背景
记录LLM学习的过程,面向开发者的提示工程和使用LangChain开发应用程序的内容来源于Github开源项目llm-cookbook,其它章节来源于官网、开源项目等实践记录。
环境配置
1.申请OpenAI API Key
在OpenAI官网注册的账号默认有18美金的额度用于消耗token,3个月内有效。国内也有免费的内测Key供申请
https://github.com/chatanywhere/GPT_API_free,需要绑定Github账号来申请。
2.Golang tool库封装
封装一个CreateChatCompletion函数,放在同个package下引用
package main
import (
"context"
// 官方推荐的第三方OpenAl golang sdk
"github.com/sashabaranov/go-openai"
)
const (
Token = "<填入你的token>"
// 使用国内免费申请的Key的话,就用这个host用于转发请求
OpenAIProxyURL = "https://api.chatanywhere.com.cn/v1"
)
type openAIClient struct {
*openai.Client
}
func newOpenAIClient() *openAIClient {
config := openai.DefaultConfig(Token)
config.BaseURL = OpenAIProxyURL
c := openai.NewClientWithConfig(config)
return &openAIClient{c}
}
func (c *openAIClient) CreateChatCompletion(ctx context.Context, content string) (openai.ChatCompletionResponse, error) {
return c.Client.CreateChatCompletion(ctx, openai.ChatCompletionRequest{
Model: openai.GPT3Dot5Turbo,
Messages: []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleUser,
Content: content,
},
},
Temperature: 0,
})
}
面向开发者的提示工程
随着ChatGPT为代表的大语言大模型大爆发出现之后,Prompt已经成为与大模型输入的代称。一般将大模型的输入称为Prompt,将大模型的返回输出称为Completion。
合理的Prompt设计决定了大模型能力的上限和下限,学会充分、高效使用LLM,Prompt Engineering的技能强烈需要。Prompt Engineering是针对特定任务构造充分
发挥大模型能力的Prompt的技巧。
简介Introduction
随着LLM的发展,大致分为两种类型:
- 基础LLM:基于文本训练数据,训练出预测下一个单词能力的模型。通常通过在互联网和其他来源的大量数据上训练,来确定紧接着出现的最可能的词。
- 指令微调LLM:通过专门的训练,可以更好地理解并遵循指令。指令微调LLM的训练通常基于预训练语言模型,先在大规模文本数据上进行预训练,掌握语言的基本规律。 在此基础上进行进一步的训练与微调(finetune),输入是指令,输出是对这些指令的正确回复。还可以通过RLHF(人类反馈强化学习)技术,增强模型的能力。
这里的实践重点介绍针对指令微调LLM的最佳实践。
提示原则Guidelines
高效Prompt的两个关键原则:
- 编写清晰、具体的指令;清晰明确地表达需求,提供足够的上下文,让大语言模型准确理解需求。
- 给予模型充足思考时间;加入逐步推理的要求,给模型留充分思考时间,生成的结果更准确可靠。
掌握这两个关键原则,是大语言模型成功的重要基石。
编写清晰具体的指令
使用分隔符
分隔符可以将不同的指令、上下文、输入隔开,防止提示词注入,输入的文本可能包含与预设的Prompt冲突的内容,如果不加分隔,这些输入可能扰乱模型的输出。
示例:给出一段话,让GPT进行总结,使用"“作为分隔符
func main() {
text := `
您应该提供尽可能清晰、具体的指示,以表达您希望模型执行的任务。\
这将引导模型朝向所需的输出,并降低收到无关或不正确响应的可能性。\
不要将写清晰的提示词与写简短的提示词混淆。\
在许多情况下,更长的提示词可以为模型提供更多的清晰度和上下文信息,从而导致更详细和相关的输出。
`
prompt := `
把用两个双引号括起来的文本总结成一句话。
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
提供清晰、具体的指示可以引导模型朝向所需的输出,避免无关或不正确的响应。长度更长的提示词可以提供更多的清晰度和上下文信息,导致更详细和相关的输出。
结构化输出
结构化输出,指的是类似json、html等结构。
示例:让GPT生成三本书的标题、作者和类别,并以JSON格式返回,其中JSON的key已指定
func main() {
prompt := `
请生成包括书名、作者和类别的三本虚构的、非真实存在的中文书籍清单,\
并以JSON格式提供,其中包含以下键:book_id、title、author、genre。
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
[
{
"book_id": 1,
"title": "夜色旅人",
"author": "张三",
"genre": "奇幻"
},
{
"book_id": 2,
"title": "梦境之城",
"author": "李四",
"genre": "科幻"
},
{
"book_id": 3,
"title": "幻想之门",
"author": "王五",
"genre": "魔幻"
}
]
模型检查
如果任务包含不一定能满足的条件,可以让模型检查这些条件,如果不满足,可以让其停止执行后续的流程。可以加入一些边界情况的考虑,以避免意外的结果或错误发生。
示例:分别给模型两段文本,一是制作茶的步骤,二是一段没有明确步骤的文本。要求模型判断是否其包含一系列指令,包含则按照给定格式重新编写指令,不包含则返回"未提供步骤”
// 制作茶的步骤
func main() {
text1 := `
泡一杯茶很容易。首先,需要把水烧开。\
在等待期间,拿一个杯子并把茶包放进去。\
一旦水足够热,就把它倒在茶包上。\
等待一会儿,让茶叶浸泡。几分钟后,取出茶包。\
如果您愿意,可以加一些糖或牛奶调味。\
就这样,您可以享受一杯美味的茶了。
`
prompt := `
您将获得由两个双引号括起来的文本。\
如果它包含一系列的指令,则需要按照以下格式重新编写这些指令:
第一步 - ...
第二步 - …
…
第N步 - …
如果文本中不包含一系列的指令,则直接写“未提供步骤”。
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text1))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
第一步 - 把水烧开。
第二步 - 拿一个杯子并把茶包放进去。
第三步 - 把热水倒在茶包上。
第四步 - 等待几分钟让茶叶浸泡,然后取出茶包。
第五步 - 可以选择加入糖或牛奶调味。
第六步 - 就这样,您可以享受一杯美味的茶了。
// 一段没有明确步骤的文本
func main() {
text2 := `
泡一杯茶很容易。首先,需要把水烧开。\
在等待期间,拿一个杯子并把茶包放进去。\
一旦水足够热,就把它倒在茶包上。\
等待一会儿,让茶叶浸泡。几分钟后,取出茶包。\
如果您愿意,可以加一些糖或牛奶调味。\
就这样,您可以享受一杯美味的茶了。
`
prompt := `
您将获得由两个双引号括起来的文本。\
如果它包含一系列的指令,则需要按照以下格式重新编写这些指令:
第一步 - ...
第二步 - …
…
第N步 - …
如果文本中不包含一系列的指令,则直接写“未提供步骤”。
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text2))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
未提供步骤
提供少量示例
Few-shot prompting,在模型执行具体任务之前,给模型1~2个样例,让模型了解要求和期望输出的样式
示例:利用少量样例,可以预热语言模型,这是一个让模型快速上手新任务的有效策略。
func main() {
prompt := `
您的任务是以一致的风格回答问题。
<孩子>: 请教我何为耐心。
<祖父母>: 挖出最深峡谷的河流源于一处不起眼的泉眼;最宏伟的交响乐从单一的音符开始;最复杂的挂毯以一根孤独的线开始编织。
<孩子>: 请教我何为韧性。
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
<祖父母>: 韧性就像一根弹簧,能够在压力和挑战面前保持弹性和坚韧。它是一种适应和持久的能力,能够在困的本质。
给模型时间思考
给模型充足的时间思考,可以提高模型的准确性,好比让一个人在短时间内去解决一个非常棘手的问题,难度可见之大。
指定完成任务的步骤
示例:描述了杰克和吉尔的故事,并给出提示词执行以下操作:首先,用一句话概括三个反引号限定的文本。第二,将摘要翻译成英语。第三,在英语摘要中列出每个名称。 第四,输出包含以下键的JSON对象:英语摘要和人名个数。要求输出以换行符分隔
func main() {
text := `
在一个迷人的村庄里,兄妹杰克和吉尔出发去一个山顶井里打水。\
他们一边唱着欢乐的歌,一边往上爬,\
然而不幸降临——杰克绊了一块石头,从山上滚了下来,吉尔紧随其后。\
虽然略有些摔伤,但他们还是回到了温馨的家中。\
尽管出了这样的意外,他们的冒险精神依然没有减弱,继续充满愉悦地探索。
`
prompt := `
执行以下操作:
1-用一句话概括下面用两个双反引号括起来的文本。
2-将摘要翻译成英语。
3-在英语摘要中列出每个人名。
4-输出一个 JSON 对象,其中包含以下键:english_summary,num_names。
请用换行符分隔您的答案。
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
1- 兄妹在迷人的村庄冒险后受伤但仍然乐观。
2- Siblings Jack and Jill set off to fetch water from a well on a mountaintop in a charming village.
3- Jack, Jill
4- {
"english_summary": "Siblings Jack and Jill set off to fetch water from a well on a mountaintop in a charming village. Despite getting injured in an unfortunate accident, they still maintained their adventurous spirit and continued to explore joyfully.",
"num_names": 2
}
可以将prompt改进,确切指定输出格式
func main() {
text := `
在一个迷人的村庄里,兄妹杰克和吉尔出发去一个山顶井里打水。\
他们一边唱着欢乐的歌,一边往上爬,\
然而不幸降临——杰克绊了一块石头,从山上滚了下来,吉尔紧随其后。\
虽然略有些摔伤,但他们还是回到了温馨的家中。\
尽管出了这样的意外,他们的冒险精神依然没有减弱,继续充满愉悦地探索。
`
prompt := `
1-用一句话概括下面用双引号括起来的文本。
2-将摘要翻译成英语。
3-在英语摘要中列出每个名称。
4-输出一个 JSON 对象,其中包含以下键:English_summary,num_names。
请使用以下格式:
文本:<要总结的文本>
摘要:<摘要>
翻译:<摘要的翻译>
名称:<英语摘要中的名称列表>
输出 JSON:<带有 English_summary 和 num_names 的 JSON>
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
摘要:故事讲述了杰克和吉尔在山顶井打水时发生意外,但他们的冒险精神依然没有减弱。
翻译:Summary: The story tells about an accident that happened to Jack and Jill while they were geng water from a well on the mountaintop, but their adventurous spirit remained undiminished.
名称:Jack, Jill
输出 JSON:{"English_summary": "The story tells about an accident that happened to Jack and Jill we they were getting water from a well on the mountaintop, but their adventurous spirit remained undiminished.", "num_names": 2}
指导模型自主思考
设计prompt时,可以通过明确指导语言模型进行自主思考。在prompt中要求语言模型先自己尝试解决问题,思考对应的解决方法,再与提供的解答进行对比,校验正确性。
示例:给出一个问题和一份来自学生的解答,要求模型判断解答是否正确
func main() {
prompt := `
判断学生的解决方案是否正确。
问题:
我正在建造一个太阳能发电站,需要帮助计算财务。
土地费用为 100美元/平方英尺
我可以以 250美元/平方英尺的价格购买太阳能电池板
我已经谈判好了维护合同,每年需要支付固定的10万美元,并额外支付每平方英尺10美元
作为平方英尺数的函数,首年运营的总费用是多少。
学生的解决方案:
设x为发电站的大小,单位为平方英尺。
费用:
土地费用:100x
太阳能电池板费用:250x
维护费用:100,000美元+100x
总费用:100x+250x+100,000美元+100x=450x+100,000美元
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
学生的解决方案是正确的。总费用可以表示为450x+100,000美元。
实际上这个解决方案是错误的,总费用应该是360x+100,000美元,因为没让模型自行先计算,然后跟学生的解决方法对比,那么就有可能误导模型以为学生的解法就是正确的。 接下来调整思路,让模型先自行解决这个问题,再根据自己的解法跟学生的解法进行对比,然后再判断学生的解法是否正确。
func main() {
prompt := `
请判断学生的解决方案是否正确,请通过如下步骤解决这个问题:
步骤:
首先,自己解决问题。
然后将您的解决方案与学生的解决方案进行比较,对比计算得到的总费用与学生计算的总费用是否一致,并评估学生的解决方案是否正确。
在自己完成问题之前,请勿决定学生的解决方案是否正确。
使用以下格式:
问题:问题文本
学生的解决方案:学生的解决方案文本
实际解决方案和步骤:实际解决方案和步骤文本
学生计算的总费用:学生计算得到的总费用
实际计算的总费用:实际计算出的总费用
学生计算的费用和实际计算的费用是否相同:是或否
学生的解决方案和实际解决方案是否相同:是或否
学生的成绩:正确或不正确
问题:
我正在建造一个太阳能发电站,需要帮助计算财务。
- 土地费用为每平方英尺100美元
- 我可以以每平方英尺250美元的价格购买太阳能电池板
- 我已经谈判好了维护合同,每年需要支付固定的10万美元,并额外支付每平方英尺10美元;
作为平方英尺数的函数,首年运营的总费用是多少。
学生的解决方案:
设x为发电站的大小,单位为平方英尺。
费用:
1. 土地费用:100x美元
2. 太阳能电池板费用:250x美元
3. 维护费用:100,000+100x=10万美元+10x美元
总费用:100x美元+250x美元+10万美元+100x美元=450x+10万美元
实际解决方案和步骤:
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
首先,我们需要计算土地费用、太阳能电池板费用和维护费用的总和。
土地费用:100美元/平方英尺 * x平方英尺 = 100x美元
太阳能电池板费用:250美元/平方英尺 * x平方英尺 = 250x美元
维护费用:10万美元 + 10美元/平方英尺 * x平方英尺 = 10万美元 + 10x美元
总费用:100x美元 + 250x美元 + 10万美元 + 10x美元 = 360x + 10万美元
学生计算的总费用:450x + 10万美元
实际计算的总费用:360x + 10万美元
学生计算的费用和实际计算的费用是否相同:否
学生的解决方案和实际解决方案是否相同:否
学生的成绩:不正确
局限性
模型偶尔会生成一些看似真实,实际上不存在的知识。模型经过大量预训练,虽然掌握了丰富知识,但是难以判断自己的知识边界,可能会做出错误推断。这个现象称为幻觉(Hallucination), 是语言模型的一大陷阱。
func main() {
prompt := `
告诉我华为公司生产的GT Watch运动手表的相关信息
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
华为公司生产的GT Watch运动手表是一款运动智能手表,具有多项健康功能和运动追踪功能,如心率监测、睡眠 Watch还支持多种运动模式,包括跑步、骑行、游泳等,
可全面监测和分析用户的运动数据。此外,GT Watch还观,适合运动和日常佩戴。
可以通过Prompt设计减少幻觉的发生,比如让语言模型直接引用文本中的原句,然后再进行解答。语言模型的幻觉问题事关应用的可靠性与安全性。,采取prompt优化措施可以缓解,这也是未来语言模型 进化的重要方向之一。
英文原版Prompt
1.1 使用分隔符隔离不同输入部分
func main() {
text := `
You should express what you want a model to do by \
providing instructions that are as clear and \
specific as you can possibly make them. \
This will guide the model towards the desired output, \
and reduce the chances of receiving irrelevant \
or incorrect responses. Don't confuse writing a \
clear prompt with writing a short prompt. \
In many cases, longer prompts provide more clarity \
and context for the model, which can lead to \
more detailed and relevant outputs.
`
prompt := `
Summarize the text delimited by two double quotes \
into a single sentence.
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
Clear and specific instructions for a model will guide it towards the desired output, reducing the chances of irrelevant or incorrect responses,
and longer prompts can provide more clarity and context, leading to more detailed and relevant outputs.
1.2 结构化输出
func main() {
prompt := `
Generate a list of three made-up book titles along \
with their authors and genres.
Provide them in JSON format with the following keys:
book_id, title, author, genre.
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
{
"books": [
{
"book_id": 1,
"title": "The Forgotten Symphony",
"author": "Madeline Harper",
"genre": "Mystery"
},
{
"book_id": 2,
"title": "Echoes of Eternity",
"author": "Jackson Pierce",
"genre": "Science Fiction"
},
{
"book_id": 3,
"title": "The Enchanted Garden",
"author": "Sophie Evans",
"genre": "Fantasy"
}
]
}
1.3 模型检查是否满足条件
func main() {
text1 := `
Making a cup of tea is easy! First, you need to get some \
water boiling. While that's happening, \
grab a cup and put a tea bag in it. Once the water is \
hot enough, just pour it over the tea bag. \
Let it sit for a bit so the tea can steep. After a \
few minutes, take out the tea bag. If you \
like, you can add some sugar or milk to taste. \
And that's it! You've got yourself a delicious \
cup of tea to enjoy.
`
prompt := `
You will be provided with text delimited by two double quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text1))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
Step 1 - Get some water boiling.
Step 2 - Grab a cup and put a tea bag in it.
Step 3 - Pour hot water over the tea bag.
Step 4 - Let the tea steep for a few minutes.
Step 5 - Remove the tea bag.
Step 6 - Add sugar or milk to taste.
func main() {
text2 := `
The sun is shining brightly today, and the birds are \
singing. It's a beautiful day to go for a \
walk in the park. The flowers are blooming, and the \
trees are swaying gently in the breeze. People \
are out and about, enjoying the lovely weather. \
Some are having picnics, while others are playing \
games or simply relaxing on the grass. It's a \
perfect day to spend time outdoors and appreciate the \
beauty of nature.
`
prompt := `
You will be provided with text delimited by two double quotes.
If it contains a sequence of instructions, \
re-write those instructions in the following format:
Step 1 - ...
Step 2 - …
…
Step N - …
If the text does not contain a sequence of instructions, \
then simply write \"No steps provided.
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text2))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
No steps provided.
1.4 提供少量示例
func main() {
prompt := `
Your task is to answer in a consistent style.
<child>: Teach me about patience.
<grandparent>: The river that carves the deepest \
valley flows from a modest spring; the \
grandest symphony originates from a single note; \
the most intricate tapestry begins with a solitary thread.
<child>: Teach me about resilience.
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
<grandparent>: Resilience is like the mighty oak that withstands the strongest of storms, bending but never breaking. It is the spirit that rises from adversity, the strength that perseveres in the face of challenges. Like the phoenix that rises from the ashes, resilience is the ability to bounce back and thrive, no matter the circumstances.
2.1 指定完成任务所需的步骤
func main() {
text := `
In a charming village, siblings Jack and Jill set out on \
a quest to fetch water from a hilltop \
well. As they climbed, singing joyfully, misfortune \
struck—Jack tripped on a stone and tumbled \
down the hill, with Jill following suit. \
Though slightly battered, the pair returned home to \
comforting embraces. Despite the mishap, \
their adventurous spirits remained undimmed, and they \
continued exploring with delight.
`
prompt1 := `
Perform the following actions:
1 - Summarize the following text delimited by two double \
backticks with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the following \
keys: french_summary, num_names.
Separate your answers with line breaks.
Text:
"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt1, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println("Completion for prompt 1: \n", resp.Choices[0].Message.Content)
}
输出:
Completion for prompt 1:
1 - Jack and Jill, despite a mishap on their quest for water, returned home with adventurous spirits undimmed.
2 - Jack et Jill, malgré un accident dans leur quête d'eau, sont rentrés chez eux avec des esprits aventureux intacts.
3 - Jack, Jill
4 -
{
"french_summary": "Jack et Jill, malgré un accident dans leur quête d'eau, sont rentrés chez eux avec des esprits aventureux intacts.",
"num_names": 2
}
func main() {
text := `
In a charming village, siblings Jack and Jill set out on \
a quest to fetch water from a hilltop \
well. As they climbed, singing joyfully, misfortune \
struck—Jack tripped on a stone and tumbled \
down the hill, with Jill following suit. \
Though slightly battered, the pair returned home to \
comforting embraces. Despite the mishap, \
their adventurous spirits remained undimmed, and they \
continued exploring with delight.
`
prompt2 := `
Your task is to perform the following actions:
1 - Summarize the following text delimited by <> with 1 sentence.
2 - Translate the summary into French.
3 - List each name in the French summary.
4 - Output a json object that contains the
following keys: french_summary, num_names.
Use the following format:
Text: <text to summarize>
Summary: <summary>
Translation: <summary translation>
Names: <list of names in French summary>
Output JSON: <json with summary and num_names>
Text: <%s>
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt2, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println("Completion for prompt 2: \n", resp.Choices[0].Message.Content)
}
输出:
Completion for prompt 2:
Summary: Jack and Jill, siblings, go on a quest to fetch water from a hilltop well but face misfortune on the way back home.
Translation: Jack et Jill, frère et sœur, partent à la quête d'eau d'un puits au sommet d'une colline mais font face à la malchance en rentrant chez eux.
Names: Jack, Jill
Output JSON:
{
"french_summary": "Jack et Jill, frère et sœur, partent à la quête d'eau d'un puits au sommet d'une colline mais font face à la malchance en rentrant chez eux.",
"num_names": 2
}
2.2 指导模型在下结论之前找出一个自己的解法
func main() {
prompt := `
Determine if the student's solution is correct or not.
Question:
I'm building a solar power installation and I need \
help working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations
as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
The student's solution is correct. They have correctly calculated the total cost for the first year of operations as a function of the number of square feet.
func main() {
prompt := `
Your task is to determine if the student's solution \
is correct or not.
To solve the problem do the following:
- First, work out your own solution to the problem.
- Then compare your solution to the student's solution \
and evaluate if the student's solution is correct or not.
Don't decide if the student's solution is correct until
you have done the problem yourself.
Use the following format:
Question:
I'm building a solar power installation and I need \
help working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost \
me a flat $100k per year, and an additional $10 / square \
foot
What is the total cost for the first year of operations
as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 100x
Total cost: 100x + 250x + 100,000 + 100x = 450x + 100,000
Actual solution:
Is the student's solution the same as actual solution \
just calculated:
Student grade:
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
Question:
I'm building a solar power installation and I need help working out the financials.
- Land costs $100 / square foot
- I can buy solar panels for $250 / square foot
- I negotiated a contract for maintenance that will cost me a flat $100k per year, and an additional $10 / square foot
What is the total cost for the first year of operations as a function of the number of square feet.
Student's Solution:
Let x be the size of the installation in square feet.
Costs:
1. Land cost: 100x
2. Solar panel cost: 250x
3. Maintenance cost: 100,000 + 10x
Total cost: 100x + 250x + 100,000 + 10x = 360x + 100,000
Actual solution:
Total cost = Land cost + Solar panel cost + Maintenance cost
Total cost = 100x + 250x + 100,000 + 10x
Total cost = 360x + 100,000
Is the student's solution the same as the actual solution just calculated:
No, the student's solution for the maintenance cost is incorrect. The correct maintenance cost is $100,000 + $10x, not $100,000 + 10x. Therefore, the student's total cost is also incorrect.
Student grade:
F. The student's solution is not correct. They made an error in calculating the maintenance cost.
3.1 幻觉
func main() {
prompt := `
Tell me about AeroGlide UltraSlim Smart Toothbrush by Boie
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
The AeroGlide UltraSlim Smart Toothbrush by Boie is a toothbrush designed to provide a comfortable and effective brushing experience. It features a slim and sleek design that allows it to easily reach all areas of the mouth, including tight spaces and the back of the mouth.
