位来标识一个int整数那么存储空间将大大减少,
算一下40亿个int需要的内存空间为40亿/8/1024/1024大概为476.83 mb,这样的话我们完全可以将这40亿个int数放到内存中进行处理。
具体思路:
1个int占4字节即4*8=32位,那么我们只需要申请一个int数组长度为 int tmp[1+N/32]即可存储完这些数据,
其中N代表要进行查找的总数,tmp中的每个元素在内存在占32位可以对应表示十进制数0~31,所以可得到BitMap表:
tmp[0]:可表示0~31
tmp[1]:可表示32~63
tmp[2]可表示64~95
*/
package bitmap
import (
"bytes"
"fmt"
)
type Bitmap struct {
words []uint64
length uint64
}
func New() *Bitmap {
return &Bitmap{}
}
func (bitmap *Bitmap) Has(num int) bool {
word, bit := num/64, uint(num%64)
return word < len(bitmap.words) && (bitmap.words[word]&(1<<bit)) != 0
}
func (bitmap *Bitmap) Add(num int) {
word, bit := num/64, uint(num%64)
for word >= len(bitmap.words) {
bitmap.words = append(bitmap.words, 0)
}
// 判断num是否已经存在bitmap中
if bitmap.words[word]&(1<<bit) == 0 {
bitmap.words[word] |= 1 << bit
bitmap.length++
}
}
func (bitmap *Bitmap) Len() int {
return bitmap.length
}
func (bitmap *Bitmap) String() string {
var buf bytes.Buffer
buf.WriteByte('{')
for i, v := range bitmap.words {
if v == 0 {
continue
}
for j := uint(0); j < 64; j++ {
if v&(1<<j) != 0 {
if buf.Len() > len("{") {
buf.WriteByte(' ')
}
fmt.Fprintf(&buf, "%d", 64*uint(i)+j)
}
}
}
buf.WriteByte('}')
fmt.Fprintf(&buf,"\nLength: %d", bitmap.length)
return buf.String()
}
排序算法一览:
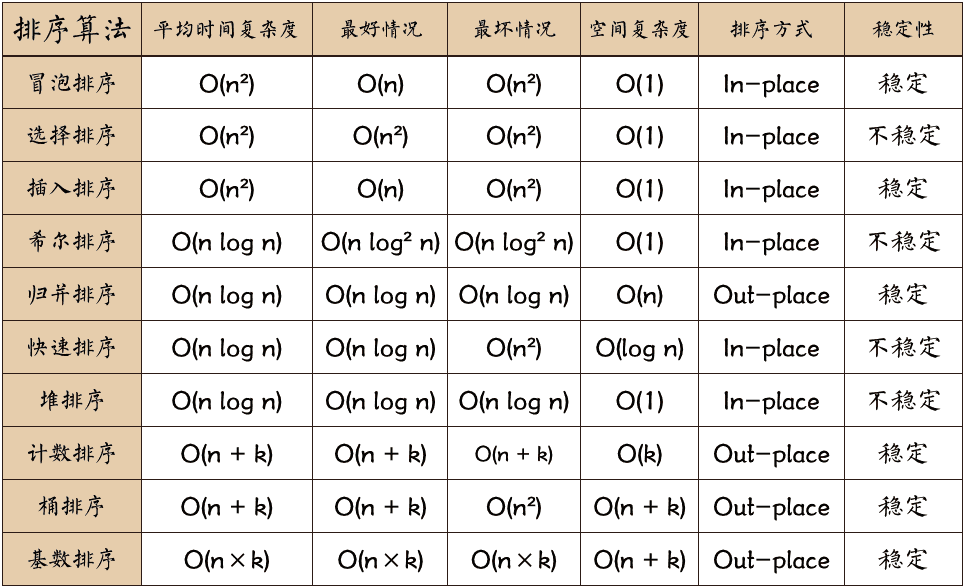
冒泡排序
冒泡排序(Bubble Sort)也是一种简单直观的排序算法。它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来。
算法步骤:
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
func bubbleSort(arr []int) []int {
length := len(arr)
for i := 0; i < length; i++ {
for j := 0; j < length-1-i; j++ {
if arr[j] > arr[j+1] {
arr[j], arr[j+1] = arr[j+1], arr[j]
}
}
}
return arr
}
选择排序
选择排序是一种简单直观的排序算法,无论什么数据进去都是O(n²)的时间复杂度。
算法步骤:
- 首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置
- 再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
- 重复第二步,直到所有元素均排序完毕。
func selectorSort(arr []int) []int {
length := len(arr)
for i := 0; i < length; i++ {
max := i
for j := i+1; j < length; j++ {
if arr[j] > arr[max] {
max = j
}
}
if max != i {
arr[max], arr[i] = arr[i], arr[max]
}
}
return arr
}
插入排序
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了, 插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。
算法步骤:
- 将第一待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
- 从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
func insertSort(arr []int) []int {
for i := range arr {
preIndex := i - 1
current := arr[i]
for preIndex >= 0 && arr[preIndex] > current {
arr[preIndex+1] = arr[preIndex]
preIndex -= 1
}
arr[preIndex+1] = current
}
return arr
}
归并排序
归并排序(Merge sort)是建立在归并操作上的一种有效的排序算法。该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。
归并排序的实现由两种方法:
- 自上而下的递归(所有递归的方法都可以用迭代重写,所以就有了第2种方法)
- 自下而上的迭代
和选择排序一样,归并排序的性能不受输入数据的影响,但表现比选择排序好的多,因为始终都是O(nlogn)的时间复杂度。代价是需要额外的内存空间。
算法步骤:
- 申请空间,使其大小为两个已经排序序列之和,该空间用来存放合并后的序列;
- 设定两个指针,最初位置分别为两个已经排序序列的起始位置;
- 比较两个指针所指向的元素,选择相对小的元素放入到合并空间,并移动指针到下一位置;
- 重复步骤3直到某一指针达到序列尾;
- 将另一序列剩下的所有元素直接复制到合并序列尾。
自下而上的迭代
func mergeSort(arr []int) []int {
length := len(arr)
if length < 2 {
return arr
}
middle := length / 2
left := arr[0:middle]
right := arr[middle:]
return merge(mergeSort(left), mergeSort(right))
}
func merge(left []int, right []int) []int {
var result []int
for len(left) != 0 && len(right) != 0 {
if left[0] < right[0] {
result = append(result, left[0])
left = left[1:]
} else {
result = append(result, right[0])
right = right[1:]
}
}
for len(left) != 0 {