The toothbrush is equipped with smart technology that monitors your brushing habits and provides real-time feedback to help you improve your technique. It also has a gentle vibrating motion that helps to remove plaque and food particles without causing discomfort or irritation to the gums.
Additionally, the AeroGlide UltraSlim Smart Toothbrush is made with high-quality, durable materials that are designed to last, and it is easy to clean and maintain. It is a convenient and practical option for those looking to upgrade their oral hygiene routine.
迭代优化Iterative
没有适用于所有场景的最佳Prompt,开发高效Prompt的关键在于找个一个好的迭代优化过程。通过快速试错迭代,有效确定特定应用的最佳Prompt形式。
产品说明书生成营销产品描述
示例:给定一份椅子的资料页。描述说它属于中世纪灵感系列,产自意大利,并介绍了材料、构造、尺寸、可选配件等参数。
初始提示
func main() {
text := `
概述
美丽的中世纪风格办公家具系列的一部分,包括文件柜、办公桌、书柜、会议桌等。
多种外壳颜色和底座涂层可选。
可选塑料前后靠背装饰(SWC-100)或10种面料和6种皮革的全面装饰(SWC-110)。
底座涂层选项为:不锈钢、哑光黑色、光泽白色或铬。
椅子可带或不带扶手。
适用于家庭或商业场所。
符合合同使用资格。
结构
五个轮子的塑料涂层铝底座。
气动椅子调节,方便升降。
尺寸
宽度53厘米|20.87英寸
深度51厘米|20.08英寸
高度80厘米|31.50英寸
座椅高度44厘米|17.32英寸
座椅深度41厘米|16.14英寸
选项
软地板或硬地板滚轮选项。
两种座椅泡沫密度可选:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。
无扶手或8个位置PU扶手。
材料
外壳底座滑动件
改性尼龙PA6/PA66涂层的铸铝。
外壳厚度:10毫米。
座椅
HD36泡沫
原产国
意大利
`
prompt := `
您的任务是帮助营销团队基于技术说明书创建一个产品的营销描述。
根据两个双引号标记的技术说明书中提供的信息,编写一个产品描述。
技术说明: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
产品描述:
我们自豪地推出了美丽的中世纪风格办公家具系列的一部分——我们的办公椅。这款办公椅包括了文件柜、办公桌、书柜、会议桌等,为您的办公室带来了高雅与实用的完美结合。
这款办公椅可选择多种外壳颜色和底座涂层,同时可选塑料前后靠背装饰或多种面料和皮革装饰。底座涂层选项包括不锈钢、哑光黑色、光泽白色或铬,椅子可带或不带扶手,适用于家庭或商业场所,并符合合同使用资格。
其结构设计采用了五个轮子的塑料涂层铝底座,并配备气动椅子调节,方便升降。
此外,我们的办公椅尺寸紧凑,适合各种场所使用。您可以选择软地板或硬地板滚轮,两种座椅泡沫密度可选,以及选择带有或无扶手的版本。
这款办公椅使用改性尼龙PA6/PA66涂层的铸铝和HD36泡沫材料制成,原产国为意大利。
无论是家庭办公室还是商业办公室,我们的办公椅都能为您的工作场所带来舒适和高雅。
优化1:解决生成文本太长
在Prompt中添加长度限制,生成更简洁的文案
func main() {
text := `
概述
美丽的中世纪风格办公家具系列的一部分,包括文件柜、办公桌、书柜、会议桌等。
多种外壳颜色和底座涂层可选。
可选塑料前后靠背装饰(SWC-100)或10种面料和6种皮革的全面装饰(SWC-110)。
底座涂层选项为:不锈钢、哑光黑色、光泽白色或铬。
椅子可带或不带扶手。
适用于家庭或商业场所。
符合合同使用资格。
结构
五个轮子的塑料涂层铝底座。
气动椅子调节,方便升降。
尺寸
宽度53厘米|20.87英寸
深度51厘米|20.08英寸
高度80厘米|31.50英寸
座椅高度44厘米|17.32英寸
座椅深度41厘米|16.14英寸
选项
软地板或硬地板滚轮选项。
两种座椅泡沫密度可选:中等(1.8磅/立方英尺)或高(2.8磅/立方英尺)。
无扶手或8个位置PU扶手。
材料
外壳底座滑动件
改性尼龙PA6/PA66涂层的铸铝。
外壳厚度:10毫米。
座椅
HD36泡沫
原产国
意大利
`
prompt := `
您的任务是帮助营销团队基于技术说明书创建一个产品的营销描述。
根据两个双引号标记的技术说明书中提供的信息,编写一个产品描述。
使用最多50个词。
技术说明: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
}
输出:
产品描述:
我们的中世纪风格办公家具系列包括文件柜、办公桌、书柜和会议桌,外壳颜色和底座涂层可定制。座椅可选择意大利,符合合同使用资格。
虽然语言模型对长度约束的遵循不是百分之百精确,但通过迭代测试可以找到最佳的长度提示表达式,使生成文本基本符合长度要求。 因为语言模型在计算和判断文本长度时依赖于分词器,而分词器在字符统计方面不具备完美精度。
优化2:处理抓错文本细节
根据不同目标受众关注不同的方面,输出风格和内容都适合的文本。
prompt := `
您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。
根据两个双引号标记的技术说明书中提供的信息,编写一个产品描述。
该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。
使用最多50个单词。
技术规格: "%s"
`
输出:
产品描述:中世纪风格办公家具系列,包括文件柜、办公桌、书柜、会议桌等。可供选择多种外壳颜色和底座涂层,尺寸为宽53厘米、深51厘米、高80厘米。材料包括改性尼龙PA6/PA66涂层的铸铝和HD36泡沫。原产国为意大利。
通过修改Prompt,模型关注点变成了具体特征与技术细节。如果想要进一步展示出具体产品的ID,可以再次修改Prompt.
prompt := `
您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。
根据两个双引号标记的技术说明书中提供的信息,编写一个产品描述。
该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。
在描述末尾,包括技术规格中每个7个字符的产品ID.
使用最多50个单词。
技术规格: "%s"
`
输出:
该产品是美丽的中世纪风格办公家具系列的一部分,包括文件柜、办公桌和书柜。外壳颜色和底座涂层可选,可选塑不带扶手,适用于家庭或商业场所。结构包括塑料涂层铝底座和气动椅子调节。尺寸为53厘米宽、51厘米深、80厘米包括改性尼龙PA6/PA66涂层的铸铝外壳底座滑动件和HD36泡沫座椅。原产国为意大利。产品ID:SWC-100。
Prompt设计是一个循序渐进的过程,需要做好多次尝试和错误的准备,通过不断调整和优化,才能找到最符合具体场景的Prompt方式。
优化3:添加表格描述
继续迭代优化,要求提取产品尺寸信息并组织成表格,并指定表格的列、表名和格式;再将所有内容格式化为可以在网页使用的HTML。
prompt := `
您的任务是帮助营销团队基于技术说明书创建一个产品的零售网站描述。
根据两个双引号标记的技术说明书中提供的信息,编写一个产品描述。
该描述面向家具零售商,因此应具有技术性质,并侧重于产品的材料构造。
在描述末尾,包括技术规格中每个7个字符的产品ID。
在描述之后,包括一个表格,提供产品的尺寸。表格应该有两列。第一列包括尺寸的名称。第二列只包括英寸的测量值。
给表格命名为"产品尺寸"。
将所有内容格式化为可用于网站的HTML格式。将描述放在<div>元素中。
技术规格: "%s"
`
输出:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1.0">
<title>Product Description</title>
</head>
<body>
<div>
<h2>产品描述</h2>
<p>我们隆重推出美丽的中世纪风格办公家具系列,包括文件柜、办公桌、书柜、会议桌等。您可以根据饰。底座涂层选项为不锈钢、哑光黑色、光泽白色或铬,而椅子可选择带扶手或不带扶手。这些家具适用于家庭或商业场所,并且符合合同使用资格。</p>
<p>产品的结构特点包括五个轮子的塑料涂层铝底座和气动椅子调节功能,方便升降。</p>
<h3>材料构造</h3>
<p>外壳底座滑动件由改性尼龙PA6/PA66涂层的铸铝制成,外壳厚度为10毫米。而座椅使用了HD36泡沫材料。</p>
<p>产品ID: 5623874</p>
</div>
<h2>产品尺寸</h2>
<table>
<tr>
<td>宽度</td>
<td>20.87英寸</td>
</tr>
<tr>
<td>深度</td>
<td>20.08英寸</td>
</tr>
<tr>
<td>高度</td>
<td>31.50英寸</td>
</tr>
<tr>
<td>座椅高度</td>
<td>17.32英寸</td>
</tr>
<tr>
<td>座椅深度</td>
<td>16.14英寸</td>
</tr>
</table>
</body>
</html>
浏览器查看
产品描述
我们隆重推出美丽的中世纪风格办公家具系列,包括文件柜、办公桌、书柜、会议桌等。您可以根据饰。底座涂层选项为不锈钢、哑光黑色、光泽白色或铬,而椅子可选择带扶手或不带扶手。这些家具适用于家庭或商业场所,并且符合合同使用资格。
产品的结构特点包括五个轮子的塑料涂层铝底座和气动椅子调节功能,方便升降。
材料构造
外壳底座滑动件由改性尼龙PA6/PA66涂层的铸铝制成,外壳厚度为10毫米。而座椅使用了HD36泡沫材料。
产品ID: 5623874
产品尺寸
宽度 20.87英寸
深度 20.08英寸
高度 31.50英寸
座椅高度 17.32英寸
座椅深度 16.14英寸
总结
Prompt的核心是掌握Prompt的迭代开发和优化技巧,通过不断调整试错,最终找到可靠适用的Prompt形式才是Prompt设计的正确方法。
英文原版
产品说明书:
text := `
OVERVIEW
- Part of a beautiful family of mid-century inspired office furniture,
including filing cabinets, desks, bookcases, meeting tables, and more.
- Several options of shell color and base finishes.
- Available with plastic back and front upholstery (SWC-100)
or full upholstery (SWC-110) in 10 fabric and 6 leather options.
- Base finish options are: stainless steel, matte black,
gloss white, or chrome.
- Chair is available with or without armrests.
- Suitable for home or business settings.
- Qualified for contract use.
CONSTRUCTION
- 5-wheel plastic coated aluminum base.
- Pneumatic chair adjust for easy raise/lower action.
DIMENSIONS
- WIDTH 53 CM | 20.87”
- DEPTH 51 CM | 20.08”
- HEIGHT 80 CM | 31.50”
- SEAT HEIGHT 44 CM | 17.32”
- SEAT DEPTH 41 CM | 16.14”
OPTIONS
- Soft or hard-floor caster options.
- Two choices of seat foam densities:
medium (1.8 lb/ft3) or high (2.8 lb/ft3)
- Armless or 8 position PU armrests
MATERIALS
SHELL BASE GLIDER
- Cast Aluminum with modified nylon PA6/PA66 coating.
- Shell thickness: 10 mm.
SEAT
- HD36 foam
COUNTRY OF ORIGIN
- Italy
`
1.1 英文初始提示
prompt := `
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
two double quotes.
Technical specifications: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
输出:
Introducing our new mid-century inspired office chair, the perfect addition to any home or business setting. This chair is part of a beautiful family of office furniture, offering a range of options for shell color and base finishes to suit your personal style.
Choose from plastic back and front upholstery or full upholstery in a variety of fabric and leather options. The chair is also available with or without armrests, allowing you to customize it to your specific needs.
Constructed with a 5-wheel plastic coated aluminum base and a pneumatic chair adjust, this chair offers easy raise/lower action for maximum comfort. With dimensions of 53 cm in width, 51 cm in depth, and a seat height of 44 cm, this chair is both stylish and practical.
You also have the option to choose between soft or hard-floor casters and two choices of seat foam densities. The materials used are of the highest quality and the chair is qualified for contract use, making it a durable and long-lasting investment.
Designed and crafted in Italy, this office chair embodies both style and functionality, making it the perfect addition to any workspace. Elevate your office space with our mid-century inspired office chair today.
1.2 限制生成长度
prompt := `
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
two double quotes.
Use at most 50 words.
Technical specifications: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
输出:
Elevate your office space with our mid-century inspired office chair. With multiple shell color and base finish options, as well as upholstery choices in fabric or leather, you can customize it to fit your style. Designed for both home and business settings, this chair is perfect for any environment. Made in Italy with high-quality materials, this chair is a stylish and functional addition to any workspace.
1.3 处理抓错文本细节
prompt := `
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
two double quotes.
The description is intended for furniture retailers,
so should be technical in nature and focus on the
materials the product is constructed from.
Use at most 50 words.
Technical specifications: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
输出:
Introducing the SWC-100 and SWC-110 office chairs, part of our mid-century inspired furniture collection. Choose from a variety of shell colors and base finishes, with options for upholstery in fabric or leather. Constructed with a 5-wheel plastic-coated aluminum base and high-quality foam, these chairs are perfect for any home or business setting. Made in Italy.
在描述末尾包含 7个字符的产品ID
prompt := `
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
two double quotes.
The description is intended for furniture retailers,
so should be technical in nature and focus on the
materials the product is constructed from.
At the end of the description, include every 7-character
Product ID in the technical specification.
Use at most 50 words.
Technical specifications: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
输出:
Introducing our mid-century inspired office chair, available in a variety of shell colors and base finishes. With options for plastic or full upholstery in fabric or leather, and a range of armrest and caster choices, this chair is perfect for any home or business setting. Constructed with a 5-wheel plastic coated aluminum base and high-quality foam, this chair offers both style and durability. Made in Italy.
Product IDs: SWC-100, SWC-110
1.4 英文添加表格描述
prompt := `
Your task is to help a marketing team create a
description for a retail website of a product based
on a technical fact sheet.
Write a product description based on the information
provided in the technical specifications delimited by
two double quotes.
The description is intended for furniture retailers,
so should be technical in nature and focus on the
materials the product is constructed from.
At the end of the description, include every 7-character
Product ID in the technical specification.
After the description, include a table that gives the
product's dimensions. The table should have two columns.
In the first column include the name of the dimension.
In the second column include the measurements in inches only.
Give the table the title 'Product Dimensions'.
Format everything as HTML that can be used in a website.
Place the description in a <div> element.
Technical specifications: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
输出:
<div>
<p>This mid-century inspired office chair is the perfect addition to any home or business setting. The chair is available with various options for shell color, base finishes, and upholstery, making it easy to find the perfect match for any decor. The 5-wheel plastic coated aluminum base provides stability and maneuverability, while the pneumatic chair adjustment allows for easy raise/lower action. The seat is constructed with HD36 foam for ultimate comfort, and the shell base glider is made of cast aluminum with a modified nylon PA6/PA66 coating. With its stylish design and high-quality construction, this chair is ideal for any office space or meeting room.</p>
<p>Product ID: SWC-100, SWC-110</p>
<table>
<caption>Product Dimensions</caption>
<tr>
<th>WIDTH</th>
<td>20.87 inches</td>
</tr>
<tr>
<th>DEPTH</th>
<td>20.08 inches</td>
</tr>
<tr>
<th>HEIGHT</th>
<td>31.50 inches</td>
</tr>
<tr>
<th>SEAT HEIGHT</th>
<td>17.32 inches</td>
</tr>
<tr>
<th>SEAT DEPTH</th>
<td>16.14 inches</td>
</tr>
</table>
</div>
文本概括Summarizing
单一文本概括
我们提供一段在线商品评价作为示例,可能来自于一个在线购物平台,例如亚马逊、淘宝、京东等。 评价者为一款熊猫公仔进行了点评,评价内容包括商品的质量、大小、价格和物流速度等因素,以及他的女儿对该商品的喜爱程度
text := 这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。 公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说, 它有点小,我感觉在别的地方用同样的价钱能买到更大的。 快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
限制输出文本长度
尝试将文本的长度限制在30个字以内
func main() {
text := `
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
`
prompt := `
您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对两个双引号之间的评论文本进行概括,最多30个字。
评论: "%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
}
输出:
可爱软萌的熊猫公仔,面部表情和善,快递提前一天到货,值得购买。
设置关键角度侧重
在某些情况下,我们会针对不同的业务场景对文本的侧重会有所不同。通过增强输入提示(Prompt),来强调我们对某一特定视角的重视
1.侧重于快递服务
text := `
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
`
prompt := `
您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对两个双引号之间的评论文本进行概括,最多30个字,并且侧重在快递服务上。
评论: "%s"
`
输出:
快递提前一天送到,公仔有点小,性价比一般。
从输出结果可以看出,以快递效率侧重文本开头。
2.侧重于价格与质量
text := `
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
`
prompt := `
您的任务是从电子商务网站上生成一个产品评论的简短摘要。
请对两个双引号之间的评论文本进行概括,最多30个字,并且侧重在产品价格和质量上。
评论: "%s"
输出:
熊猫公仔贵但可爱,尺寸小一些。质量好,面部表情和善。快递提前到货。
从输出结果来看,确实侧重了价格和质量。
关键信息提取
如果我们只想要提取某一角度的信息,并过滤掉其他所有信息,则可以要求LLM进行文本提取(Extract)而非概括(Summarize)
text := `
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
`
prompt := `
您的任务是从电子商务网站上的产品评论中提取相关信息。
请对两个双引号之间的评论文本中提取产品运输相关的信息,最多30个字。
评论: "%s"
`
输出:
快递比预期提前了一天到货。
同时概括多条文本
在实际工作中,往往要处理大量的评论文本,下面示例展示将多条用户评论集中在一起,利用for循环和文本概括提示词,将评论概括在20个词以内,并按顺序打印。
func main() {
text1 := `
这个熊猫公仔是我给女儿的生日礼物,她很喜欢,去哪都带着。
公仔很软,超级可爱,面部表情也很和善。但是相比于价钱来说,
它有点小,我感觉在别的地方用同样的价钱能买到更大的。
快递比预期提前了一天到货,所以在送给女儿之前,我自己玩了会。
`
// 评论一盏落地灯
text2 := `
我需要一盏漂亮的卧室灯,这款灯不仅具备额外的储物功能,价格也并不算太高。
收货速度非常快,仅用了两天的时间就送到了。
不过,在运输过程中,灯的拉线出了问题,幸好,公司很乐意寄送了一根全新的灯线。
新的灯线也很快就送到手了,只用了几天的时间。
装配非常容易。然而,之后我发现有一个零件丢失了,于是我联系了客服,他们迅速地给我寄来了缺失的零件!
对我来说,这是一家非常关心客户和产品的优秀公司。
`
// 评论一把电动牙刷
text3 := `
我的牙科卫生员推荐了电动牙刷,所以我就买了这款。
到目前为止,电池续航表现相当不错。
初次充电后,我在第一周一直将充电器插着,为的是对电池进行条件养护。
过去的3周里,我每天早晚都使用它刷牙,但电池依然维持着原来的充电状态。
不过,牙刷头太小了。我见过比这个牙刷头还大的婴儿牙刷。
我希望牙刷头更大一些,带有不同长度的刷毛,
这样可以更好地清洁牙齿间的空隙,但这款牙刷做不到。
总的来说,如果你能以50美元左右的价格购买到这款牙刷,那是一个不错的交易。
制造商的替换刷头相当昂贵,但你可以购买价格更为合理的通用刷头。
这款牙刷让我感觉就像每天都去了一次牙医,我的牙齿感觉非常干净!
`
// 评论一台搅拌机
text4 := `
在11月份期间,这个17件套装还在季节性促销中,售价约为49美元,打了五折左右。可是由于某种原因(我们可以称之为价格上涨),到了12月的第二周,所有的价格都上涨了,
同样的套装价格涨到了70-89美元不等。而11件套装的价格也从之前的29美元上涨了约10美元。看起来还算不错,但是如果你仔细看底座,刀片锁定的部分看起来没有前几年版本的那么漂亮。
然而,我打算非常小心地使用它(例如,我会先在搅拌机中研磨豆类、冰块、大米等坚硬的食物,然后再将它们研磨成所需的粒度,接着切换到打蛋器刀片以获得更细的面粉,如果我需要制作更细腻/少果肉的食物)。
在制作冰沙时,我会将要使用的水果和蔬菜切成细小块并冷冻(如果使用菠菜,我会先轻微煮熟菠菜,然后冷冻,直到使用时准备食用。
如果要制作冰糕,我会使用一个小到中号的食物加工器),这样你就可以避免添加过多的冰块。大约一年后,电机开始发出奇怪的声音。我打电话给客户服务,但保修期已经过期了,
所以我只好购买了另一台。值得注意的是,这类产品的整体质量在过去几年里有所下降,所以他们在一定程度上依靠品牌认知和消费者忠诚来维持销售。在大约两天内,我收到了新的搅拌机。
`
prompt := `
您的任务是从电子商务网站上的产品评论中提取相关信息。
请对两个双引号之间的评论文本进行概括,最多20个词汇。
评论: "%s"
`
for i, text := range []string{text1, text2, text3, text4} {
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Printf("评论%d: %s\n", i+1, res)
}
}
输出:
评论1: 概括:熊猫公仔生日礼物,女儿喜欢,软可爱,面部表情和善,价钱小,快递提前到货。
评论2: 评论总结: 漂亮卧室灯,带储物功能,价格适中。快速配送,良好售后服务。易装配,客服及时处理问题。
评论3: 推荐的电动牙刷,续航不错,但牙刷头太小,价格合理,给牙齿清洁感觉。
评论4: 评论内容概括:购买17件套装搅拌机,价格先打折再上涨,质量下降,使用注意事项,售后服务需改进。
推断Inferring
这一章让你了解如何从产品评价和新闻文章中推导出情感和主题,包括了标签提取、实体提取、以及理解文本的情感等等
情感推断
情感倾向分析
如何对评论进行情感二分类(正面/负面),让系统自动解析这条评论的情感倾向
text := `
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
`
prompt := `
以下用两个双引号分隔的产品评论的情感是什么?
评论文本: "%s"
`
输出:
积极的情感。
可以使用更简介的输出,比如用一个单词回答
text := `
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
`
prompt := `
以下用两个双引号分隔的产品评论的情感是什么?
用一个单词回答: 正面或负面
评论文本: "%s"
`
识别情感类型
让模型能够识别出评论作者所表达的情感,将这些情感整理为一个不超过五项的列表
text := `
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
`
prompt := `
识别以下评论的作者表达的情感。包含不超过五个项目。将答案格式化为以逗号分隔的单词列表。
评论文本: "%s"
`
输出:
满意,感激,信任,高兴,愉快
识别愤怒
洞察到愤怒情绪至关重要
text := `
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
`
prompt := `
以下评论的作者是否表达了愤怒?评论用两个双引号分隔。给出是或否的答案。
评论文本: "%s"
`
输出:
否
信息提取
商品信息提取
信息提取能够帮助我们从文本中抽取特定、关注的信息
示例:要求模型返回一个json对象,其中key是商品和品牌
text := `
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
`
prompt := `
从评论文本中识别以下项目:
- 评论者购买的物品
- 制造该物品的公司
评论文本用两个双引号分隔。将你的响应格式化为以"物品"和"品牌"为键的json对象。
如果信息不存在,请使用"未知"作为值。
让你的回应尽可能简短。
评论文本: "%s"
`
输出:
{
"物品": "卧室灯",
"品牌": "Lumina"
}
综合情感推断和信息提取
设计一个单一的prompt,来同时提取所有这些信息
text := `
我需要一盏漂亮的卧室灯,这款灯具有额外的储物功能,价格也不算太高。\
我很快就收到了它。在运输过程中,我们的灯绳断了,但是公司很乐意寄送了一个新的。\
几天后就收到了。这款灯很容易组装。我发现少了一个零件,于是联系了他们的客服,他们很快就给我寄来了缺失的零件!\
在我看来,Lumina 是一家非常关心顾客和产品的优秀公司!
`
prompt := `
从评论文本中识别以下项目:
- 情绪(正面或负面)
- 审稿人是否表达了愤怒?(是或否)
- 评论者购买的物品
- 制造该物品的公司
评论用两个双引号分隔。将你的响应格式化为JSON对象,以"情感倾向"、"是否生气"、"物品类型"和"品牌"作为键。
如果信息不存在,请使用"未知"作为值。
让你的回应尽可能简短。
将"是否生气"值格式化为布尔值。
评论文本: "%s"
`
输出:
{
"情感倾向": "正面",
"是否生气": false,
"物品类型": "卧室灯",
"品牌": "Lumina"
}
主题推断
根据一段长文本,判断这段文本的主旨,涉及了哪些主题
text := `
在政府最近进行的一项调查中,要求公共部门的员工对他们所在部门的满意度进行评分。
调查结果显示,NASA是最受欢迎的部门,满意度为95%。
一位NASA员工John Smith对这一发现发表了评论,他表示:
我对NASA排名第一并不感到惊讶。这是一个与了不起的人们和令人难以置信的机会共事的好地方。我为成为这样一个创新组织的一员感到自豪。
NASA的管理团队也对这一结果表示欢迎,主管Tom Johnson表示:
我们很高兴听到我们的员工对NASA的工作感到满意。
我们拥有一支才华横溢、忠诚敬业的团队,他们为实现我们的目标不懈努力,看到他们的辛勤工作得到回报是太棒了。
调查还显示,社会保障管理局的满意度最低,只有45%的员工表示他们对工作满意。
政府承诺解决调查中员工提出的问题,并努力提高所有部门的工作满意度。
`
推断讨论主题
prompt := `
将以下两个双引号分隔的给定文本中讨论的五个主题,每个主题用1-2个词概括,输出一个可解析的Python语言列表,每个元素是一个字符串,展示了一个主题。
给定文本: "%s"
`
输出:
["NASA", "员工满意度调查", "John Smith评论", "Tom Johnson评论", "社会保障管理局"]
为特定主题制作新闻提醒
rompt := `
判断主题列表中的每一项是否是以下给定文本中的一个话题,
以列表的形式给出答案,每个元素是一个Json对象,键为对应主题,值为对应的0或1。
主题列表:美国航空航天局、当地政府、工程、员工满意度、联邦政府
给定文本: "%s"
`
输出:
[
{"美国航空航天局": 1},
{"当地政府": 1},
{"工程": 0},
{"员工满意度": 1},
{"联邦政府": 1}
]
在机器学习领域这种称为零样本学习,没有提供任何带标签的训练数据,凭借Prompt,就能判定哪些主题被包含。
文本转换
文本扩展是大语言模型的一个重要应用方向,输入简短文本,生成更加丰富的长文。
定制客户邮件
根据客户的评价和其中的情感倾向,使用语言模型针对性生成回复邮件。先输入客户的评论文本和对应的情感分析结果(正面或者负面)。 然后构造一个Prompt,要求大语言模型基于这些信息来生成一封定制的回复电子邮件。
示例:首先明确大语言模型的身份是客户服务AI助手;它任务是为客户发送电子邮件回复; 然后在三个反引号间给出具体的客户评论;最后要求语言模型根据这条反馈邮件生成一封回复,以感谢客户的评价
text := `
他们在11月份的季节性销售期间以约49美元的价格出售17件套装,折扣约为一半。\
但由于某些原因(可能是价格欺诈),到了12月第二周,同样的套装价格全都涨到了70美元到89美元不等。\
11件套装的价格也上涨了大约10美元左右。\
虽然外观看起来还可以,但基座上锁定刀片的部分看起来不如几年前的早期版本那么好。\
不过我打算非常温柔地使用它,例如,\
我会先在搅拌机中将像豆子、冰、米饭等硬物研磨,然后再制成所需的份量,\
切换到打蛋器制作更细的面粉,或者在制作冰沙时先使用交叉切割刀片,然后使用平面刀片制作更细/不粘的效果。\
制作冰沙时,特别提示:\
将水果和蔬菜切碎并冷冻(如果使用菠菜,则轻轻煮软菠菜,然后冷冻直到使用;\
如果制作果酱,则使用小到中号的食品处理器),这样可以避免在制作冰沙时添加太多冰块。\
大约一年后,电机发出奇怪的噪音,我打电话给客服,但保修已经过期了,所以我不得不再买一个。\
总的来说,这些产品的总体质量已经下降,因此它们依靠品牌认可和消费者忠诚度来维持销售。\
货物在两天内到达。
`
prompt := `
你是一位客户服务的AI助手。
你的任务是给一位重要客户发送邮件回复。
根据客户通过两个双引号分隔的评价,生成回复以感谢客户的评价。提醒模型使用评价中的具体细节
用简明而专业的语气写信。作为"AI客户代理"签署电子邮件。
客户评论: "%s"
评论情感:消极的。
`
输出:
尊敬的客户,
非常感谢您的反馈,我们对您在11月份的购买经历感到十分抱歉。我们一直致力于提供高品质的产品,但很明显您对最近购买的套装不满意。关于您提到的品质问题和售后服务经验,我们会将您的意见反馈给相关部门,以便改进和提高我们的产品和服务质量。
同时,我们也感谢您提供了关于产品使用和维护的建议。您的经验分享对其他客户来说也将非常有帮助。我们将注意到您提到的制作冰沙的技巧,以及保持电机使用寿命的方法。
如果您有任何进一步的问题或需求,请随时与我们联系。我们会尽力为您提供更好的服务和支持。
再次感谢您对我们的支持和反馈。
祝您生活愉快!
AI客户代理
引入温度系数
大语言模型中的温度参数可以控制生成文本的随机性和多样性,temperature 的值越大,语言模型输出的多样性越大; temperature的值越小,输出越倾向高概率的文本。一般需要可预测、可靠的输出,就把temperature设置为0。
示例:针对同一段来信,我们提醒语言模型使用用户来信中的详细信息,并设置一个较高的temperature ,运行两次,比较他们的结果。
第一次输出:
尊敬的客户,
非常感谢您对我们产品的详细评价。我们对您在购买过程中遇到的问题感到抱歉,我们会认真考虑您提出的问题,并努力改进产品质量和服务。
对于价格上涨和产品质量下降的问题,我们深表歉意。我们会进一步调查此事,并确保未来的销售活动和产品质量能够得到改善。同时,我们也会加强售后服务,以确保客户在使用产品时能够得到及时的支持和帮助。
如果您需要进一步的帮助或有任何其他问题,请随时联系我们的客户服务团队。我们将竭诚为您提供支持并解决您的问题。
再次感谢您的宝贵意见,期待未来能够为您提供更好的产品和服务。
祝您生活愉快!
AI客户代理
第二次输出:
尊敬的客户,
感谢您给出的详细评价,我们对您的反馈感到非常抱歉。我们对您遇到的问题感到遗憾,我们将会进一步改进我们的产品质量和服务。
请您联系我们的客户服务部门,以便我们可以进一步了解您的情况并为您提供帮助。我们将竭尽全力解决您的问题,并确保您的满意度。
再次感谢您的反馈,我们期待能够为您提供更好的服务和产品体验。
祝您一切顺利,
AI客户代理
温度(temperature)参数可以控制语言模型生成文本的随机性。
聊天机器人
大语言模型让构建定制的聊天机器人,只需要很少的工作量。类似ChatGPT这样的聊天模型实际上是一系列消息作为输入, 并返回一个模型生成的消息作为输出。
给定身份
要区分系统消息、用户消息、助手消息;系统消息有助于设置助手的行为和角色,并作为对话的高级指示。ChatGPT的系统消息是屏蔽了的,为了不让请求称为对话的一部分, 引导助手并指导其回应。举个例子:在ChatGPT网页中,你的消息就称为用户消息,ChatGPT的消息就称为助手消息。但是在构建聊天机器人时,发送了系统消息后,你可以作为用户, 也可以在用户和助手之间切换,从而提供对话上下文。
新增个函数定义,可以接收消息列表,这些消息来自不同的角色
func (c *openAIClient) CreateChatCompletionWithMessage(ctx context.Context, messages []openai.ChatCompletionMessage) (openai.ChatCompletionResponse, error) {
return c.Client.CreateChatCompletion(ctx, openai.ChatCompletionRequest{
Model: openai.GPT3Dot5Turbo,
Messages: messages,
Temperature: 1,
})
}
讲笑话
通过系统消息来定义:“你是一个说话像莎士比亚的助手。“这是我们向助手描述它应该如何表现的方式。
然后,第一个用户消息:“给我讲个笑话。”
接下来以助手身份给出回复:“为什么鸡会过马路?”
最后发送用户消息是:“我不知道。”
func main() {
client := newOpenAIClient()
messages := []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleSystem,
Content: "你是一个像莎士比亚一样说话的助手。",
},
{
Role: openai.ChatMessageRoleUser,
Content: "给我讲个笑话",
},
{
Role: openai.ChatMessageRoleAssistant,
Content: "鸡为什么过马路",
},
{
Role: openai.ChatMessageRoleUser,
Content: "我不知道",
},
}
resp, err := client.CreateChatCompletionWithMessage(context.TODO(), messages)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
}
输出:
因为它想证明自己并不只是个胆小鬼!哈哈哈!
友好的聊天机器人
系统消息定义:“你是一个友好的聊天机器人”,第一个用户消息:“嗨,我叫lsa。”
func main() {
client := newOpenAIClient()
messages := []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleSystem,
Content: "你是个友好的聊天机器人",
},
{
Role: openai.ChatMessageRoleUser,
Content: "Hi,我是Isa",
},
}
resp, err := client.CreateChatCompletionWithMessage(context.TODO(), messages)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
}
输出:
你好Isa,很高兴认识你!有什么可以帮助你的吗?
构建上下文
系统消息来定义:“你是一个友好的聊天机器人”,第一个用户消息:“是的,你能提醒我我的名字是什么吗?”
messages := []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleSystem,
Content: "你是个友好的聊天机器人。",
},
{
Role: openai.ChatMessageRoleUser,
Content: "是的,你能提醒我我的名字是什么吗?",
},
}
输出:
当然!您的名字是...嗯...抱歉,我不知道您的名字。您能告诉我一下您的名字吗?我会牢记在心的!
每次与语言模型的交互都互相独立,这意味着我们必须提供所有相关的消息,以便模型在当前对话中进行引用。 如果想让模型引用或"记住"对话的早期部分,则必须在模型的输入中提供早期的交流。我们将其称为上下文 (context)
messages := []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleSystem,
Content: "你是个友好的聊天机器人。",
},
{
Role: openai.ChatMessageRoleUser,
Content: "Hi,我是Isa",
},
{
Role: openai.ChatMessageRoleAssistant,
Content: "Hi Isa!很高兴认识你。今天有什么可以帮到你的吗?",
},
{
Role: openai.ChatMessageRoleUser,
Content: "是的,你可以提醒我,我的名字是什么?",
},
}
输出:
当然,你的名字是Isa。如果你需要我提醒你任何事情,随时告诉我哦!有什么其他问题我可以帮你解决吗?
模型有了上下文,模型就能够做出回应。
订餐机器人
如何构建一个"点餐助手机器人”,这个机器人将被设计为自动收集用户信息,并接收来自披萨店的订单。
构建机器人
新增一个函数,这个函数从我们构建的用户界面中收集prompt,然后添加到上下文context中,并在每次调用模型时使用这个上下文。 模型的返回也会被添加到上下文中
func main() {
client := newOpenAIClient()
messages := []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleSystem,
Content: `你是订餐机器人,为披萨餐厅自动收集订单信息。
你要首先问候顾客。然后等待用户回复收集订单信息。收集完信息需确认顾客是否还需要添加其他内容。
最后需要询问是否自取或外送,如果是外送,你要询问地址。最后告诉顾客订单总金额,并送上祝福。
请确保明确所有选项、附加项和尺寸,以便从菜单中识别出该项唯一的内容。
你的回应应该以简短、非常随意和友好的风格呈现。
菜单包括:
菜品价格:
意式辣香肠披萨(大、中、小) 12.95、10.00、7.00
芝士披萨(大、中、小) 10.95、9.25、6.50
茄子披萨(大、中、小) 11.95、9.75、6.75
薯条(大、小) 4.50、3.50
希腊沙拉 7.25
配料:
奶酪 2.00
蘑菇 1.50
香肠 3.00
加拿大熏肉 3.50
AI酱 1.50
辣椒 1.00
饮料:
可乐(大、中、小) 3.00、2.00、1.00
雪碧(大、中、小) 3.00、2.00、1.00
瓶装水 5.00`,
},
{
Role: openai.ChatMessageRoleAssistant,
Content: "你好!欢迎来到披萨餐厅!您想点什么呢?",
},
}
fmt.Printf("%s: %s\n", messages[1].Role, messages[1].Content)
for {
var s string
fmt.Printf("user: ")
_, err := fmt.Scanf("%s", &s)
if err != nil {
return
}
if s == "end" {
break
}
messages = append(messages, openai.ChatCompletionMessage{
Role: openai.ChatMessageRoleUser,
Content: s,
})
resp, err := client.CreateChatCompletionWithMessage(context.TODO(), messages)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Printf("%s: %s\n", resp.Choices[0].Message.Role, resp.Choices[0].Message.Content)
messages = append(messages, resp.Choices[0].Message)
}
}
输出:
assistant: 你好!欢迎来到披萨餐厅!您想点什么呢?
user: 一杯大可乐
assistant: 好的,您想点什么披萨吗?还是需要其他食物或者饮料?
user: 一份大芝士披萨,配料加蘑菇,还有一份沙拉
assistant: 好的,一份大芝士披萨,配料加蘑菇,还有一份希腊沙拉。您需要外卖还是自取?
user: 自取吧
assistant: 好的,您的订单是一份大芝士披萨(配料加蘑菇)和一份希腊沙拉,自取。总金额是 21.20 元。感谢您的订购!祝您用餐愉快!如果还需要帮助,请随时告诉我。
user: 你可以展示金额是怎么算的吗
assistant: 当然!大芝士披萨 10.95 元 + 配料蘑菇 1.50 元 + 希腊沙拉 7.25 元 = 21.20 元。希望这样清楚明了!祝您用餐愉快!
user: 谢谢
assistant: 不客气!如果您有任何其他问题或需求,请随时告诉我。祝您有美好的一天!
user: end
创建JSON摘要
要求模型创建一个JSON摘要,方便我们发送给订单系统;在上下文的基础上追加另一个系统消息,定义json概要的格式
func main() {
client := newOpenAIClient()
messages := []openai.ChatCompletionMessage{
{
Role: openai.ChatMessageRoleSystem,
Content: `你是订餐机器人,为披萨餐厅自动收集订单信息。
你要首先问候顾客。然后等待用户回复收集订单信息。收集完信息需确认顾客是否还需要添加其他内容。
最后需要询问是否自取或外送,如果是外送,你要询问地址。最后告诉顾客订单总金额,并送上祝福。
请确保明确所有选项、附加项和尺寸,以便从菜单中识别出该项唯一的内容。
你的回应应该以简短、非常随意和友好的风格呈现。
菜单包括:
菜品价格:
意式辣香肠披萨(大、中、小) 12.95、10.00、7.00
芝士披萨(大、中、小) 10.95、9.25、6.50
茄子披萨(大、中、小) 11.95、9.75、6.75
薯条(大、小) 4.50、3.50
希腊沙拉 7.25
配料:
奶酪 2.00
蘑菇 1.50
香肠 3.00
加拿大熏肉 3.50
AI酱 1.50
辣椒 1.00
饮料:
可乐(大、中、小) 3.00、2.00、1.00
雪碧(大、中、小) 3.00、2.00、1.00
瓶装水 5.00`,
},
{
Role: openai.ChatMessageRoleAssistant,
Content: "你好!欢迎来到披萨餐厅!您想点什么呢?",
},
}
fmt.Printf("%s: %s\n", messages[1].Role, messages[1].Content)
for {
var s string
fmt.Printf("user: ")
_, err := fmt.Scanf("%s", &s)
if err != nil {
return
}
if s == "end" {
break
}
messages = append(messages, openai.ChatCompletionMessage{
Role: openai.ChatMessageRoleUser,
Content: s,
})
resp, err := client.CreateChatCompletionWithMessage(context.TODO(), messages)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Printf("%s: %s\n", resp.Choices[0].Message.Role, resp.Choices[0].Message.Content)
messages = append(messages, resp.Choices[0].Message)
}
messages = append(messages, openai.ChatCompletionMessage{
Role: openai.ChatMessageRoleSystem,
Content: `创建上一个食品订单的json摘要。\
逐项列出每件商品的价格,字段应该是 1) 披萨,包括大小 2) 配料列表 3) 饮料列表,包括大小 4) 配菜列表包括大小 5) 总价
你应该给我返回一个可解析的json对象,包括上述字段`,
})
resp, err := client.CreateChatCompletionWithMessage(context.TODO(), messages)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
fmt.Println(resp.Choices[0].Message.Content)
}
输出:
assistant: 你好!欢迎来到披萨餐厅!您想点什么呢?
user: 一杯大可乐
assistant: 好的!您还需要点其他菜品吗?如果需要,请告诉我您的选择。
user: 一份大芝士披萨,配料加蘑菇,还有一份沙拉
assistant: 好的,一份大芝士披萨加蘑菇配料和一份希腊沙拉。请问您是选择自取还是外送呢?如果是外送,请告诉我您的地址。
user: 自取吧
assistant: 好的,您点的菜品是一份大芝士披萨(10.95)加蘑菇配料(1.50)和一份希腊沙拉(7.25),再加一杯大可乐(3.00),总金额为22.70。祝您用餐愉快!如果您有其他需要,请随时告诉我。
user: 你可以展示金额是怎么算的吗
assistant: 当然可以!大芝士披萨(10.95)+ 蘑菇配料(1.50)+ 希腊沙拉(7.25)+ 大可乐(3.00)= 22.70。祝您用餐愉快!如果您有其他需要,请随时告诉我。
user: end
{
"披萨": {
"名称": "大芝士披萨",
"价格": 10.95
},
"配料列表": [
{
"名称": "蘑菇",
"价格": 1.50
}
],
"饮料列表": [
{
"名称": "大可乐",
"价格": 3.00
}
],
"配菜列表": [
{
"名称": "希腊沙拉",
"价格": 7.25
}
],
"总价": 22.70
}
订餐聊天机器人已经能够正常运行,可以自定义机器人的系统消息,改变它的行为,扮演各种不同的角色
Tool调用
示例:假设我们有一个叫 get_weather 的函数,用于获取天气
{
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如:Taipei"
}
},
"required": ["location"]
}
}
tool_call curl请求
curl https://api.openai.com/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-4-0613",
"messages": [
{
"role": "user",
"content": "请告诉我台北的天气"
}
],
"tools": [
{
"type": "function",
"function": {
"name": "get_weather",
"description": "获取指定城市的天气",
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "城市名称,例如:Taipei"
}
},
"required": ["location"]
}
}
}
],
"tool_choice": "auto"
}'
问题:tool_call 实际调用 API 的逻辑在哪里?
- 在OpenAI 的 tool_calls 模型调用流程中, OpenAI 模型本身不会去实际请求任何 API。
- 模型只会决定是否要调用一个“函数”(即工具 / tool),并给出参数。
- 实际的API请求逻辑必须由你在自己后端实现,OpenAI 的接口不会帮你连网或调用真实的第三方服务。
整体流程总结:
User -> OpenAI -> (tool_call: get_weather) -> 你后端调用 API
↑ ↓
←------------------- tool 回复 ----------------
LLM大模型部署
Ollama
简介
Ollama实现一行命令在本地轻松部署大语言模型, 是一个开源框架,专门设计用于在本地运行大型语言模型。从而简化了在本地运行大型模型的过程。Ollama基于llama.cpp之上做了很多封装抽象。
llama.cpp项目是开发者Georgi Gerganov基于Meta开放的LLaMA模型(简易Python代码示例)手撸的纯C/C++版本,用于模型推理。其可执行的模型文件格式为GGUF,GGUF(GPT-Generated Unified Format)格式是用于存储大型模型预训练结果的,相较于Hugging Face和torch的bin文件,它采用了紧凑的二进制编码格式、优化的数据结构以及内存映射等技术,提供了更高效的数据存储和访问方式。GGUF也是由Georgi Gerganov发明的。
安装
部署指引:https://ollama.com/download
本地GGUF模型导入
# vim Modelfile
FROM ./test-33b.Q4_0.gguf
# ollama create example -f Modelfile
参数调优
# vim /etc/systemd/system/ollama.service
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
# 开启debug模式,可以看到更多输出日志
Environment="OLLAMA_DEBUG=1"
Environment="OLLAMA_HOST=0.0.0.0"
# 绑定GPU卡,通过nvidia-smi -L可以查到,多卡使用逗号隔开
Environment="CUDA_VISIBLE_DEVICES=GPU-18089521-10dd-9d6a-88df-cabf9d427d43"
# 最大显存使用,单位byte
Environment="OLLAMA_MAX_VRAM=23192823398"
# 模型加载到显存中的过期时间
Environment="OLLAMA_KEEP_ALIVE=5m"
# 动态库,强制使用GPU,默认情况下在GPU不足的情况下会使用cpu
Environment="OLLAMA_LLM_LIBRARY=cuda_v11"
[Install]
WantedBy=default.target
Ollama第三方生态
- Cody:VSCode编程插件,支持对接Ollama,https://github.com/sourcegraph/cody
- open-webui:Ollama WebUI,https://github.com/open-webui/open-webui
- openui:AI网页生成,支持对接Ollama,https://github.com/wandb/openui
Xinference
企业级分布式推理框架Xinference
后台命令行启动模型
xinference launch --model_path /root/DeepSeek-R1-Distill-Qwen-32B \
--model-name deepseek-v2.5 \
--model-uid deepseek-r1 \
--model-engine vllm \
--model-format pytorch \
--n-gpu 4 \
--max_model_len 32768
Docker部署
准备工作
硬件环境
| 类型 | 规格 |
|---|---|
| CPU | 24核 AMD EPYC 7402 |
| 内存 | 32GB |
| GPU | 2 * NVIDIA GeForce RTX 4090 显存24GB |
| 操作系统 | 银河麒麟v10 |
| 架构 | x86_64 |
| 内核版本 | 4.19.90-23.43.v2101.ky10.x86_64 |
| GPU驱动版本 | 535.146.02 |
| CUDA版本 | 12.2 |
下载huggingface_hub工具
HuggingFace Hub是一个用于分享和获取自然语言处理(NLP)模型和相关资源的平台;类似代码界的GitHub。
pip3安装huggingface_hub工具
# pip3 install -U huggingface_hub
验证huggingface-cli
[root@localhost ~]# huggingface-cli env
Copy-and-paste the text below in your GitHub issue.