result = append(result, left[0])
left = left[1:]
}
for len(right) != 0 {
result = append(result, right[0])
right = right[1:]
}
return result
}
二叉树最大深度
方法一:深度优先搜索(DFS)
堆栈实现, 利用递归的方式不停下探树的深度; 递归的终止条件是如果节点为空就返回0
package main
type TreeNode struct {
left *TreeNode // 左子节点
right *TreeNode // 右子节点
value int // 值
}
func maxDepth(root *TreeNode) int {
// 递归终止条件
if root == nil {
return 0
}
return max(maxDepth(root.left), maxDepth(root.right)) + 1
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
方法二:广度优先搜索(BFS)
队列实现, 利用迭代的方式将每一层的节点都放入到队列当中; 队列出队清空进入下一层。
package main
type TreeNode struct {
left *TreeNode // 左子节点
right *TreeNode // 右子节点
value int // 值
}
func maxDepth(root *TreeNode) int {
// 没有根节点
if root == nil {
return 0
}
// 创建队列
queue := make([]*TreeNode, 0)
// 根节点入队列
queue = append(queue, root)
depth := 0
// 清算队列
for len(queue) > 0 {
// 把当前层的队列全部遍历一遍全部出队列
size := len(queue)
for i:=0; i<size; i++ {
// 出队列
v := queue[0]
if v.left != nil {
queue = append(queue, v.left)
}
if v.right != nil {
queue = append(queue, v.right)
}
}
depth++
}
return depth
}
DFS一般是解决连通性问题, 而BFS一般是解决最短路径问题.
LRU缓存
LRU: 最近一段时间最久未被使用的缓存优先删除
采用哈希表+双向链表实现;哈希表存放key对应的链节点(缓存数据),双向链表的顺序代表数据访问的新旧程度, 头部位置代表最近被访问的数据,尾部位置代表最近许久未被访问的数据,如果缓存数据超过链表容量,删除尾部位置节点
package main
import "fmt"
/*
采用哈希表+双向链表
*/
type LRUCache struct {
size, cap int
head, tail *LinkNode
cache map[int]*LinkNode
}
type LinkNode struct {
key, value int
pre, next *LinkNode
}
func (l *LRUCache) Get(key int) int {
linkNode, ok := l.cache[key]
//不存在,返回-1
if !ok {
return -1
}
//存在,移动节点到链表头
l.moveToHead(linkNode)
return linkNode.value
}
func (l *LRUCache) Put(key, value int) {
linkNode, ok := l.cache[key]
if !ok {
//是新节点
newLinkNode := initLinkNode(key, value)
l.addToHead(newLinkNode)
l.cache[key] = newLinkNode
l.size++
if l.size > l.cap {
//超过链表容量,剔除链表尾部节点
removedNode := l.tail.pre
l.removeNode(removedNode)
//从map删除
delete(l.cache, removedNode.key)
l.size--
}
} else {
//节点已存在
if linkNode.value != value {
linkNode.value = value
}
l.moveToHead(linkNode)
}
}
func (l *LRUCache) removeNode(linkNode *LinkNode) {
linkNode.pre.next = linkNode.next
linkNode.next.pre = linkNode.pre
}
func (l *LRUCache) removeTail(linkNode *LinkNode) {
l.removeNode(linkNode)
l.tail.next = nil
}
func (l *LRUCache) addToHead(linkNode *LinkNode) {
linkNode.pre = l.head
linkNode.next = l.head.next
l.head.next.pre = linkNode
l.head.next = linkNode
}
func (l *LRUCache) moveToHead(linkNode *LinkNode) {
//1. 删除节点原来的位置
l.removeNode(linkNode)
//2. 插入到链表头部
l.addToHead(linkNode)
}
func initLinkNode(key, value int) *LinkNode {
return &LinkNode{
key: key,
value: value,
}
}
func conStructLRUCache(cap int) *LRUCache {
l := &LRUCache{
size: 0,
cap: cap,
head: initLinkNode(0, 0),
tail: initLinkNode(0,0),
cache: make(map[int]*LinkNode, 0),
}
l.head.next = l.tail
l.head.pre = nil
l.tail.pre = l.head
l.tail.next = nil
return l
}
func (l *LRUCache) print() {
for key, value := range l.cache {
fmt.Printf(" key: %d, value: %d", key, value.value)
}
}
func main() {
l := conStructLRUCache(2)
fmt.Println("\n第一次put")
l.Put(1,1)
l.print()
fmt.Println("\n第二次put")
l.Put(2,2)
l.print()
l.Get(1)
fmt.Println("\n第三次put")
l.Put(3,3)
l.print()
fmt.Println("\n第四次put")
l.Put(4,4)
l.print()
fmt.Println("\n第五次put")
l.Put(4,8)
l.print()
fmt.Println("\n第六次put")
l.Put(6,6)
l.print()
}
参考链接
- 数据结构与算法之美(极客时间王争)
- 十大经典排序算法
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