- huggingface_hub version: 0.20.3
- Platform: Linux-4.19.90-23.43.v2101.ky10.x86_64-x86_64-with-glibc2.28
- Python version: 3.11.7
- Running in iPython ?: No
- Running in notebook ?: No
- Running in Google Colab ?: No
- Token path ?: /root/.cache/huggingface/token
- Has saved token ?: False
- Configured git credential helpers:
- FastAI: N/A
- Tensorflow: N/A
- Torch: 2.1.2
- Jinja2: 3.1.3
- Graphviz: N/A
- Pydot: N/A
- Pillow: 10.2.0
- hf_transfer: N/A
- gradio: N/A
- tensorboard: N/A
- numpy: 1.26.3
- pydantic: 1.10.13
- aiohttp: N/A
- ENDPOINT: https://huggingface.co
- HF_HUB_CACHE: /root/.cache/huggingface/hub
- HF_ASSETS_CACHE: /root/.cache/huggingface/assets
- HF_TOKEN_PATH: /root/.cache/huggingface/token
- HF_HUB_OFFLINE: False
- HF_HUB_DISABLE_TELEMETRY: False
- HF_HUB_DISABLE_PROGRESS_BARS: None
- HF_HUB_DISABLE_SYMLINKS_WARNING: False
- HF_HUB_DISABLE_EXPERIMENTAL_WARNING: False
- HF_HUB_DISABLE_IMPLICIT_TOKEN: False
- HF_HUB_ENABLE_HF_TRANSFER: False
- HF_HUB_ETAG_TIMEOUT: 10
- HF_HUB_DOWNLOAD_TIMEOUT: 10
修改HF环境变量,使用国内镜像地址https://hf-mirror.com,加速下载模型
[root@localhost ~]# export HF_ENDPOINT=https://hf-mirror.com
第三方工具hfd
使用https://hf-mirror.com/提供的hfd专用下载工具,它是基于成熟工具git+aria2,可以做到稳定下载不断线,测下来比huggingface-cli稳定。
下载hfd工具
wget -c https://hf-mirror.com/hfd/hfd.sh
chmod a+x hfd.sh
下载模型示例
HF_ENDPOINT=https://hf-mirror.com ./hfd.sh <模型> --tool aria2c -x 4
下载数据集示例
HF_ENDPOINT=https://hf-mirror.com ./hfd.sh <数据集> --dataset --tool aria2c -x 4
下载模型
下载模型,以通义千问14b-chat模型为例
# 创建模型目录,用于存放下载的模型文件
[root@localhost ~]# mkdir -p /opt/ice/models/qwen-14b-chat
[root@localhost ~]# huggingface-cli download \
--resume-download --local-dir-use-symlinks False \
--local-dir /opt/ice/models/qwen-14b-chat \
qwen/qwen-14b-chat
Consider using `hf_transfer` for faster downloads. This solution comes with some limitations. See https://huggingface.co/docs/huggingface_hub/hf_transfer for more details.
Fetching 37 files: 0%| | 0/37 [00:00<?, ?it/s]downloading https://hf-mirror.com/qwen/qwen-14b-chat/resolve/cdaff792392504e679496a9f386acf3c1e4333a5/.gitattributes to /root/.cache/huggingface/hub/models--qwen--qwen-14b-chat/blobs/a6344aac8c09253b3b630fb776ae94478aa0275b.incomplete
downloading https://hf-mirror.com/qwen/qwen-14b-chat/resolve/cdaff792392504e679496a9f386acf3c1e4333a5/LICENSE to /root/.cache/huggingface/hub/models--qwen--qwen-14b-chat/blobs/5be33384d19169a98eee863ff09c74eb32e37696.incomplete
下载需要登录的模型(Gated Model),添加参数--token hf_***参数,hf_***是access token,token从这里获取https://huggingface.co/settings/tokens
配置nvidia docker runtime
下载nvidia runtime和工具包,下面启动大模型是采用docker方式来启动的,原生docker runtime不支持GPU
[root@localhost]# yum install -y nvidia-container-toolkit nvidia-container-runtime
生成nvidia runtime的docker配置
[root@localhost]# nvidia-ctk runtime configure --runtime=docker
INFO[0000] Loading docker config from /etc/docker/daemon.json
INFO[0000] Config file does not exist, creating new one
INFO[0000] Wrote updated config to /etc/docker/daemon.json
INFO[0000] It is recommended that the docker daemon be restarted.
[root@localhost qwen-14b]# cat /etc/docker/daemon.json
{
"runtimes": {
"nvidia": {
"args": [],
"path": "nvidia-container-runtime"
}
}
}
[root@localhost]# systemctl restart docker
验证nvidia runtime是否安装成功
[root@localhost]# docker run --rm --runtime=nvidia --gpus all ubuntu nvidia-smi
容器方式运行大模型
下载api-for-open-llm
api-for-open-llm是开源大模型的统一后端接口,与OpenAI的响应保持一致。
# git clone https://github.com/xusenlinzy/api-for-open-llm.git
api-for-open-llm配置参数
拷贝一份配置
# cd api-for-open-llm/
# cp .env.example .env
编辑参数
[root@localhost api-for-open-llm]# vim .env
PORT=8000
# model related
MODEL_NAME=qwen # 模型名
MODEL_PATH=/opt/ice/models/qwen-14b-chat # 下载好的模型文件路径
EMBEDDING_NAME=
ADAPTER_MODEL_PATH=
QUANTIZE=16
CONTEXT_LEN=
LOAD_IN_8BIT=false
LOAD_IN_4BIT=false
USING_PTUNING_V2=false
STREAM_INTERVERL=2
PROMPT_NAME=
# device related
DEVICE=
# "auto", "cuda:0", "cuda:1", ...
DEVICE_MAP=auto
GPUS=
NUM_GPUs=2
DTYPE=half
# api related
API_PREFIX=/v1
USE_STREAMER_V2=false
ENGINE=default
api-for-open-llm加载模型
api-for-open-llm启动方式有docker和本地方式,推荐使用docker
使用docker方式的话,需要先构建llm-api镜像
[root@localhost api-for-open-llm]# docker build -f docker/Dockerfile -t llm-api:pytorch .
docker启动
[root@localhost api-for-open-llm]# docker run -it -d \
--gpus all \
--ipc=host -p 8000:8000 \
--name=llm-api --ulimit memlock=-1 \
--ulimit stack=67108864 \
-v `pwd`:/workspace -v /opt/ice/models/qwen-14b-chat:/opt/ice/models/qwen-14b-chat \
llm-api:pytorch \
python api/server.py
查看docker实例启动日志,验证模型是否启动成功
[root@localhost api-for-open-llm]# docker logs -f llm-api
=============
== PyTorch ==
=============
NVIDIA Release 23.10 (build 71422337)
PyTorch Version 2.1.0a0+32f93b1
Container image Copyright (c) 2023, NVIDIA CORPORATION & AFFILIATES. All rights reserved.
Copyright (c) 2014-2023 Facebook Inc.
Copyright (c) 2011-2014 Idiap Research Institute (Ronan Collobert)
Copyright (c) 2012-2014 Deepmind Technologies (Koray Kavukcuoglu)
Copyright (c) 2011-2012 NEC Laboratories America (Koray Kavukcuoglu)
Copyright (c) 2011-2013 NYU (Clement Farabet)
Copyright (c) 2006-2010 NEC Laboratories America (Ronan Collobert, Leon Bottou, Iain Melvin, Jason Weston)
Copyright (c) 2006 Idiap Research Institute (Samy Bengio)
Copyright (c) 2001-2004 Idiap Research Institute (Ronan Collobert, Samy Bengio, Johnny Mariethoz)
Copyright (c) 2015 Google Inc.
Copyright (c) 2015 Yangqing Jia
Copyright (c) 2013-2016 The Caffe contributors
All rights reserved.
Various files include modifications (c) NVIDIA CORPORATION & AFFILIATES. All rights reserved.
This container image and its contents are governed by the NVIDIA Deep Learning Container License.
By pulling and using the container, you accept the terms and conditions of this license:
https://developer.nvidia.com/ngc/nvidia-deep-learning-container-license
2024-02-01 01:53:11.597 | DEBUG | api.config:<module>:265 - SETTINGS: {
"host": "0.0.0.0",
"port": 8000,
"api_prefix": "/v1",
"engine": "default",
"model_name": "qwen",
"model_path": "/opt/ice/models/qwen-14b-chat",
"adapter_model_path": null,
"resize_embeddings": false,
"dtype": "half",
"device": "cuda",
"device_map": "auto",
"gpus": null,
"num_gpus": 2,
"only_embedding": false,
"embedding_name": null,
"embedding_size": -1,
"embedding_device": "cuda",
"quantize": 16,
"load_in_8bit": false,
"load_in_4bit": false,
"using_ptuning_v2": false,
"pre_seq_len": 128,
"context_length": -1,
"chat_template": null,
"rope_scaling": null,
"flash_attn": false,
"trust_remote_code": false,
"tokenize_mode": "auto",
"tensor_parallel_size": 1,
"gpu_memory_utilization": 0.9,
"max_num_batched_tokens": -1,
"max_num_seqs": 256,
"quantization_method": null,
"use_streamer_v2": false,
"api_keys": null,
"activate_inference": true,
"interrupt_requests": true,
"n_gpu_layers": 0,
"main_gpu": 0,
"tensor_split": null,
"n_batch": 512,
"n_threads": 24,
"n_threads_batch": 24,
"rope_scaling_type": -1,
"rope_freq_base": 0.0,
"rope_freq_scale": 0.0,
"tgi_endpoint": null,
"tei_endpoint": null,
"max_concurrent_requests": 256,
"max_client_batch_size": 32
}
2024-02-01 01:53:22.457 | INFO | api.adapter.patcher:patch_tokenizer:119 - Add eos token: <|endoftext|>
2024-02-01 01:53:22.457 | INFO | api.adapter.patcher:patch_tokenizer:126 - Add pad token: <|endoftext|>
/root/.cache/huggingface/modules/transformers_modules/qwen-14b-chat/modeling_qwen.py:969: DeprecationWarning: The 'warn' method is deprecated, use 'warning' instead
logger.warn("Try importing flash-attention for faster inference...")
Try importing flash-attention for faster inference...
Warning: import flash_attn rotary fail, please install FlashAttention rotary to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/rotary
Warning: import flash_attn rms_norm fail, please install FlashAttention layer_norm to get higher efficiency https://github.com/Dao-AILab/flash-attention/tree/main/csrc/layer_norm
Loading checkpoint shards: 100% 15/15 [00:06<00:00, 2.41it/s]
2024-02-01 01:53:29.693 | INFO | api.models:create_generate_model:61 - Using default engine
2024-02-01 01:53:29.693 | INFO | api.core.default:_check_construct_prompt:128 - Using Qwen Model for Chat!
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
验证大模型接口
无论是用vllm启动还是非vllm启动的大模型服务,它们的api请求参数是一致的/v1/completions/
请求body参数解释
| 字段 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| model | string 必填 | 使用的模型ID。可以使用模型API列表接口查看所有可用的模型,有关模型的描述,请参阅模型概述。 | |
| prompt | string或array 可选 | <|endoftext|> | 生成完成的提示,编码为字符串、字符串数组、token数组或token数组的数组。请注意, <|endoftext|>是模型在训练期间看到的文档分隔符,因此,如果未指定提示,则模型将从新文档的开头生成。 |
| suffix | string 可选 | null | 插入文本完成后出现的后缀。 |
| max_tokens | nteger 可选 | 16 | 完成时要生成的最大token数量。提示的token计数加上max_tokens不能超过模型的上下文长度。大多数模型的上下文长度为2048个token(最新模型除外,支持4096个) |
| temperature | number 可选 | 1 | 使用什么样的采样温度,介于0和1之间。较高的值(如0.8)将使输出更加随机,而较低的值(例如0.2)将使其更加集中和确定。通常建议更改它或top_p,但不能同时更改两者。 |
| top_p | number 可选 | 1 | 一种用温度采样的替代品,称为核采样,其中模型考虑了具有top_p概率质量的token的结果。因此,0.1意味着只考虑包含前10%概率质量的token。通常建议改变它或temperature,但不能同时更改两者。 |
| n | integer 可选 | 1 | 每个提示要生成多少个完成。注意:由于此参数会生成许多完成,因此它可以快速消耗您的token配额。小心使用,并确保您对max_tokens和stop有合理的设置。 |
| stream | boolean 可选 | false | 是否流回部分进度。如果设置,token将在可用时作为仅数据服务器发送的事件发送,流将以data:[DONE]消息终止。 |
| logprobs | interger 可选 | null | 按可能性概率选择token的个数。例如,如果logprobs为5,API将返回5个最有可能的token的列表。API将始终返回采样token的logprob,因此响应中可能最多有logprobs+1元素。logprobs的最大值为5。 |
| echo | boolean 可选 | false | 除了完成之外,回显提示 |
| stop | string或array 可选 | null | 最多4个序列,API将停止生成进一步的token。返回的文本将不包含停止序列。 |
| presence_penalty | number 可选 | 0 | 取值范围:-2.0~2.0。正值根据新token到目前为止是否出现在文本中来惩罚它们,这增加了模型谈论新主题的可能性。 |
| best_of | interger 可选 | 1 | 在服务器端生成best_of个完成,并返回“最佳”(每个token的日志概率最高)。结果无法流式传输。与n一起使用时,best_of控制候选完成的数量,n指定要返回的数量–best_of必须大于n。注意:由于此参数会生成许多完成,因此它可以快速消耗token配额。小心使用并确保您对max_tokens和stop进行了合理的设置。 |
| logit_bias | map 可选 | null | 修改完成时出现指定token的可能性。接受将token(由其在GPT token生成器中的token ID指定)映射到从-100到100的相关偏差值的json对象。您可以使用此token工具(适用于GPT-2和GPT-3)将文本转换为token ID。在数学上,偏差在采样之前被添加到模型生成的逻辑中。确切的效果因模型而异,但-1和1之间的值应该会降低或增加选择的可能性;-100或100这样的值应该导致相关token的禁止或独占选择。例如,可以传递{“50256”:-100}以防止生成<|endoftext|>的token。 |
| user | string 可选 | 代表最终用户的唯一标识符,可帮助OpenAI监控和检测滥用。 |
curl发个prompt请求,查看是否正常返回
[root@localhost ~]# curl http://localhost:8000/v1/completions -H "Content-Type: application/json" -d '{"model": "/opt/qwen-14b-chat","prompt": "Hi,深圳排名前十的好玩的公园?","max_tokens": 1000,"temperature": 0, "stop": "<|endoftext|>"}'
# 输出
{
"id": "cmpl-dcee971a-fc6b-45f5-bd56-d7433553d9e5",
"choices": [
{
"finish_reason": "stop",
"index": 0,
"logprobs": null,
"text": "深圳有哪些好玩的公园呢?公园里景色优美,空气清新,是休闲放松的好去处。\n深圳公园多,而且多有特色,比如深圳湾公园、莲花山公园、笔架山公园、洪湖公园、大梅沙海滨公园等等,都是深圳市民和游客经常去的地方。这些公园各有特色,各有特色,各有各自的特色。\n如果时间充足,可以一一游玩。如果时间紧凑,可以挑选一些有代表性的公园游玩。今天就带大家游览一下深圳十大公园。\n深圳湾公园位于深圳市南山区西部,东临深圳湾,西至白石洲,北靠福田区,南接蛇口。公园包括深圳湾栈道、深圳湾运动公园、深圳湾休闲文化公园等。深圳湾公园是深圳最浪漫的公园,最适合新人拍摄婚纱照,也适合全家出游。\n莲花山公园位于深圳市中心区北端红荔路与新洲路交汇处,占地194公顷,是深圳最大的公园。公园包括山顶广场、风筝广场、观景台、莲花山音乐厅、深圳改革开放展览馆等。莲花山公园是深圳市民最喜欢的公园之一,也是深圳最著名的公园。\n笔架山公园位于深圳市中心区,北临深南大道,西接福华三路。公园包括笔架山、笔架山公墓、笔架山儿童公园、笔架山植物园等。笔架山公园是深圳最安静的公园,最适合周末休闲。\n洪湖公园位于深圳市中心区,南临深南大道,北接红荔路,东临深南大道,西接华强北路。公园包括洪湖、洪湖公园、洪湖街、洪湖街等。洪湖公园是深圳最浪漫的公园,最适合新人拍摄婚纱照,也适合全家出游。\n大梅沙海滨公园位于深圳市盐田区东部,西临大梅沙海滨,东至盐田港。公园包括大梅沙海滨、大梅沙海滨公园、大梅沙海滨步行街等。大梅沙海滨公园是深圳最受欢迎的公园,也是深圳最著名的公园。\n深圳湾公园、莲花山公园、笔架山公园、洪湖公园、大梅沙海滨公园都是深圳市民和游客经常去的地方,也是深圳最受欢迎的公园。\n深圳湾公园位于深圳市南山区西部,东临深圳湾,西至白石洲,北靠福田区,南接蛇口。公园包括深圳湾栈道、深圳湾运动公园、深圳湾休闲文化公园等。深圳湾公园是深圳最浪漫的公园,最适合新人拍摄婚纱照,也适合全家出游。\n莲花山公园位于深圳市中心区北端红荔路与新洲路交汇处,占地194公顷,是深圳最大的公园。公园包括山顶广场、风筝广场、观景台、莲花山音乐厅、深圳改革开放展览馆等。莲花山公园是深圳市民最喜欢的公园之一,也是深圳最著名的公园。\n笔架山公园位于深圳市中心区,北临深南大道,西接福华三路。公园包括笔架山、笔架山公墓、笔架山儿童公园、笔架山植物园等。笔架山公园是深圳最安静的公园,最适合周末休闲。\n洪湖公园位于深圳市中心区,南临深南大道,北接红荔路,东临深南大道,西接华强北路。公园包括洪湖、洪湖公园、洪湖街、洪湖街等。洪湖公园是深圳最浪漫的公园,最适合新人拍摄婚纱照,也适合全家出游。\n大梅沙海滨公园位于深圳市盐田区东部,西临大梅沙海滨,东至盐田港。公园包括大梅沙海滨、大梅沙海滨公园、大梅沙海滨步行街等。大梅沙海滨公园是深圳最受欢迎的公园,也是深圳最著名的公园。\n以上就是深圳十大公园,包括深圳湾公园、莲花山公园、笔架山公园、洪湖公园、大梅沙海滨公园等。深圳十大公园各有特色,各有特色,各有各自的特色。"
}
],
"created": 1706767165,
"model": "/opt/qwen-14b-chat",
"object": "text_completion",
"system_fingerprint": null,
"usage": {
"completion_tokens": 859,
"prompt_tokens": 10,
"total_tokens": 869
}
}
常见错误
问题:
CUDA out of memory. Tried to allocate 1024.00 MiB (GPU 0; 7.80 GiB total capacity; 5.21 GiB already allocated;
173.38 MiB free; 5.27 GiB reserved in total by PyTorch)
If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation.
See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
解决:
最优设置策略:将max_split_size_mb设置为小于OOM发生时的显存请求大小最小值的最大整数值, 这里请求是1024MB所以可以设置为1024MB,
PYTORCH_CUDA_ALLOC_CONF=max_split_size_mb:1024。
vLLM
vLLM是来自UC Berkeley的LMSYS在LLM推理方面的最新工作(发布Vicuna大模型的那个团队),最大亮点是采用Paged Attention技术, 结合Continuous Batching,极大地优化了realtime场景下的LLM serving的throughput与内存使用。
除了vLLM外可以加速大模型推理,还有FlashAttention;vLLM的核心是PagedAttention,FlashAttention是一种重新排序注意力计算的算法,它利用平铺、重计算等经典技术来显著提升计算速度,并将序列长度中的内存使用实现从二次到线性减少。Flash Attention的主要目的是加速和节省内存。
FlashAttention-2需要GPU支持:
FlashAttention-2 currently supports:
Ampere, Ada, or Hopper GPUs (e.g., A100, RTX 3090, RTX 4090, H100). Support for Turing GPUs (T4, RTX 2080) is coming soon, please use FlashAttention 1.x for Turing GPUs for now.
Datatype fp16 and bf16 (bf16 requires Ampere, Ada, or Hopper GPUs).
All head dimensions up to 256. Head dim > 192 backward requires A100/A800 or H100/H800.
编译vLLM镜像
正常操作系统用vllm/vllm-openai这个镜像就可以了,但是通义千问模型需要额外装包,所以重新编译下vllm-openai镜像
[root@localhost]# vim Dockerfile
# 使用vllm/vllm-openai作为基础镜像
FROM vllm/vllm-openai:v0.3.0
# 通义千问需要额外安装包
RUN pip install tiktoken \
-i https://pypi.tuna.tsinghua.edu.cn/simple
docker build编译
[root@localhost]# docker build -f Dockerfile -t vllm/vllm-openai:kylin-v10 .
vLLM加载模型
docker运行vLLM镜像
[root@localhost]# docker run -it -d \
--gpus all -v /opt/ice/models/qwen-14b-chat:/opt/qwen-14b-chat \
--name vllm-api \
-p 8000:8000 --ipc=host \
vllm/vllm-openai:kylin-v10 \
--model /opt/qwen-14b-chat \
--max-model-len 8096 \
--enforce-eager \
--trust-remote-code \
--tensor-parallel-size 2
注:vLLM方式启动带的--model这个参数,调用api接口的时候也需要传入同样的值;--tensor-parallel-size用于在多个GPU间分配工作,max-model-len指定模型上下文长度,
--served-model-name Qwen1.5-7B-Chat可以指定模型的名字,没指定的话默认就用--model用于模型名,--api-key用于指定 api_key
python源码方式启动
python3 -m vllm.entrypoints.openai.api_server \
--model /opt/qwen-14b-chat \
--served-model-name qwen \
--tensor-parallel-size 2 \
--trust-remote-code
查看显卡占用,模型分布在两张卡上,所谓的模型并行
[root@localhost vllm]# nvidia-smi
Thu Feb 1 19:32:24 2024
+---------------------------------------------------------------------------------------+
| NVIDIA-SMI 535.146.02 Driver Version: 535.146.02 CUDA Version: 12.2 |
|-----------------------------------------+----------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+======================+======================|
| 0 NVIDIA GeForce RTX 4090 Off | 00000000:81:00.0 Off | Off |
| 55% 61C P2 241W / 450W | 22026MiB / 24564MiB | 97% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
| 1 NVIDIA GeForce RTX 4090 Off | 00000000:C1:00.0 Off | Off |
| 68% 66C P2 243W / 450W | 20796MiB / 24564MiB | 90% Default |
| | | N/A |
+-----------------------------------------+----------------------+----------------------+
+---------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=======================================================================================|
| 0 N/A N/A 151961 C python3 22010MiB |
| 1 N/A N/A 154943 C ray::RayWorkerVllm.execute_method 20780MiB |
+---------------------------------------------------------------------------------------+
nvidia-smi的展示算比较简洁的,推荐用nvitop来看gpu使用情况,不仅有nvtop详细的展示,还拥有gpustat彩色界面展示
查看vllm-api容器日志,验证是否启动成功
[root@localhost vllm]# docker logs -f vllm-api
INFO 02-01 10:14:02 api_server.py:727] args: Namespace(host=None, port=8000, allow_credentials=False, allowed_origins=['*'], allowed_methods=['*'], allowed_headers=['*'], served_model_name=None, chat_template=None, response_role='assistant', ssl_keyfile=None, ssl_certfile=None, model='/opt/qwen-14b-chat', tokenizer=None, revision=None, tokenizer_revision=None, tokenizer_mode='auto', trust_remote_code=True, download_dir=None, load_format='auto', dtype='auto', max_model_len=None, worker_use_ray=False, pipeline_parallel_size=1, tensor_parallel_size=2, max_parallel_loading_workers=None, block_size=16, seed=0, swap_space=4, gpu_memory_utilization=0.9, max_num_batched_tokens=None, max_num_seqs=256, max_paddings=256, disable_log_stats=False, quantization=None, enforce_eager=True, max_context_len_to_capture=8192, engine_use_ray=False, disable_log_requests=False, max_log_len=None)
2024-02-01 10:14:07,259 INFO worker.py:1724 -- Started a local Ray instance.
INFO 02-01 10:14:08 llm_engine.py:70] Initializing an LLM engine with config: model='/opt/qwen-14b-chat', tokenizer='/opt/qwen-14b-chat', tokenizer_mode=auto, revision=None, tokenizer_revision=None, trust_remote_code=True, dtype=torch.float16, max_seq_len=2048, download_dir=None, load_format=auto, tensor_parallel_size=2, quantization=None, enforce_eager=True, seed=0)
WARNING 02-01 10:14:09 tokenizer.py:62] Using a slow tokenizer. This might cause a significant slowdown. Consider using a fast tokenizer instead.
INFO 02-01 10:14:23 llm_engine.py:275] # GPU blocks: 981, # CPU blocks: 655
WARNING 02-01 10:14:25 tokenizer.py:62] Using a slow tokenizer. This might cause a significant slowdown. Consider using a fast tokenizer instead.
WARNING 02-01 10:14:25 api_server.py:123] No chat template provided. Chat API will not work.
INFO: Started server process [1]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8000 (Press CTRL+C to quit)
vLLM集成DeepSeek-R1
vLLM已支持DeepSeek-R1这种Reasoning模型:https://docs.vllm.ai/en/latest/features/reasoning_outputs.html
使用hfd脚本下载DeepSeek R1 GGUF模型,因为unsloth/DeepSeek-R1-GGUF目录下保存的量化模型太多,所以想针对性下载
# 第一次执行hfd命令会在当前目录生成DeepSeek-R1-GGUF目录,然后中断执行编辑下.hfd/aria2c_urls.txt文件
[root@ data]# vim DeepSeek-R1-GGUF/.hfd/aria2c_urls.txt
# 只下载DeepSeek-R1-UD-IQ1_S模型和DeepSeek-R1-UD-Q2_K_XL模型
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
gid=784e14abbd6082d5
dir=DeepSeek-R1-UD-IQ1_S
out=DeepSeek-R1-UD-IQ1_S-00001-of-00003.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
gid=19504c139b5afb0e
dir=DeepSeek-R1-UD-IQ1_S
out=DeepSeek-R1-UD-IQ1_S-00002-of-00003.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
gid=c8a451b051127401
dir=DeepSeek-R1-UD-IQ1_S
out=DeepSeek-R1-UD-IQ1_S-00003-of-00003.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf
gid=cd153841dc8433c7
dir=DeepSeek-R1-UD-Q2_K_XL
out=DeepSeek-R1-UD-Q2_K_XL-00001-of-00005.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00002-of-00005.gguf
gid=5b160949334ca0c0
dir=DeepSeek-R1-UD-Q2_K_XL
out=DeepSeek-R1-UD-Q2_K_XL-00002-of-00005.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00003-of-00005.gguf
gid=01490eda5b37c674
dir=DeepSeek-R1-UD-Q2_K_XL
out=DeepSeek-R1-UD-Q2_K_XL-00003-of-00005.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00004-of-00005.gguf
gid=5b3afb5934cc7261
dir=DeepSeek-R1-UD-Q2_K_XL
out=DeepSeek-R1-UD-Q2_K_XL-00004-of-00005.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/DeepSeek-R1-UD-Q2_K_XL/DeepSeek-R1-UD-Q2_K_XL-00005-of-00005.gguf
gid=a4575d0aa99101fc
dir=DeepSeek-R1-UD-Q2_K_XL
out=DeepSeek-R1-UD-Q2_K_XL-00005-of-00005.gguf
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/README.md
gid=453869672e068e89
dir=
out=README.md
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
https://hf-mirror.com/unsloth/DeepSeek-R1-GGUF/resolve/main/config.json
gid=19b0e1670fe977ab
dir=
out=config.json
split=4
file-allocation=none
continue=true
max-connection-per-server=4
min-split-size=1048576
# 使用hfd脚本下载DeepSeek R1 GGUF模型
HF_ENDPOINT=https://hf-mirror.com hfd.sh unsloth/DeepSeek-R1-GGUF --tool aria2c -x 4 &
或者使用modelscope下载DeepSeek-R1-Q4_K_M GGUF模型
modelscope download --model unsloth/DeepSeek-R1-GGUF \
--include "DeepSeek-R1-Q4_K_M/*.gguf" \
--local_dir ./
vLLM启动DeepSeek-R1模型
docker run -it -d --gpus all \
--restart always \
-v /root/DeepSeek-R1-Distill-Qwen-32B:/root/DeepSeek-R1-Distill-Qwen-32B \
--name vllm-server \
-p 8000:8000 --ipc=host vllm/vllm-openai:v0.7.2 \
--model /root/DeepSeek-R1-Distill-Qwen-32B \
--max-model-len 32768 \
--served-model-name deepseek-r1 \
--enable-reasoning --reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
python脚本验证思考过程和内容流式输出
from openai import OpenAI
# Modify OpenAI's API key and API base to use vLLM's API server.
openai_api_key = "EMPTY"
openai_api_base = "http://xxx:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
models = client.models.list()
model = models.data[0].id
# Round 1
messages = [{"role": "user", "content": "帮我写一个冒泡排序。你是一位编程的资深专家,擅长编写各种程序。要求用Java来编写功能。"}]
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True # 启用流式输出
)
# 通过迭代处理流式响应
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
# 如果需要获取 reasoning_content
if hasattr(chunk.choices[0].delta, 'reasoning_content') and chunk.choices[0].delta.reasoning_content:
print(chunk.choices[0].delta.reasoning_content, end="", flush=True)
SGLang
SGLang(Structured Generation Language)是伯克利开发的一个用于LLM应用开发的特定领域语言(DSL),采用基于RadixAttention的高性能推理引擎。通过在多轮对话中智能复用KV缓存,大幅提升了复杂LLM程序的执行效率。此外,它还集成了连续批处理(Continuous Batching)和张量并行(Tensor Parallelism)等主流推理优化技术.
python源码方式启动
python -m sglang.launch_server \
--model-path /root/Qwen2.5-0.5B/ \
--port 8000 \
--served-model-name qwen \
--trust-remote-code
CSGHub
https://github.com/OpenCSGs/csghub类似私有化版本Huggingface Hub,部署使用过程中有坑,比如git-lfs无法push
通过GIT_TRACE=1 GIT_CURL_VERBOSE=1参数,可以查看git push的详细日志(包括git lfs配置)
GIT_TRACE=1 GIT_CURL_VERBOSE=1 git push
如果只是想用简单的git-server功能,推荐gogs轻巧方便,一键部署
大模型RDMA网络
大模型(如GPT、BERT等)的训练和推理需要极高的计算和通信效率,而RDMA(Remote Direct Memory Access)网络技术因其低延迟、高吞吐量的特性,成为支撑大规模分布式训练的核心技术之一。
RDMA介绍
RDMA是一种网络通信协议,允许计算机直接从一台计算机的内存读取或写入数据,而无需经过操作系统内核和CPU的介入。这种技术通过绕过传统TCP/IP协议栈的瓶颈,显著提升了网络传输效率,尤其适用于大模型训练中频繁的参数同步和梯度交换场景。
RDMA可通过以下协议实现,需硬件和网络支持:
-
InfiniBand:
- 专为RDMA设计的网络架构,提供超低延迟和高带宽。
- 需要专用的InfiniBand网卡(如NVIDIA ConnectX系列)和交换机。
- 最理想情况:一个GPU配一个InfiniBand网卡
-
RoCE(RDMA over Converged Ethernet):
- 将InfiniBand的RDMA技术移植到以太网,分RoCEv1(基于链路层)和RoCEv2(支持IP路由)。
- 需要支持RDMA的以太网卡(如Mellanox网卡)和无损网络配置(PFC、ECN)。
-
iWARP:
- 基于TCP的RDMA实现,兼容标准以太网,但性能略低于InfiniBand和RoCE。
+----------------------+ +-------------------------+
| IB开头部分,由IBTA定义 | |非IB开头部分,由IEEE/IETF定义|
+----------------------+ +-------------------------+
+-----------------------------------------------------------------------+
| RDMA application/ULP |
+-----------------------------------------------------------------------+
| RDMA API |
+-----------------------------------------------------------------------+
| RDMA软件协议栈 |
+-----------------------------------------------------------------------+
+-----------------+ +-----------------+ +-----------------+ +-----------------+
| IB transport | | IB transport | | IB transport | | iWARP* |
| protocol | | protocol | | protocol | | protocol |
+-----------------+ +-----------------+ +-----------------+ +-----------------+
| IB network layer| | IB network layer| | UDP | | TCP |
+-----------------+ +-----------------+ +-----------------+ +-----------------+
| | | | | IP | | IP |
| IB link layer | |Ethernet link | |Ethernet link | |Ethernet link |
| | |layer | |layer | |layer |
+-----------------+ +-----------------+ +-----------------+ +-----------------+
RoCE v1 RoCE v2 RoCE v2 iWARP
+-----------------+ +-----------------+ +-----------------+ +-----------------+
| InfiniBand | | Ethernet/IP | | Ethernet/IP | | Ethernet/IP |
| management | | management | | management | | management |
+-----------------+ +-----------------+ +-----------------+ +-----------------+
涉及到大模型的话,还需要专门配置网络拓扑。InfiniBand提供集中式管理,支持多种网络拓扑,包括Fat Tree、Hypercubes、多维Torus和Dragonfly+等。路由算法可为适配特定应用通信模式的网络拓扑实现性能优化。在介绍Infiniband网络拓扑前,先来看下数据中心常见的网络拓扑架构:
-
Fat-Tree(胖树)网络拓扑,类似真实的树,越到树根,枝干越粗。原理:利用大量低性能交换机组合成大规模的无阻塞网络
 胖树拓扑缺点:采用STP协议,实际流量只有一条,其它上行链路当做备份,浪费带宽资源;不适合东西流量,服务器之间通信,需要经过接入交换机、汇聚交换机,甚至核心交换机
胖树拓扑缺点:采用STP协议,实际流量只有一条,其它上行链路当做备份,浪费带宽资源;不适合东西流量,服务器之间通信,需要经过接入交换机、汇聚交换机,甚至核心交换机 -
Spine-Leaf(叶脊)网络拓扑,相比胖树三层架构,更扁平化,二层架构
 脊交换机相当于核心交换机,叶交换机和脊交换机之间通过ECMP动态选择多条路径。带宽利用率高,叶交换机上行链路以负载均衡方式工作。
脊交换机相当于核心交换机,叶交换机和脊交换机之间通过ECMP动态选择多条路径。带宽利用率高,叶交换机上行链路以负载均衡方式工作。
介绍传统数据中心的网络拓扑,接下来看下Infiniband的网络拓扑,参考链接:https://lulaoshi.info/deep-learning/system/rdma-network.html
 上图是一个低配版本的胖树和导轨优化拓扑:共配置了2台交换机,QM8700是HDR交换机,两个HDR交换机通过4根HDR线缆相连以保证互联速率;每台DGX GPU节点共9张IB卡(图中的HCA),其中1张给存储(Storage Target),剩下8张给大模型训练。这8张IB卡中的HCA1/3/5/7连到第一个交换机,HCA2/4/6/8连到第二个交换机。
上图是一个低配版本的胖树和导轨优化拓扑:共配置了2台交换机,QM8700是HDR交换机,两个HDR交换机通过4根HDR线缆相连以保证互联速率;每台DGX GPU节点共9张IB卡(图中的HCA),其中1张给存储(Storage Target),剩下8张给大模型训练。这8张IB卡中的HCA1/3/5/7连到第一个交换机,HCA2/4/6/8连到第二个交换机。
 上图是一张无阻塞全速导轨优化:每台DGX GPU节点共配置8张IB卡,每张卡上连1台交换机,这些交换机被称为叶子(Leaf)交换机,共需8个叶子交换机;确切地说HCA1连第一个叶子交换机,HCA2连第二个叶子交换机,以此类推。叶子交换机之间的通信通过骨干(Spine)交换机来保障速率。目的就是为了保持高速通信,任何一张IB卡都可以和整个网络中其他IB卡高速通信,也就是说,任何一个GPU都可以以极快地速度与其他GPU高速通信。
上图是一张无阻塞全速导轨优化:每台DGX GPU节点共配置8张IB卡,每张卡上连1台交换机,这些交换机被称为叶子(Leaf)交换机,共需8个叶子交换机;确切地说HCA1连第一个叶子交换机,HCA2连第二个叶子交换机,以此类推。叶子交换机之间的通信通过骨干(Spine)交换机来保障速率。目的就是为了保持高速通信,任何一张IB卡都可以和整个网络中其他IB卡高速通信,也就是说,任何一个GPU都可以以极快地速度与其他GPU高速通信。
NVIDIA InfiniBand网络技术栈中还有一个优化网络的特性:SHARP(Scalable Hierarchical Aggregation and Reduction Protocol),核心的功能是:把原本需经CPU收发的网络包,转移至 InfiniBand交换机处理,以此降低计算节点负载。
LLM大模型应用
QAnything知识库
QAnything版本:d5c59260a1af74f01a9b378b567435ab0caa40df
Linux环境离线安装
docker、docker-compose预装好
# 先在联网机器上下载docker镜像
docker pull quay.io/coreos/etcd:v3.5.5
docker pull minio/minio:RELEASE.2023-03-20T20-16-18Z
docker pull milvusdb/milvus:v2.3.4
docker pull mysql:latest
docker pull freeren/qanything:v1.2.1
# 打包镜像
docker save quay.io/coreos/etcd:v3.5.5 minio/minio:RELEASE.2023-03-20T20-16-18Z milvusdb/milvus:v2.3.4 mysql:latest freeren/qanything:v1.2.1 -o qanything_offline.tar
# 下载QAnything代码
wget https://github.com/netease-youdao/QAnything/archive/refs/heads/master.zip
# 把镜像qanything_offline.tar和代码QAnything-master.zip拷贝到断网机器上
cp master.zip qanything_offline.tar /path/to/your/offline/machine
# 在断网机器上加载镜像
docker load -i qanything_offline.tar
# 解压代码,运行
unzip master.zip
cd QAnything-master
bash run.sh
脚本运行过程中,会产生交互让你输入remote远程服务器安装还是local本地化安装
Langchain-Chatchat知识库(v0.3)
Github链接:https://github.com/chatchat-space/Langchain-Chatchat
搭建源码调试环境
- 安装python虚拟环境(3.8-3.11,推荐3.11)
conda create --name langchain-chatchat python=3.11
conda activate langchain-chatchat
- 克隆代码,安装依赖
# 拉取仓库
(langchain-chatchat)# git clone https://github.com/chatchat-space/Langchain-Chatchat.git
# 进入目录
(langchain-chatchat)# cd Langchain-Chatchat
(langchain-chatchat)# pip install langchain-chatchat -U # 0.3.0版本起,Langchain-Chatchat提供以Python库形式的安装方式
(langchain-chatchat)# pip install "langchain-chatchat[xinference]" -U # 接入部署框架xinference
- 设置接入模型参数
(langchain-chatchat)# chatchat-config model --set_model_platforms "[{
\"platform_name\": \"xinference\",
\"platform_type\": \"xinference\",
\"api_base_url\": \"http://<xinference_ip>:9997/v1\",
\"api_key\": \"EMPT\",
\"api_concurrencies\": 5,
\"llm_models\": [
\"qwen1.5-chat\"
],
\"embed_models\": [
\"bge-large-zh-v1.5\"
],
\"image_models\": [],
\"reranking_models\": [],
\"speech2text_models\": [],
\"tts_models\": []
}]"
(langchain-chatchat)# chatchat-config model --default_llm_model qwen1.5-chat
设置的参数作用于这个文件~/.chatchat/workspace/workspace_config.json
- 编辑server配置文件,DEFAULT_BIND_HOST设置为0.0.0.0
(langchain-chatchat)# chatchat-config server --default_bind_host 0.0.0.0
# 查看server配置是否监听在0.0.0.0上
(langchain-chatchat)# chatchat-config server --show
{
"HTTPX_DEFAULT_TIMEOUT": 300.0,
"OPEN_CROSS_DOMAIN": true,
"DEFAULT_BIND_HOST": "0.0.0.0",
"WEBUI_SERVER_PORT": 8501,
"API_SERVER_PORT": 7861,
"WEBUI_SERVER": {
"host": "0.0.0.0",
"port": 8501
},
"API_SERVER": {
"host": "0.0.0.0",
"port": 7861
},
"class_name": "ConfigServer"
}
- 初始化数据库
(langchain-chatchat)# cd libs/chatchat-server/chatchat
(langchain-chatchat)# python init_database.py --recreate-vs
- 启动服务
(langchain-chatchat)# python startup.py -a
# 启动远程debug监听模式
(langchain-chatchat)# python3 -m debugpy --listen 0.0.0.0:5678 --wait-for-client
源码分析(结合AI编程助手辅助)
启动函数
# chatchat-space/Langchain-Chatchat/startup.py
def main():
"""
程序的主入口点。
本函数初始化运行环境,包括调整当前工作目录、支持多进程、创建数据库表和启动异步事件循环。
它为运行聊天服务器做了必要的准备。
"""
# 获取并记录当前工作目录,用于后续将该目录添加到系统路径中
# 添加这行代码
cwd = os.getcwd()
# 将当前工作目录添加到系统路径中,以便能够找到本地模块
sys.path.append(cwd)
# 对于Windows平台,支持将当前程序打包为可执行文件
multiprocessing.freeze_support()
# 输出当前工作目录,用于调试
print("cwd:" + cwd)
# 导入模块并创建数据库表,用于存储知识库数据
from chatchat.server.knowledge_base.migrate import create_tables
create_tables()
# 根据Python版本选择合适的异步事件循环方式
if sys.version_info < (3, 10):
# 在Python 3.10及以下版本,直接获取或创建一个新的事件循环
loop = asyncio.get_event_loop()
else:
# 在Python 3.10及以上版本,尝试获取当前正在运行的事件循环
try:
loop = asyncio.get_running_loop()
except RuntimeError:
# 如果当前没有运行的事件循环,则创建一个新的
loop = asyncio.new_event_loop()
# 设置当前线程的事件循环
asyncio.set_event_loop(loop)
# 运行主服务器的异步任务
loop.run_until_complete(start_main_server())
主程序
# 异步启动主服务器函数
async def start_main_server():
# 导入信号处理和时间模块
import signal
import time
# 导入配置和日志工具
from chatchat.utils import (
get_config_dict,
get_log_file,
get_timestamp_ms,
)
from chatchat.configs import LOG_PATH
# 设置日志配置
logging_conf = get_config_dict(
"INFO",
get_log_file(
log_path=LOG_PATH, sub_dir=f"start_main_server_{get_timestamp_ms()}"
),
# 设置日志文件备份数量上限
1024 * 1024 * 1024 * 3,
# 设置最大日志文件大小
1024 * 1024 * 1024 * 3,
)
logging.config.dictConfig(logging_conf) # type: ignore
# 定义信号处理函数
def handler(signalname):
"""
Python 3.9 has `signal.strsignal(signalnum)` so this closure would not be needed.
Also, 3.8 includes `signal.valid_signals()` that can be used to create a mapping for the same purpose.
"""
def f(signal_received, frame):
raise KeyboardInterrupt(f"{signalname} received")
return f
# 注册信号处理程序,用于优雅地关闭进程
# This will be inherited by the child process if it is forked (not spawned)
signal.signal(signal.SIGINT, handler("SIGINT"))
signal.signal(signal.SIGTERM, handler("SIGTERM"))
# 设置多进程启动方法
mp.set_start_method("spawn")
# 初始化多进程管理器
manager = mp.Manager()
run_mode = None
# 解析命令行参数
args, parser = parse_args()
# 根据命令行参数配置服务启动选项
if args.all_webui:
args.api = True
args.api_worker = True
args.webui = True
elif args.all_api:
args.api = True
args.api_worker = True
args.webui = False
elif args.api:
args.api = True
args.api_worker = False
args.webui = False
if args.lite:
args.api = True
args.api_worker = False
args.webui = True
# 输出服务器配置信息
dump_server_info(args=args)
# 如果有命令行参数,输出启动日志
if len(sys.argv) > 1:
logger.info(f"正在启动服务:")
logger.info(f"如需查看 llm_api 日志,请前往 {LOG_PATH}")
# 初始化进程字典
processes = {}
# 定义计数器函数,用于统计启动的进程数量
def process_count():
return len(processes)
# 初始化API服务器启动事件
api_started = manager.Event()
# 根据参数决定是否启动API服务器
if args.api:
# 创建一个进行,目标是运行API服务
process = Process(
target=run_api_server,
name=f"API Server",
kwargs=dict(
started_event=api_started,
run_mode=run_mode,
),
daemon=False,
)
processes["api"] = process
# 初始化WebUI服务器启动事件
webui_started = manager.Event()
# 根据参数决定是否启动WebUI服务器
if args.webui:
# 创建一个进行,目标是运行WebUI服务
process = Process(
target=run_webui,
name=f"WEBUI Server",
kwargs=dict(
started_event=webui_started,
run_mode=run_mode,
),
daemon=True,
)
processes["webui"] = process
# 如果没有要启动的进程,打印帮助信息
if process_count() == 0:
parser.print_help()
else:
try:
# 启动API服务器并等待其启动完成
if p := processes.get("api"):
p.start()
p.name = f"{p.name} ({p.pid})"
# 等待api.py启动完成
api_started.wait()
# 启动WebUI服务器并等待其启动完成
if p := processes.get("webui"):
p.start()
p.name = f"{p.name} ({p.pid})"
# 等待webui.py启动完成
webui_started.wait()
# 输出启动后的服务器信息
dump_server_info(after_start=True, args=args)
# 监控进程运行,等待进程结束
# 等待所有进程退出
while processes:
# 遍历processes字典的值
for p in processes.values():
# 调用join(2)方法等待每个进程运行2秒钟
p.join(2)
# 如果进程不再存活,则通过pop方法从字典中移除该进程
if not p.is_alive():
processes.pop(p.name)
except Exception as e:
logger.error(e)
logger.warning("Caught KeyboardInterrupt! Setting stop event...")
finally:
# 关闭所有进程
for p in processes.values():
logger.warning("Sending SIGKILL to %s", p)
# Queues and other inter-process communication primitives can break when
# process is killed, but we don't care here
# 如果进程对象是一个字典,遍历其值并杀死所有包含的进程
if isinstance(p, dict):
for process in p.values():
process.kill()
# 如果进程对象不是一个字典,直接杀死该进程
else:
p.kill()
# 再次遍历所有进程对象,检查并记录它们的最终状态
for p in processes.values():
logger.info("Process status: %s", p)
核心API服务
def run_api_server(
started_event: mp.Event = None, run_mode: str = None
):
"""
启动API服务器。
使用Uvicorn运行ASGI应用程序。此函数配置并启动API服务器,它负责处理来自客户端的请求。
参数:
- started_event: 一个multiprocessing.Event对象,用于在API服务器启动后通知其他进程。
- run_mode: API服务器的运行模式,用于配置应用程序的行为。
"""
# 导入必要的模块和包
import uvicorn
from chatchat.utils import (
get_config_dict,
get_log_file,
get_timestamp_ms,
)
# 从配置文件中获取API服务器的配置信息
from chatchat.configs import API_SERVER, LOG_PATH, MODEL_PLATFORMS
# 导入创建应用程序的函数
from chatchat.server.api_server.server_app import create_app
# 导入配置HTTPX的函数
from chatchat.server.utils import set_httpx_config
# 初始化日志记录器
logger.info(f"Api MODEL_PLATFORMS: {MODEL_PLATFORMS}")
# 配置HTTPX客户端的设置,HTTPX是高性能的http客户端库
set_httpx_config()
# 根据运行模式创建应用程序实例
app = create_app(run_mode=run_mode)
# 设置应用程序事件,如服务器启动事件
_set_app_event(app, started_event)
# 从配置中获取API服务器的主机和端口
host = API_SERVER["host"]
port = API_SERVER["port"]
# 配置日志系统,包括日志等级、文件路径、最大文件大小和备份数量
logging_conf = get_config_dict(
"INFO",
get_log_file(log_path=LOG_PATH, sub_dir=f"run_api_server_{get_timestamp_ms()}"),
1024 * 1024 * 1024 * 3,
1024 * 1024 * 1024 * 3,
)
# 应用日志配置
logging.config.dictConfig(logging_conf) # type: ignore
# 启动Uvicorn服务器,运行API应用程序
uvicorn.run(app, host=host, port=port)
根据运行模式创建应用程序实例
def create_app(run_mode: str = None):
"""
创建并配置FastAPI应用程序实例。
:param run_mode: 应用程序的运行模式,用于配置不同的环境设置,默认为None。
:return: 配置好的FastAPI应用程序实例。
"""
# 初始化FastAPI应用程序,并设置标题和版本
app = FastAPI(title="Langchain-Chatchat API Server", version=VERSION)
# 离线模式配置,使应用在离线环境下仍能访问API文档
MakeFastAPIOffline(app)
# Add CORS middleware to allow all origins
# 在config.py中设置OPEN_DOMAIN=True,允许跨域
# set OPEN_DOMAIN=True in config.py to allow cross-domain
if OPEN_CROSS_DOMAIN:
app.add_middleware(
CORSMiddleware,
allow_origins=["*"],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 配置应用程序的根路由,重定向到文档页面
@app.get("/", summary="swagger 文档", include_in_schema=False)
async def document():
return RedirectResponse(url="/docs")
# 注册各个功能模块的路由
app.include_router(chat_router)
app.include_router(kb_router)
app.include_router(tool_router)
app.include_router(openai_router)
app.include_router(server_router)
# 注册额外的接口路由
app.post(
"/other/completion",
tags=["Other"],
summary="要求llm模型补全(通过LLMChain)",
)(completion)
# 配置静态文件路由,提供媒体文件访问
app.mount("/media", StaticFiles(directory=MEDIA_PATH), name="media")
# 配置项目相关图片的静态文件路由
img_dir = os.path.join(CHATCHAT_ROOT, "img")
app.mount("/img", StaticFiles(directory=img_dir), name="img")
return app
数据库连接会话
from contextlib import contextmanager
from functools import wraps
from sqlalchemy.orm import Session
from chatchat.server.db.base import SessionLocal
# contextmanager可以简化yield语句来标记__enter__()和__exit__()之间的代码段
@contextmanager
def session_scope() -> Session:
"""
提供一个事务性的Session上下文管理器。
在with语句中使用时,会自动处理Session的开启、提交、回滚和关闭。
这确保了数据库操作被正确地包含在事务中,提高了数据的一致性和完整性。
"""
session = SessionLocal()
try:
yield session
session.commit()
except:
session.rollback()
raise
finally:
session.close()
def with_session(f):
"""
函数装饰器,用于自动管理数据库会话的生命周期。
被装饰的函数将在一个有效的数据库会话上下文中执行。
如果函数执行过程中发生异常,会回滚会话;否则,会提交会话。
这简化了数据库操作的事务管理。
"""
@wraps(f)
def wrapper(*args, **kwargs):
with session_scope() as session:
try:
result = f(session, *args, **kwargs)
session.commit()
return result
except:
session.rollback()
raise
return wrapper
def get_db() -> SessionLocal:
"""
提供一个数据库会话的生成器。
在with语句中使用时,可以确保会话在使用后正确关闭。
这是一种资源管理的常见模式,用于避免资源泄露。
"""
db = SessionLocal()
try:
yield db
finally:
db.close()
def get_db0() -> SessionLocal:
"""
获取一个数据库会话实例。
与get_db()不同,这个函数直接返回一个会话实例,而不是一个生成器。
使用者需要显式地管理会话的生命周期,确保在不需要时关闭会话。
"""
db = SessionLocal()
return db
chat聊天功能模块
# 初始化聊天路由,用于处理与聊天相关的API请求
# 使用前缀"/chat"和标签"ChatChat 对话"来标识这个路由的目的和功能
chat_router = APIRouter(prefix="/chat", tags=["ChatChat 对话"])
# 定义一个API端点,用于发起与llm模型的对话
# 请求方法为POST,路径为"/chat"
# 通过LLMChain进行模型对话
# 请求摘要说明了这个端点的主要功能
chat_router.post(
"/chat",
summary="与llm模型对话(通过LLMChain)",
)(chat)
# 定义一个API端点,用于提交对llm模型对话的反馈
# 请求方法为POST,路径为"/feedback"
# 请求摘要说明了这个端点的主要功能
chat_router.post(
"/feedback",
summary="返回llm模型对话评分",
)(chat_feedback)
# 定义一个API端点,用于处理基于文件的对话请求
# 请求方法为POST,路径为"/file_chat"
# 请求摘要说明了这个端点的主要功能
chat_router.post("/file_chat", summary="文件对话")(file_chat)
# 异步函数,处理聊天完成请求
# 参数 request: 请求对象
# 参数 body: 包含聊天输入信息的OpenAIChatInput对象
# 返回一个字典,与OpenAI的聊天完成响应兼容
@chat_router.post("/chat/completions", summary="兼容 openai 的统一 chat 接口")
async def chat_completions(
request: Request,
body: OpenAIChatInput,
) -> Dict:
"""
请求参数与 openai.chat.completions.create 一致,可以通过 extra_body 传入额外参数
tools 和 tool_choice 可以直接传工具名称,会根据项目里包含的 tools 进行转换
通过不同的参数组合调用不同的 chat 功能:
- tool_choice
- extra_body 中包含 tool_input: 直接调用 tool_choice(tool_input)
- extra_body 中不包含 tool_input: 通过 agent 调用 tool_choice
- tools: agent 对话
- 其它:LLM 对话
以后还要考虑其它的组合(如文件对话)
返回与 openai 兼容的 Dict
"""
# 创建OpenAI客户端,来源支持xinference、ollama、fastchat、localAI等,用于后续的API调用
client = get_OpenAIClient(model_name=body.model, is_async=True)
# 复制model_extra字段到extra字典,并从body中删除这些属性
extra = {**body.model_extra} or {}
for key in list(extra):
delattr(body, key)
# 设置全局模型名称
global global_model_name
global_model_name = body.model
# 处理body中的tool_choice和tools字段,将工具名称转换为工具配置
if isinstance(body.tool_choice, str):
if t := get_tool(body.tool_choice):
body.tool_choice = {"function": {"name": t.name}, "type": "function"}
if isinstance(body.tools, list):
for i in range(len(body.tools)):
if isinstance(body.tools[i], str):
if t := get_tool(body.tools[i]):
body.tools[i] = {
"type": "function",
"function": {
"name": t.name,
"description": t.description,
"parameters": t.args,
},
}
# 获取对话ID,用于后续的消息记录
conversation_id = extra.get("conversation_id")
# 如果指定了tool_choice,调用相应的工具处理函数
# chat based on result from one choiced tool
if body.tool_choice:
tool = get_tool(body.tool_choice["function"]["name"])
# 如果没有指定其他工具,添加当前工具到tools列表
if not body.tools:
body.tools = [
{
"type": "function",
"function": {
"name": tool.name,
"description": tool.description,
"parameters": tool.args,
},
}
]
# 如果提供了tool_input,记录消息并调用工具处理函数
if tool_input := extra.get("tool_input"):
message_id = (
add_message_to_db(
chat_type="tool_call",
query=body.messages[-1]["content"],
conversation_id=conversation_id,
)
if conversation_id
else None
)
tool_result = await tool.ainvoke(tool_input)
# 使用模板生成最终的回复内容
prompt_template = PromptTemplate.from_template(
get_prompt_template("llm_model", "rag"), template_format="jinja2"
)
body.messages[-1]["content"] = prompt_template.format(
context=tool_result, question=body.messages[-1]["content"]
)
# 删除tools和tool_choice字段,以避免不必要的处理
del body.tools
del body.tool_choice
# 构建响应头信息
extra_json = {
"message_id": message_id,
"status": None,
}
header = [
{
**extra_json,
"content": f"{tool_result}",
"tool_output": tool_result.data,
"is_ref": True,
}
]
# 发起OpenAI聊天完成请求
return await openai_request(
client.chat.completions.create,
body,
extra_json=extra_json,
header=header,
)
# 如果指定了tools列表,调用agent处理函数
# agent chat with tool calls
if body.tools:
message_id = (
add_message_to_db(
chat_type="agent_chat",
query=body.messages[-1]["content"],
conversation_id=conversation_id,
)
if conversation_id
else None
)
# 配置聊天模型和工具配置
chat_model_config = {} # TODO: 前端支持配置模型
tool_names = [x["function"]["name"] for x in body.tools]
tool_config = {name: get_tool_config(name) for name in tool_names}
# 调用agent处理函数,获取最终回复
result = await chat(
query=body.messages[-1]["content"],
metadata=extra.get("metadata", {}),
conversation_id=extra.get("conversation_id", ""),
message_id=message_id,
history_len=-1,
history=body.messages[:-1],
stream=body.stream,
chat_model_config=extra.get("chat_model_config", chat_model_config),
tool_config=extra.get("tool_config", tool_config),
)
return result
else: # 如果没有指定工具,直接使用LLM模型处理
# LLM chat directly
message_id = (
add_message_to_db(
chat_type="llm_chat",
query=body.messages[-1]["content"],
conversation_id=conversation_id,
)
if conversation_id
else None
)
# 构建响应头信息
extra_json = {
"message_id": message_id,
"status": None,
}
# 发起OpenAI聊天完成请求
return await openai_request(
client.chat.completions.create, body, extra_json=extra_json
)
kb知识库功能模块
# 初始化知识库路由,用于管理知识库的相关API
kb_router = APIRouter(prefix="/knowledge_base", tags=["Knowledge Base Management"])
# 获取知识库列表的API
kb_router.get(
"/list_knowledge_bases", response_model=ListResponse, summary="获取知识库列表"
)(list_kbs)
# 创建知识库的API
kb_router.post(
"/create_knowledge_base", response_model=BaseResponse, summary="创建知识库"
)(create_kb)
# 删除知识库的API
kb_router.post(
"/delete_knowledge_base", response_model=BaseResponse, summary="删除知识库"
)(delete_kb)
# 获取知识库内文件列表的API
kb_router.get(
"/list_files", response_model=ListResponse, summary="获取知识库内的文件列表"
)(list_files)
# 搜索知识库的API
kb_router.post("/search_docs", response_model=List[dict], summary="搜索知识库")(
search_docs
)
# 上传文件到知识库并进行向量化的API
kb_router.post(
"/upload_docs",
response_model=BaseResponse,
summary="上传文件到知识库,并/或进行向量化",
)(upload_docs)
# 删除知识库内指定文件的API
kb_router.post(
"/delete_docs", response_model=BaseResponse, summary="删除知识库内指定文件"
)(delete_docs)
# 更新知识库介绍的API
kb_router.post("/update_info", response_model=BaseResponse, summary="更新知识库介绍")(
update_info
)
# 更新现有文件到知识库的API
kb_router.post(
"/update_docs", response_model=BaseResponse, summary="更新现有文件到知识库"
)(update_docs)
# 下载知识库文件的API
kb_router.get("/download_doc", summary="下载对应的知识文件")(download_doc)
# 重建向量库的API
kb_router.post(
"/recreate_vector_store", summary="根据content中文档重建向量库,流式输出处理进度。"
)(recreate_vector_store)
# 上传临时文件的API,用于文件对话
kb_router.post("/upload_temp_docs", summary="上传文件到临时目录,用于文件对话。")(
upload_temp_docs
)
# 初始化摘要路由,用于管理知识库摘要的相关API
summary_router = APIRouter(prefix="/kb_summary_api")
# 根据文件名称生成摘要的API
summary_router.post(
"/summary_file_to_vector_store", summary="单个知识库根据文件名称摘要"
)(summary_file_to_vector_store)
# 根据doc_ids生成摘要的API
summary_router.post(
"/summary_doc_ids_to_vector_store",
summary="单个知识库根据doc_ids摘要",
response_model=BaseResponse,
)(summary_doc_ids_to_vector_store)
# 重建单个知识库文件摘要的API
summary_router.post("/recreate_summary_vector_store", summary="重建单个知识库文件摘要")(
recreate_summary_vector_store
)
# 将摘要路由包含进知识库路由中
kb_router.include_router(summary_router)
openai功能模块
这里定义了兼容OpenAI API的接口,封装调用了OpenAI SDK
tool工具功能模块
# 初始化工具路由,用于集中管理工具相关的API
tool_router = APIRouter(prefix="/tools", tags=["Toolkits"])
# 描述:列出所有可用的工具及其配置信息
# 请求方法:GET
# 请求路径:/tools
# 响应模型:BaseResponse
# 返回数据格式:包含所有工具信息的字典,每个工具以其名称为键,值为包含工具标题、描述、参数、配置等信息的字典
@tool_router.get("", response_model=BaseResponse)
async def list_tools():
"""
获取所有工具的信息列表。
返回:
- data: 包含所有工具详细信息的字典。
"""
tools = get_tool()
data = {
t.name: {
"name": t.name,
"title": t.title,
"description": t.description,
"args": t.args,
"config": get_tool_config(t.name),
}
for t in tools.values()
}
return {"data": data}
# 描述:调用指定的工具进行处理
# 请求方法:POST
# 请求路径:/tools/call
# 请求参数:name - 工具名称, tool_input - 工具输入参数
# 响应模型:BaseResponse
# 返回数据格式:调用成功返回工具处理结果,调用失败返回错误信息
@tool_router.post("/call", response_model=BaseResponse)
async def call_tool(
name: str = Body(examples=["calculate"]),
tool_input: dict = Body({}, examples=[{"text": "3+5/2"}]),
):
"""
调用指定的工具进行处理。
参数:
- name: 工具的名称。
- tool_input: 提供给工具的输入参数。
返回:
- data: 工具处理的结果。
"""
# 尝试获取指定名称的工具
if tool := get_tool(name):
try:
# 异步调用工具的处理方法
result = await tool.ainvoke(tool_input)
return {"data": result}
except Exception:
# 记录调用工具失败的错误日志
msg = f"failed to call tool '{name}'"
logger.error(msg, exc_info=True)
# 返回调用失败的响应
return {"code": 500, "msg": msg}
else:
# 返回找不到指定工具的响应
return {"code": 500, "msg": f"no tool named '{name}'"}
server功能模块
from typing import Literal
from fastapi import APIRouter, Body
from chatchat.server.utils import get_prompt_template, get_server_configs
# 初始化一个APIRouter,用于处理与服务器状态相关的路由
server_router = APIRouter(prefix="/server", tags=["Server State"])
# 定义路由规则,用于获取服务器的原始配置信息
# 服务器相关接口
server_router.post(
"/configs",
summary="获取服务器原始配置信息",
)(get_server_configs)
# 定义路由规则,用于根据类型和名称获取服务器的prompt模板
@server_router.post("/get_prompt_template", summary="获取服务区配置的prompt模板")
def get_server_prompt_template(
# 模板类型,可选值为"llm_chat"或"knowledge_base_chat"
type: Literal["llm_chat", "knowledge_base_chat"] = Body(
"llm_chat", description="模板类型,可选值:llm_chat,knowledge_base_chat"
),
# 模板名称,默认为"default"
name: str = Body("default", description="模板名称"),
) -> str:
"""
根据提供的模板类型和名称,获取相应的prompt模板。
参数:
- type: 模板类型,可以是"llm_chat"或"knowledge_base_chat"。
- name: 模板名称。
返回:
- 与指定类型和名称匹配的prompt模板字符串。
"""
return get_prompt_template(type=type, name=name)
WebUI服务
MaxKB知识库
Github链接:https://github.com/1Panel-dev/MaxKB
Copilot+ 云桌面
puter
puter WebOS:Puter是一个先进的开源桌面环境,运行在浏览器中,旨在具备丰富的功能、异常快速和高度可扩展性。
neko
虚拟浏览器 Neko是一款在 Docker 中运行、采用 WebRTC 技术的自托管虚拟浏览器,功能强大。它允许在虚拟环境中运行全功能浏览器,保障安全私密的上网体验,支持多用户同时访问。可用于多种场景,如团队协作、个人隐私保护、举办活动等。
部署neko
git clone https://github.com/m1k1o/neko.git
cd neko/
# 使用chromium的镜像,并设置http代理,没有代理的话就移除对应配置
root@llm-test:~/neko# vim docker-compose.yaml
version: "3.4"
services:
neko:
image: "m1k1o/neko:chromium"
restart: "unless-stopped"
shm_size: "8gb"
cpus: 4
cap_add:
- SYS_ADMIN
ports:
- "8080:8080"
- "52000-52100:52000-52100/udp"
environment:
HTTP_PROXY: http://<你的代理地址>:31475
HTTPS_PROXY: http://<你的代理地址>:31475
NO_PROXY: localhost,127.0.0.1
NEKO_SCREEN: 1920x1080@30
NEKO_PASSWORD: neko
NEKO_PASSWORD_ADMIN: admin
NEKO_EPR: 52000-52100
NEKO_ICELITE: 1
NEKO_NAT1TO1: <你的内网IP> # 部署在内网环境的话,要设置这个映射IP
启动neko容器
docker-compose up -d
Chromium下载安装扩展支持,创建policies.json文件
root@llm-test:~/neko# vim .docker/chromium/policies.json
{
"AutofillAddressEnabled": false,
"AutofillCreditCardEnabled": false,
"BrowserSignin": 0,
"DefaultNotificationsSetting": 2,
"DeveloperToolsAvailability": 1, # 1表示无论在什么情况下,都可以访问开发者工具和控制台
"EditBookmarksEnabled": false,
"FullscreenAllowed": true,
"IncognitoModeAvailability": 1,
"SyncDisabled": true,
"AutoplayAllowed": true,
"BrowserAddPersonEnabled": false,
"BrowserGuestModeEnabled": false,
"DefaultPopupsSetting": 2,
"DownloadRestrictions": 0,
"VideoCaptureAllowed": true,
"AllowFileSelectionDialogs": true, # 允许文件选择对话框加载私有extension
"PromptForDownloadLocation": false,
"BookmarkBarEnabled": false,
"PasswordManagerEnabled": false,
"BrowserLabsEnabled": false,
"URLAllowlist": [
"file:///home/neko/Downloads",
"file://*",
"chrome://policy"
],
"ExtensionInstallForcelist": [
"cjpalhdlnbpafiamejdnhcphjbkeiagm;https://clients2.google.com/service/update2/crx",
"mnjggcdmjocbbbhaepdhchncahnbgone;https://clients2.google.com/service/update2/crx"
],
"ExtensionInstallAllowlist": [
"cjpalhdlnbpafiamejdnhcphjbkeiagm",
"mnjggcdmjocbbbhaepdhchncahnbgone",
"padekgcemlokbadohgkifijomclgjgif"
]
}
拷贝policies.json至docker目录下,并重启docker容器
docker cp policies.json <neko-docker-id>:/etc/chromium/policies/managed/policies.json
docker restart <neko-docker-id>
部署失败排错参考:https://neko.m1k1o.net/#/getting-started/troubleshooting
PDF转markdown
browser-use
browser-use是一个AI自主驱动浏览器工作的项目。
通过一个购物场景的例子,来展示browser-use是如何工作的?购物场景:在电商网站查找产品、添加到购物车并结账
import asyncio
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from browser_use import Agent
# 加载环境变量
load_dotenv()
async def main():
# 初始化LLM模型
llm = ChatOpenAI(
model="gpt-4o",
temperature=0.1
)
# 创建Agent并定义任务
agent = Agent(
task="在京东上搜索AirPods Pro耳机,找到价格低于1500元且评分高的商品,添加到购物车,然后前往结账页面",
llm=llm,
generate_gif=True # 生成操作的动态图
)
# 执行任务
await agent.run()
if __name__ == "__main__":
asyncio.run(main())
执行过程详解:
- 初始化阶段:
- 代码创建了一个Agent实例,并指定了使用GPT-4o模型
- 任务描述被传递给Agent:“在京东上搜索AirPods Pro耳机,找到价格低于1500元且评分高的商品,添- 加到购物车,然后前往结账页面”
- 浏览器启动:
- 当agent.run()被调用时,browser-use会启动一个由Playwright控制的Chrome浏览器实例
- 浏览器窗口打开,准备接受命令
- 任务规划:
- LLM(GPT-4o)接收任务描述,并制定执行计划:
- 导航到京东网站
- 搜索AirPods Pro
- 分析搜索结果,找到符合条件的商品
- 添加到购物车
- 前往结账页面
- 执行搜索:
- Agent指示Controller执行go_to_url操作,导航到https://www.jd.com
- 浏览器加载京东首页
- DOMService提取页面结构,找到搜索框元素
- LLM决定在搜索框中输入"AirPods Pro”
- Agent执行input_text操作,填写搜索框
- 然后执行click_element操作,点击搜索按钮
- 分析搜索结果:
- 搜索结果页加载后,DOMService提取所有产品信息
- 页面内容被发送给LLM进行分析
- LLM处理信息,识别出价格和评分信息
- LLM找到一款价格为1299元且评分4.9的AirPods Pro
- 通过DOM解析,确定目标产品的元素索引号
- 添加到购物车:
- LLM决定点击该产品,Agent执行click_element_by_index
- 产品详情页加载后,DOMService重新解析DOM
- LLM识别"加入购物车"按钮
- Agent执行click_element_by_text操作,参数为"加入购物车"
- 系统可能需要处理弹出的确认对话框,再次点击确认
- 前往结账:
- LLM发现需要点击"去购物车结算"按钮
- Agent执行click_element_by_text操作
- 购物车页面加载后,DOM服务再次提取页面结构
- LLM识别"去结算"按钮
- Agent执行click_element_by_text操作,点击"去结算"
- 任务完成与报告:
- 当到达结账页面后,LLM确认任务完成
- Agent执行done操作,标记任务完成
- 如果启用了GIF生成,系统会创建一个展示整个过程的GIF动画
- 任务执行结果被返回,包括所选产品的信息和价格
在整个过程中:
- Browser-use持续捕获DOM状态和截图,帮助LLM理解页面
- LLM在每一步都会评估当前状态,决定下一步行动
- 如果遇到意外情况(如弹窗、登录提示),LLM会动态调整策略
- 系统会保持操作历史,使LLM能够了解之前的行动和结果
问题1:browser-use的Controller定义中封装了很多操作浏览器的函数,什么时候触发对应的函数操作?
在browser-use中,决定何时触发特定函数(如go_to_url或click_element)是由LLM(如GPT-4o)基于当前浏览器状态和任务目标来做出的。这个决策过程是这样工作的:
- 基于LLM的决策机制:
- LLM接收当前浏览器状态(DOM结构、页面截图)和任务描述
- LLM分析这些信息,确定完成任务所需的下一步操作
- LLM以ActionModel格式返回决策,指定要执行的操作和必要参数
- ActionModel选择过程:
- 从代码分析可以看到,Controller注册了多种操作(如go_to_url, click_element等)
- 这些操作被提供给LLM作为可用工具的描述
- LLM根据上下文选择最合适的操作
- 具体决策示例:
- 如果LLM发现需要访问新网站,会选择go_to_url操作
- 如果LLM发现页面上有需要点击的元素,会选择click_element相关操作
- 如果需要输入文本,会选择input_text操作
- 决策示例场景:
- 任务开始时:LLM会选择go_to_url访问目标网站
- 看到搜索框时:LLM会选择input_text输入搜索词,然后click_element点击搜索按钮
- 找到目标产品时:LLM会选择click_element点击该产品
- 需要添加到购物车时:LLM会寻找并click_element点击"加入购物车"按钮
- 代码实现关键点:
- 在agent/service.py中,Agent会将当前状态发送给LLM
- LLM输出被解析为ActionModel对象
- Controller使用这些ActionModel执行相应操作
- 每个操作的结果又会成为LLM下一次决策的输入
本质上,LLM充当了"大脑",通过分析当前状态和目标,决定在各个时刻使用什么操作,就像人类在浏览网页时会决定何时点击,何时输入,何时导航到新网站一样。这种决策过程是动态的,而不是预编程的,使AI能够适应各种网页场景。
browser-use操作浏览器的处理流程:
flowchart TB
%% 定义节点样式
classDef userNode fill:#FFD700,stroke:#FF8C00,stroke-width:2px,color:#8B4513,font-weight:bold
classDef agentNode fill:#B0E0E6,stroke:#4682B4,stroke-width:2px,color:#000080,font-weight:bold
classDef browserNode fill:#98FB98,stroke:#2E8B57,stroke-width:2px,color:#006400,font-weight:bold
classDef llmNode fill:#FFC0CB,stroke:#FF69B4,stroke-width:2px,color:#8B008B,font-weight:bold
classDef controllerNode fill:#E6E6FA,stroke:#8A2BE2,stroke-width:2px,color:#4B0082,font-weight:bold
classDef actionNode fill:#F0E68C,stroke:#DAA520,stroke-width:2px,color:#8B4513
classDef decisionNode fill:#FF6347,stroke:#FF4500,stroke-width:3px,color:#FFFFFF,font-weight:bold
classDef reportNode fill:#7FFFD4,stroke:#00CED1,stroke-width:2px,color:#008080,font-weight:bold
classDef errorNode fill:#FFA07A,stroke:#FF0000,stroke-width:2px,color:#8B0000,font-weight:bold
%% 主要节点
A(("🧑 用户")) -->|1. 定义任务| B["🤖 Agent初始化"]
B -->|2. 创建| C["🌐 Browser实例"]
B -->|3. 配置| D["🧠 LLM模型"]
B -->|4. 初始化| E["🎮 Controller"]
subgraph "核心执行循环"
F["📊 获取浏览器状态"] -->|5| G["🔍 DOM分析"]
G -->|6| H["💾 状态处理"]
H -->|7| I["💭 LLM决策"]
I -->|8| J["⚙️ 操作执行"]
J -->|13. 循环| F
end
C -->|2.1| K["⚡ Playwright浏览器"]
K -->|5.1| L["🖥️ 网页"]
L -->|5.2| M["🧩 DOM Service"]
M -->|5.3| G
I -->|8.1| N["📝 ActionModel"]
N -->|8.2| E
E -->|9| O["🛠️ 调用操作"]
O -->|10| K
J -->|11| P{"✅ 任务完成?"}
P -->|12a. 是| Q["📊 生成报告"]
P -->|12b. 否| F
subgraph "浏览器操作类型"
O1["🔗 go_to_url"]
O2["👆 click_element"]
O3["⌨️ input_text"]
O4["⏬ scroll"]
O5["⚙️ 其他操作"]
end
O -->|9.1| O1
O -->|9.2| O2
O -->|9.3| O3
O -->|9.4| O4
O -->|9.5| O5
subgraph "状态组件"
S1["🔗 URL"]
S2["📄 标题"]
S3["🧩 DOM结构"]
S4["📸 截图"]
S5["📜 操作历史"]
end
F -->|5.1a| S1
F -->|5.1b| S2
F -->|5.1c| S3
F -->|5.1d| S4
H -->|7.1| S5
subgraph "错误处理流程"
R["🚨 操作失败"] -->|E1| T["🔄 策略调整"]
T -->|E2| I
end
J -->|E0. 失败时| R
%% 应用样式
class A userNode
class B agentNode
class C browserNode
class D llmNode
class E controllerNode
class P decisionNode
class Q reportNode
class R,T errorNode
class O1,O2,O3,O4,O5 actionNode
%% 定义子图样式
style 核心执行循环 fill:#f8f8ff,stroke:#4169E1,stroke-width:2px,color:#000080,border-radius:10px
style 浏览器操作类型 fill:#FFFAF0,stroke:#CD853F,stroke-width:2px,color:#8B4513,border-radius:10px
style 状态组件 fill:#F0FFF0,stroke:#2E8B57,stroke-width:2px,color:#006400,border-radius:10px
style 错误处理流程 fill:#FFF0F5,stroke:#FF1493,stroke-width:2px,color:#8B0000,border-radius:10px
LLM大模型评测
https://ai-bot.cn/,这个网站类似AI工具的链接导航,有MMLU、Open LLM Leaderboard、OpenCompass等;其中中文大模型评测的话,推荐OpenCompass,国产大模型阿里通义千问在其github展示的评测表现也是基于OpenCompass.
FastChat也提供一个工具llm_judge
编程类模型评估标准参考:
- 主要HumanEval/Babelcode指标,得分越高越好
- 模型参数量不宜过大,过大增加精调和部署成本
- 最好具备一定中文能力,但是编码能力优先级更高
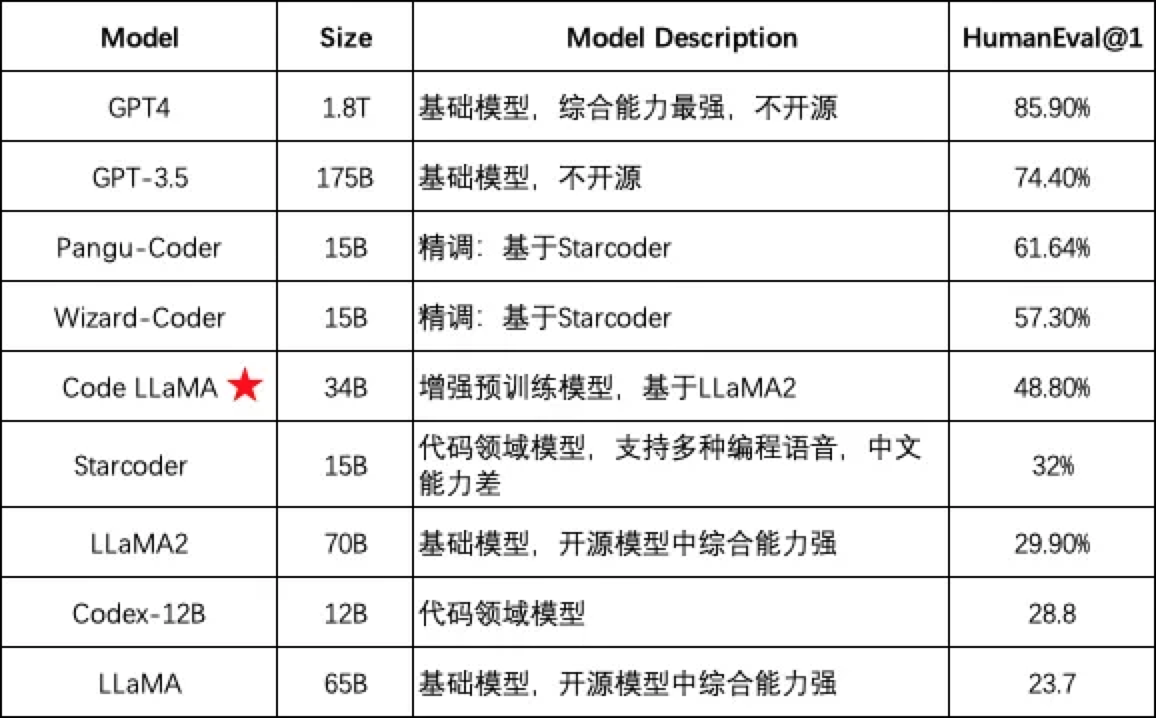
OpenCompass
简介
OpenCompass司南2.0是大模型评测体系,主要由三大核心模块构建而成:CompassKit、CompassHub以及CompassRank组成。
- CompassRank是一个排行榜体系,包含开源基准测试项目、私有基准测试
- CompassHub是一个基准测试资源导航平台
- CompassKit是一系列专为大型语言模型和大型视觉-语言模型打造的强大评估工具合集
OpenCompass是面向大模型评测的一站式平台。其主要特点如下:
- 开源可复现:提供公平、公开、可复现的大模型评测方案
- 全面的能力维度:五大维度设计,提供 70+ 个数据集约 40 万题的的模型评测方案,全面评估模型能力
- 丰富的模型支持:已支持 20+ HuggingFace 及 API 模型
- 分布式高效评测:一行命令实现任务分割和分布式评测,数小时即可完成千亿模型全量评测
- 多样化评测范式:支持零样本、小样本及思维链评测,结合标准型或对话型提示词模板,轻松激发各种模型最大性能
- 灵活化拓展:想增加新模型或数据集?想要自定义更高级的任务分割策略,甚至接入新的集群管理系统?OpenCompass 的一切均可轻松扩展!
原理
OpenCompass原理图:
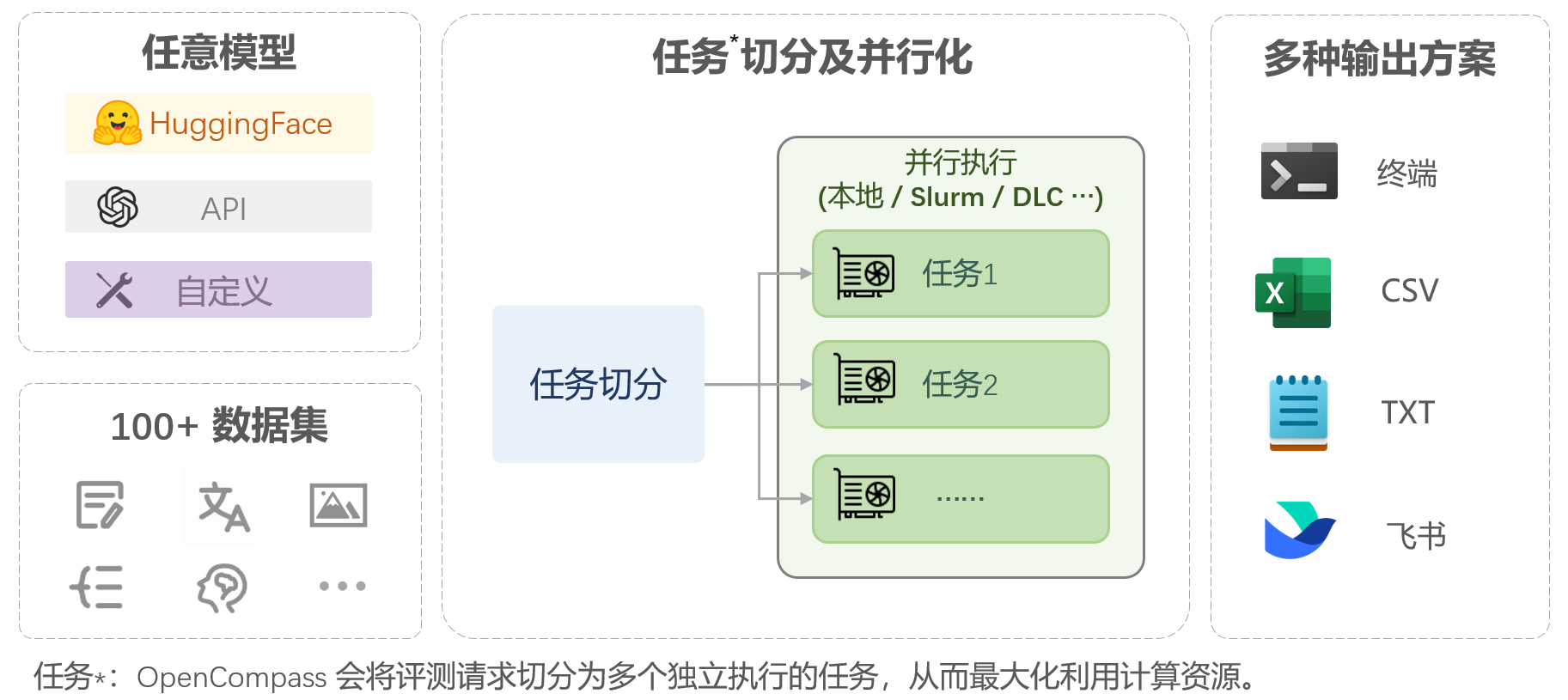
实践
安装opencompass
git clone https://github.com/open-compass/opencompass opencompass
cd opencompass
pip install -e
# 如果需要使用各个API模型,`pip install -r requirements/api.txt`安装API模型的相关依赖
下载数据集
wget https://github.com/open-compass/opencompass/releases/download/0.2.2.rc1/OpenCompassData-core-20240207.zip
unzip OpenCompassData-core-20240207.zip
评测
#官方测试用例llama_7b
python run.py --models hf_llama_7b --datasets mmlu_ppl ceval_ppl
#评测本地微调后的模型phi-3-mini-4k
python run.py --datasets ceval_gen \
--hf-path /root/phi-3-mini-4k-with-lora/ \
--model-kwargs device_map='auto' trust_remote_code=True \
--max-seq-len 2048 \
--batch-size 8 \
--num-gpus 1
评测结果输出
dataset version metric mode _hf
---------------------------------------------- --------- -------- ------ -----
ceval-computer_network db9ce2 accuracy gen 47.37
ceval-operating_system 1c2571 accuracy gen 57.89
ceval-computer_architecture a74dad accuracy gen 42.86
ceval-college_programming 4ca32a accuracy gen 54.05
ceval-college_physics 963fa8 accuracy gen 42.11
ceval-college_chemistry e78857 accuracy gen 29.17
ceval-advanced_mathematics ce03e2 accuracy gen 36.84
ceval-probability_and_statistics - - - -
ceval-discrete_mathematics - - - -
ceval-electrical_engineer - - - -
ceval-metrology_engineer - - - -
ceval-high_school_mathematics - - - -
ceval-high_school_physics - - - -
ceval-high_school_chemistry - - - -
ceval-high_school_biology - - - -
ceval-middle_school_mathematics - - - -
ceval-middle_school_biology - - - -
ceval-middle_school_physics - - - -
ceval-middle_school_chemistry - - - -
ceval-veterinary_medicine - - - -
ceval-college_economics - - - -
ceval-business_administration - - - -
ceval-marxism - - - -
ceval-mao_zedong_thought - - - -
ceval-education_science - - - -
ceval-teacher_qualification - - - -
ceval-high_school_politics - - - -
ceval-high_school_geography - - - -
ceval-middle_school_politics - - - -
ceval-middle_school_geography - - - -
ceval-modern_chinese_history - - - -
ceval-ideological_and_moral_cultivation - - - -
ceval-logic - - - -
ceval-law - - - -
ceval-chinese_language_and_literature - - - -
ceval-art_studies - - - -
ceval-professional_tour_guide - - - -
ceval-legal_professional - - - -
ceval-high_school_chinese - - - -
ceval-high_school_history - - - -
ceval-middle_school_history - - - -
ceval-civil_servant - - - -
ceval-sports_science - - - -
ceval-plant_protection - - - -
ceval-basic_medicine - - - -
ceval-clinical_medicine - - - -
ceval-urban_and_rural_planner - - - -
ceval-accountant - - - -
ceval-fire_engineer - - - -
ceval-environmental_impact_assessment_engineer - - - -
ceval-tax_accountant - - - -
ceval-physician - - - -
05/26 15:16:32 - OpenCompass - INFO - write summary to /root/opencompass/outputs/default/20240526_151246/summary/summary_20240526_151246.txt
05/26 15:16:32 - OpenCompass - INFO - write csv to /root/opencompass/outputs/default/20240526_151246/summary/summary_20240526_151246.csv
自定义数据集
- 数据集格式:支持 .jsonl 和 .csv 两种格式的数据集
- 任务类型:包括选择题 (mcq) 和问答 (qa) 两种
选择题的.jsonl格式:
{"question": "165+833+650+615=", "A": "2258", "B": "2263", "C": "2281", "answer": "B"}
{"question": "368+959+918+653+978=", "A": "3876", "B": "3878", "C": "3880", "answer": "A"}
{"question": "776+208+589+882+571+996+515+726=", "A": "5213", "B": "5263", "C": "5383", "answer": "B"}
{"question": "803+862+815+100+409+758+262+169=", "A": "4098", "B": "4128", "C": "4178", "answer": "C"}
选择题的.csv格式:
question,A,B,C,answer
127+545+588+620+556+199=,2632,2635,2645,B
735+603+102+335+605=,2376,2380,2410,B
506+346+920+451+910+142+659+850=,4766,4774,4784,C
504+811+870+445=,2615,2630,2750,B
问答的.jsonl格式:
{"question": "752+361+181+933+235+986=", "answer": "3448"}
{"question": "712+165+223+711=", "answer": "1811"}
{"question": "921+975+888+539=", "answer": "3323"}
{"question": "752+321+388+643+568+982+468+397=", "answer": "4519"}
问答的.csv格式:
question,answer
123+147+874+850+915+163+291+604=,3967
149+646+241+898+822+386=,3142
332+424+582+962+735+798+653+214=,4700
649+215+412+495+220+738+989+452=,4170
加载自定义数据集使用--custom-dataset-path参数来加载
LLM大模型量化
什么是量化? 举个例子来解释量化,模型使用16位浮点数作为权重进行训练,可以将其缩小到4位整数以进行推理,而不会失去太多的功率,收益是会节省大量的GPU计算资源。
llama.cpp
llama.cpp主要解决的是推理过程中的性能问题。主要有两点优化:
- llama.cpp使用的是C/C++语言写的机器学习张量库ggml
- llama.cpp提供了模型量化的工具
llama.cpp量化出来的模型格式是GGUF,准备来说GGUF是一种模型量化方法,除了GGUF,还有GPTQ、AWQ等。
- GPTQ:通过最小化该权重的均方误差将所有权重压缩到4位,在推理过程中,它将动态地将其权重去量化为float16,以提高性能,同时保持低内存。如果没有高性能的GPU,建议切换为GGUF,支持在cpu上运行。
- GGUF:允许使用CPU来运行模型,也可以把某些层使用GPU来提高速度
- AWQ:激活感知权重量化,权重并非同等重要,在量化过程中会跳过一小部分权重,这有助于减轻量化损失。
使用llama.cpp/main可直接加载GGUF格式的模型
./llama.cpp/main -m model-unsloth.Q4_K_M.gguf -p "Building a website can be done in 10 simple steps:\nStep 1:" -n 400 -e
使用llama.cpp转换格式,HF转换为16bit GGUF格式
python llama.cpp/convert-hf-to-gguf.py --outfile phi-3-mini-4k-lora.fp16.gguf --outtype f16 phi-3-mini-4k-with-lora/
使用llama.cpp把16bit量化为4bit GGUF
./llama.cpp/quantize phi-3-mini-4k-lora.fp16.gguf phi-3-mini-4k-lora.Q4_K_M.gguf Q4_K_M
使用llama-gguf-split拆分GGUF文件
./llama-gguf-split --split --split-max-size 500M input.gguf
使用llama-gguf-split合并GGUF文件
./llama-gguf-split --merge part-00001-of-00002.gguf output.gguf
纯CPU运行DeepSeek-R1 671B
纯CPU跑的话,对内存有要求,先用mlc工具对内存带宽进行测试 MLC工具下载链接
(base) [root@xxx data]# ./mlc
Intel(R) Memory Latency Checker - v3.11b
Measuring idle latencies for sequential access (in ns)...
Numa node
Numa node 0 1 2 3
0 74.0 139.8 137.2 139.8
1 139.9 75.3 139.9 135.5
2 136.0 137.6 73.5 140.1
3 137.6 133.3 139.7 73.4
Measuring Peak Injection Memory Bandwidths for the system
Bandwidths are in MB/sec (1 MB/sec = 1,000,000 Bytes/sec)
Using all the threads from each core if Hyper-threading is enabled
Using traffic with the following read-write ratios
ALL Reads : 283078.1
3:1 Reads-Writes : 288572.6
2:1 Reads-Writes : 294159.5
1:1 Reads-Writes : 294944.1
Stream-triad like: 251869.9
...
上面执行结果显示内存带宽达280多GB/s
下载DeepSeek-R1量化模型(以DeepSeek-R1-Q4_K_M为例)
git clone --no-checkout https://www.modelscope.cn/unsloth/DeepSeek-R1-GGUF.git
##只下载Q4量化的版本
git lfs pull --include="DeepSeek-R1-Q4_K_M/*"
模型推理,这里量化模型用的是unsloth的DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S
./llama.cpp/llama-cli -m DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S.gguf \
--predict 2048 \
--prompt "作为一个资深的电商行业分析师,电商平台在2024年都面临了很大的增长挑战,分析一下唯品会作为电商特卖平台在2025年的机会以及如何提升用户的规模和ARPU值?" \
--no-conversation \
--chat-template deepseek2 \
--cache-type-k q8_0
--threads <nums>并发线程数,默认是操作系统CPU核数的一半
Web UI方式启动
./llama.cpp/llama-server -m DeepSeek-R1-GGUF/DeepSeek-R1-UD-IQ1_S/DeepSeek-R1-UD-IQ1_S.gguf \
--predict 2048 \
--host 0.0.0.0 \
--port 8080 \
--chat-template deepseek2 \
--parallel 1 \
--ctx-size 16384 \
--cache-type-k q8_0
浏览器访问http://<server-ip>:8080/
纯CPU运行 VS CPU/GPU混合运行
硬件环境:
CPU: 2 * Intel(R) Xeon(R) Gold 6430(支持AMX) 128核
内存:16 * 64GB Samsung,内存带宽400G/s以上(mlc工具测试)
磁盘:NVME SSD 2T
GPU: 8 * Nvidia 4090(24G显存)
查看PCIe带宽(混合运行的情况下,GPU需要与CPU通信,效率受PCIe带宽限制)
[root]# lspci | grep -i <设备关键词> # 如GPU设备用"nvidia"
[root]# sudo lspci -vvv -s <PCI地址> | grep -iE '(LnkSta:|Width|Speed)'
LnkCap: Port #0, Speed 16GT/s, Width x16, ASPM L1, Exit Latency L1 <16us
LnkSta: Speed 2.5GT/s (downgraded), Width x16 (ok)
Speed:表示当前链路速率(PCIe 1.0=2.5GT/s,2.0=5GT/s,3.0=8GT/s,4.0=16GT/s) Width:表示通道数(如x16)
从输出结果来看的话,(downgraded):链路速度被降级,未达到设备或插槽支持的最高速度。
计算理论带宽:公式:带宽 = 速率 × 通道数 × 编码效率
编码效率:
PCIe 1.0/2.0:8b/10b编码 → 效率80%
PCIe 3.0/4.0/5.0:128b/130b编码 → 效率~98.46%
PCIe 6.0:242B/256B编码 → 效率~94.53%
示例(PCIe 3.0 x16):
8GT/s × 16通道 × 0.9846 ≈ 126.03 GB/s(双向)
编译llama.cpp,支持把某些layers放到GPU上来运行
cd llama.cpp/
# 编译开启Nvidia GPU acceleration
cmake -B build -DGGML_CUDA=ON
# 支持并发编译
cmake --build build --config Release -j 16
CPU/GPU混合运行token速率测试(设置20 layers在GPU上运行)
./build/bin/llama-cli -m /opt/llm/DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-00001-of-00009.gguf \
--n-gpu-layers 20 \
--predict 2048 \
--prompt "作为一个资深的电商行业分析师,电商平台在2024年都面临了很大的增长挑战,分析一下唯品会作为电商特卖平台在2025年的机会以及如何提升用户 的规模和ARPU值?" \
--no-conversation \
--chat-template deepseek2 \
--cache-type-k q8_0
llama_perf_sampler_print: sampling time = 207.99 ms / 2093 runs ( 0.10 ms per token, 10062.84 tokens per second)
llama_perf_context_print: load time = 30543.96 ms
llama_perf_context_print: prompt eval time = 46632.33 ms / 45 tokens ( 1036.27 ms per token, 0.96 tokens per second)
llama_perf_context_print: eval time = 376804.69 ms / 2047 runs ( 184.08 ms per token, 5.43 tokens per second)
llama_perf_context_print: total time = 424232.40 ms / 2092 tokens
纯CPU运行token速率测试
CUDA_VISIBLE_DEVICES=none ./build/bin/llama-cli -m /opt/llm/DeepSeek-R1-Q4_K_M/DeepSeek-R1-Q4_K_M-0000
1-of-00009.gguf \
--n-gpu-layers 0 \
--predict 2048 \
--prompt "作为一个资深的电商行业分析师,电商平台在2024年都面临了很大的增长挑战,分析一下唯品会作为电商特卖平台在20
25年的机会以及如何提升用户的规模和ARPU值?" \
--no-conversation \
--chat-template deepseek2 \
--cache-type-k q8_0
llama_perf_sampler_print: sampling time = 105.13 ms / 1137 runs ( 0.09 ms per token, 10815.59 tokens per second)
llama_perf_context_print: load time = 30461.44 ms
llama_perf_context_print: prompt eval time = 2894.77 ms / 45 tokens ( 64.33 ms per token, 15.55 tokens per second)
llama_perf_context_print: eval time = 200813.85 ms / 1091 runs ( 184.06 ms per token, 5.43 tokens per second)
llama_perf_context_print: total time = 204113.93 ms / 1136 tokens
对比纯CPU和 CPU/GPU混合运行的token速率差不多
ktransformers
清华开源了KTransformers,KTransformers是一个基于Python的开源框架,专注于优化大模型的本地推理体验。通过ktransformers可以实现在一张4090的卡运行DeepSeek R1(CPU/GPU混合推理),部署依赖GPU,版本推荐使用v0.2.1.post1, v0.3.0目前还处于preview阶段 ktransformers部署文档:https://github.com/kvcache-ai/ktransformers/blob/main/doc/en/install.md
flash_attn安装
pip install flash_attn
token速率测试
python -m ktransformers.local_chat \
--model_path deepseek-ai/DeepSeek-R1 \
--gguf_path /opt/llm/DeepSeek-R1-Q4_K_M/ \
--cpu_infer 65 \
--max_new_tokens 1024
CPU/GPU混合推理,速率大概9~10token/s,模型的layers放置到单卡GPU和多卡GPU的推理性能差不多,因为Nvidia RTX 4090无法通过NVLink桥接器实现GPU直连,多卡间通信需通过PCIe总线完成。目前ktransformers还只支持单并发,相关的issue讨论参考:https://github.com/kvcache-ai/ktransformers/issues/386
GPTQ
安装auto-gptq库,GPTQ量化仅适用于文本模型
pip install auto-gptq
pip install --upgrade accelerate optimum transformers
GPTQ量化模型
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "microsoft/Phi-3-mini-4k-instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
# 创建GPTQ配置,需要传入的参数:bits的数量、校准量化的数据集、模型的分词器
gptq_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
# 也可以传入自定义数据集,官方强烈建议使用GPTQ论文中提供的数据集
# dataset = ["auto-gptq is an easy-to-use model quantization library with user-friendly apis, based on GPTQ algorithm."]
# gptq_config = GPTQConfig(bits=4, dataset = dataset, tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=gptq_config)
model.save_pretrained("Phi-3-mini-4k-instruct-GPTQ-Int4")
tokenizer.save_pretrained("Phi-3-mini-4k-instruct-GPTQ-Int4")
AWQ
使用AWQ需要访问NVIDIA GPU。目前不支持CPU推理。目前与Transformers的集成仅适用于使用autoawq、llm-awq量化后的模型。
安装autoawq库
pip install -q transformers accelerate autoawq
使用autoawq进行量化,使用colab一直卡住?下次换成本地量化待验证中
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
#model_path = "facebook/opt-125m"
model_path = "Qwen/Qwen1.5-0.5B-Chat"
quant_path = "Qwen1.5-0.5B-Chat-AWQ"
quant_config = {"zero_point": True, "q_group_size": 128, "w_bit": 4, "version":"GEMM"}
# Load model
model = AutoAWQForCausalLM.from_pretrained(model_path, device_map="auto", safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
# Quantize
model.quantize(tokenizer, quant_config=quant_config)
执行quantize的函数时出现Token indices sequence length is longer than the specified maximum sequence length for this model (909 > 512).的提示,这个提示并非是错误;此外并非所有的模型都支持autoawq,autoawq支持的模型列表参考:https://github.com/casper-hansen/AutoAWQ/blob/main/awq/models/auto.py#L7
兼容transformers,并保存模型
from transformers import AwqConfig
# modify the config file so that it is compatible with transformers integration
quantization_config = AwqConfig(
bits=quant_config["w_bit"],
group_size=quant_config["q_group_size"],
zero_point=quant_config["zero_point"],
version=quant_config["version"].lower(),
).to_dict()
# the pretrained transformers model is stored in the model attribute + we need to pass a dict
model.model.config.quantization_config = quantization_config
# save model weights
model.save_quantized(quant_path)
tokenizer.save_pretrained(quant_path)
BitSandBytes
Transformers与bitsandbytes做了紧密集成,bitsandbytes集成支持8bit和4bit精度数据类型,用于加载大模型,这种方式可以节省内存
#
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct",
trust_remote_code=True,
device_map="auto",
quantization_config=quantization_config, torch_dtype=None)
load_in_4bit应用4位动态量化来极大地减少资源需求,也支持load_in_8bit
LLM大模型微调
为什么要进行大模型微调?大模型通常是针对通用场景来训练的,针对垂直领域的特定场景可能并不适用。所以需要对大模型参数进行微调,以便在特定场景下的效果更好。具体体现在这几个方面:提高准确性、提高效率、减少训练的数据需求。
什么是Transformer
Transformer是一种深度学习模型,最初由Google在2017年在论文《Attention is All You Need》中提出,主要用于自然语言处理任务,如机器翻译。它彻底改变了机器翻译领域的架构,突破了之前基于循环神经网络(RNN)和编码-解码模型(如LSTM和GRU)的局限性。
Transformer模型的核心特点是使用自注意力机制 (Self-Attention),这使得模型能够同时关注输入序列中的所有位置,而不仅仅是前一个或后一个位置,从而极大地提高了处理长序列数据的能力。它不再需要按序列顺序传递信息,而是对每个位置的输入进行独立的处理,降低了计算复杂度。
Transformer模型通常由以下组件组成:
- Encoder: 用来处理输入序列,将输入映射到一个高维空间,并产生一组表示(也称为编码器输出)。
- Decoder: 根据编码器输出和目标序列生成解码输出,用于机器翻译等任务。
- Multi-Head Attention: 在Encoder和Decoder中,使用多头自注意力来增强模型对输入序列的理解。
- Positional Encoding: 为输入序列添加位置信息,使得模型能够理解序列中的相对位置。
- Feed-Forward Networks (FFN): 一个线性层后接一个激活函数(如ReLU),用于进一步处理自注意力和位置编码后的输出。
由于其优秀的性能和对序列数据的强大处理能力,Transformer后来被广泛应用于语音识别、文本生成、问答系统等多个自然语言处理任务中。
BERT与Transformer的区别:
- BERT模型是Transformer的一种变体,采用双向编码器结构,而Transformer模型通常使用编码器-解码器结构。
- BERT模型的预训练过程也与之有不同,采用了Masked Language Modeling和下一句预测任务。
QLoRA/LoRA微调技术
知乎有篇文章对大模型微调技术QLoRA、LoRA的介绍:https://zhuanlan.zhihu.com/p/671089942,使用https://kimi.moonshot.cn/可以快速解读论文
LoRA和QLoRA是两种用于大型预训练模型(如Transformer模型)微调的技术:
LoRA(Low-Rank Adaptation)
- 低秩矩阵近似:LoRA的核心思想是使用低秩矩阵来近似原始模型中的权重矩阵。低秩矩阵具有较少的参数,因此可以减少微调过程中的计算和存储需求。
- 微调过程:在微调阶段,LoRA不是直接更新原始模型的权重,而是更新这些低秩矩阵。这样可以在不显著增加模型大小和计算复杂度的情况下,对模型进行有效的微调。
- 适应性:通过这种方式,LoRA允许模型在保持预训练知识的同时,学习特定任务的特征,从而提高微调后模型在下游任务上的性能。
QLoRA(Quantized Low-Rank Adaptation)
- 量化:QLoRA是LoRA的扩展,它在低秩矩阵近似的基础上引入了量化技术。量化是一种压缩技术,可以进一步减少模型的参数数量和计算需求。
- 低秩量化矩阵:在QLoRA中,微调涉及的是一组量化后的低秩矩阵。这些矩阵在微调过程中被更新,以适应特定任务的需求。
- 效率与性能:QLoRA旨在实现与LoRA相似的适应性,同时通过量化进一步降低模型的内存占用和加速推理过程,使得模型更适合在资源受限的环境下部署。
- 应用场景:这些技术尤其适用于大型模型,如NLP领域的Transformer模型,它们在预训练阶段已经学习了大量的语言知识。通过LoRA或QLoRA微调,这些模型可以更有效地适应特定的下游任务,如文本分类、机器翻译或问答系统,而无需从头开始训练整个模型。
LoRA和QLoRA通过减少微调过程中的参数数量和计算量,使得大型模型的微调变得更加高效,同时尽可能保留模型在预训练阶段获得的知识。这些技术对于推动大型模型在实际应用中的部署具有重要意义。
LLM微调项目unsloth
unsloth是通过QLoRA、LoRA技术来加速大模型微调,能够提升2~5倍的速度并且减少80%的内存占用
主要特性:
- 所有内核均采用OpenAI的Triton语言编写。采用手动反向传播引擎。
- 无精度损失,所有方法都是精确的。
- 支持自2018年起支持NVIDIA GPU。最低CUDA能力7.0(V100、T4、Titan V、RTX 20、30、40x、A100、H100、L40 等)GTX 1070、1080可以工作,但速度很慢。
- 在Linux和Windows的WSL上可以工作。
- 通过bitsandbytes支持4位和16位QLoRA/LoRA微调。
- 它的开源版本训练速度提高5倍,(Unsloth Pro)[https://unsloth.ai/]版本,训练速度可提高30倍
本地微调llama-3-8b
参考youtube上的视频教程:https://www.youtube.com/watch?v=LPmI-Ok5fUc,这里选用Meta开源的llama3-8B模型为例进行微调,llama3在各种基准测试中表现出色,属于先天优势。
安装依赖
安装nvidia驱动(这里用的是NVIDIA GeForce RTX 3090)、cuda
- nvidia驱动下载:https://www.nvidia.com/Download/index.aspx
- cuda下载:https://developer.nvidia.com/cuda-toolkit-archive
cuda的脚本执行完后,会在终端输出一些待操作的信息,需要设置环境变量才生效,以cuda 12.2版本为例
export PATH=$PATH:/usr/local/cuda-12.2/bin
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/cuda-12.2/lib64
# nvcc -V
nvcc: NVIDIA (R) Cuda compiler driver
Copyright (c) 2005-2023 NVIDIA Corporation
Built on Tue_Jun_13_19:16:58_PDT_2023
Cuda compilation tools, release 12.2, V12.2.91
Build cuda_12.2.r12.2/compiler.32965470_0
安装微调库
使用conda安装微调环境
conda create --name unsloth_env python=3.10
conda activate unsloth_env
conda install pytorch-cuda=12.1 pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers
pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install --no-deps trl peft accelerate bitsandbytes
安装Jupyter(可选)
安装jupyter,也可以使用ipython在终端实现交互式python效果
conda install -c anaconda ipykernel jupyter chardet
# 在ipykernel中添加虚拟环境,以便在jupyter notebook中使用conda虚拟环境
python -m ipykernel install --user --name=unsloth_env
# 查看jupyter kernel列表,是否生效
jupyter kernelspec list
0.00s - Debugger warning: It seems that frozen modules are being used, which may
0.00s - make the debugger miss breakpoints. Please pass -Xfrozen_modules=off
0.00s - to python to disable frozen modules.
0.00s - Note: Debugging will proceed. Set PYDEVD_DISABLE_FILE_VALIDATION=1 to disable this validation.
Available kernels:
unsloth_env /root/.local/share/jupyter/kernels/unsloth_env
python3 /root/anaconda3/share/jupyter/kernels/python3
# 启动jupyter,默认监听在<server-ip>:8888上
jupyter notebook --ip=<server-ip> --allow-root
加载模型
# 加载模型
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/llama-3-8b-bnb-4bit", # HuggingFace上的模型路径,HuggingFace上unsloth也提供基础的instruct量化4位模型,要使用替换相应路径即可
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
微调前测试
# 微调前测试
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}""" # 定义prompt结构
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"请使用中文回答问题", # instruction
"海绵宝宝的书法是不是叫做海绵体?", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer # TextStreamer可以实时输出
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
准备微调数据集
# 准备微调数据集
EOS_TOKEN = tokenizer.eos_token # 必须添加EOS_TOKEN,是一个特殊标记,用于表示句子或序列的结束
def formatting_prompts_func(examples):
# 跟数据集的格式结构一致
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# 必须添加EOS_TOKEN, 否则无限生成
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts}
from datasets import load_dataset
# 选用中文数据集,内容来自于百度贴吧-弱智吧
dataset = load_dataset("kigner/ruozhiba-llama3", split = "train") # 从HuggingFace上下载数据集,也支持加载本地的数据集
dataset = dataset.map(formatting_prompts_func, batched = True)
设置微调参数
# 设置微调参数,微调方法选择LoRA
model = FastLanguageModel.get_peft_model(
model,
r = 16, # 建议8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # 梯度检查点,True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, #
)
from trl import SFTTrainer
from transformers import TrainingArguments
# 使用SFT微调,unsloth支持SFT、DPO微调
# 更多详细介绍: https://huggingface.co/docs/trl/main/en/index
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text", # 跟数据集定义的map函数formatting_prompts_func返回的key一致
max_seq_length = max_seq_length,
dataset_num_proc = 2,
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
per_device_train_batch_size = 2, # 控制训练的批量大小
gradient_accumulation_steps = 4, # 梯度累积技术通过分割数据为更小的子批量来实现模拟大批量训练的效果。如果将per_device_train_batch_size设为4且gradient_accumulation_steps设为2,则最终的总批量大小实际上是8(4乘以2)
warmup_steps = 5, # 是针对学习率learning rate优化的一种策略,在训练初期使用较小的学习率(从0开始),在一定步数(比如1000步)内逐渐提高到正常大小(设置的learning_rate),避免模型过早进入局部最优而过拟合;在训练后期再慢慢将学习率降低到 0,避免后期训练还出现较大的参数变化
max_steps = 60, # 微调步数,影响微调后模型的输出质量,-1为无限制,根据数据集大小来
learning_rate = 2e-4, # 学习率是决定模型在训练期间如何更新其权重的关键超参数。
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(), # bfloat16的设计允许处理更广泛的数值范围,而不会显著牺牲计算精度
logging_steps = 1,
optim = "adamw_8bit", # 优化器的作用在于引导模型训练过程,通过最小化误差或提升准确性来进行微调。8位分页AdamW与LoRA可以显著降低AdamW的总内存消耗
weight_decay = 0.01, # 权重衰减是一种鼓励模型维持较小权重值的技术,通过这种方式实现对模型的正则化,以避免复杂度过高的模型。有助于模型不过分依赖于任何单一的输入特征
lr_scheduler_type = "linear", # 最常用的还是线性两段式调整学习率
seed = 3407,
output_dir = "outputs", # 模型训练的输出目录
),
)
开始训练模型
# 开始训练
trainer_stats = trainer.train()
验证微调模型
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"请使用中文回答问题", # instruction
"海绵宝宝的书法是不是叫做海绵体?", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer # TextStreamer可以实时输出
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
保存微调模型
# 保存训练后的LoRA模型,并不是一个完整的模型
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
# model.push_to_hub("your_name/lora_model", token = "...") # Online saving,推送到HuggingFace上
# tokenizer.push_to_hub("your_name/lora_model", token = "...") # Online saving,推送到HuggingFace上
合并模型
合并模型是指将微调后的模型和原始模型进行合并,假设这里最终模型的保存格式为:4bit GGUF格式,其中经过的转换过程是:16bit HF格式 -> 16bit GGUF格式 -> 4bit GGUF格式
# 保存为HF格式,vLLM可加载使用
model.save_pretrained_merged("model", tokenizer, save_method = "merged_16bit",) # 也可选保存为其它精度格式,如4bit
# model.push_to_hub_merged("hf/model", tokenizer, save_method = "merged_16bit", token = "") # 是否推送到HuggingFace上
# 保存为4bit GGUF格式,HF格式到GGUF格式的转换是集成了llama.cpp来实现的
model.save_pretrained_gguf("model", tokenizer, quantization_method = "q4_k_m")
# model.push_to_hub_gguf("hf/model", tokenizer, quantization_method = "q4_k_m", token = "") 是否推送到HuggingFace上
如果遇到转换模型格式失败,需要重新编译下llama.cpp,然后再执行一遍程序
git clone https://github.com/ggerganov/llama.cpp
cd llama.cpp && make clean && LLAMA_CUDA=1 make all -j
# 如果编译失败,提示缺少c++,ubuntu的话需要装下build-essential包
apt install build-essential -y
本地加载GGUF模型验证
GGUG模型可使用gpt4all加载查看效果
 可以看到除了数据集中的返回回答外,模型还会衍生发散
可以看到除了数据集中的返回回答外,模型还会衍生发散
云端colab微调phi-3-mini-4k
参考youtube上的视频教程:https://www.youtube.com/watch?v=JIaWgRStuXA&t=9s
Colab是Google Cloud的一项托管式Jupyter笔记本服务,有免费额度提供使用,运行代码执行程序时请修改运行时类型为T4 GPU. phi-3-mini是微软开源的3.8B个参数的小模型,提供两个版本:4k和128k token的上下文长度。
安装微调库
%%capture
# Installs Unsloth, Xformers (Flash Attention) and all other packages!
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
!pip install --no-deps "xformers<0.0.26" trl peft accelerate bitsandbytes
%%capture是Colab的Magic命令,用来阻止特定单元格的输出;!符号后面可以接shell命令
加载模型
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "microsoft/Phi-3-mini-4k-instruct",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
微调前测试
# 微调前测试
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}""" # 定义prompt结构
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"请使用中文回答问题", # instruction
"海绵宝宝的书法是不是叫做海绵体?", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda") # tokenizer可以返回实际输入到模型的张量(tensor),张量实际上是多维数组,pt是PyTorch,tf是TensorFlow
from transformers import TextStreamer # TextStreamer可以实时输出
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
准备微调数据集
#准备微调数据集
EOS_TOKEN = tokenizer.eos_token # 必须添加EOS_TOKEN,是一个特殊标记,用于表示句子或序列的结束
# 这个实际上是个数据预处理函数
def formatting_prompts_func(examples):
# 跟数据集的格式结构一致
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# 必须添加EOS_TOKEN, 否则无限生成
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts, }
from datasets import load_dataset
# 选用中文数据集,内容来自于百度贴吧-弱智吧
dataset = load_dataset("kigner/ruozhiba-llama3", split = "train") # 从HuggingFace上下载数据集,也支持加载本地的数据集
dataset = dataset.map(formatting_prompts_func, batched = True)
自定义数据格式:多项选择数据集
# 多项选择题数据集
dataset = load_dataset("TheFinAI/flare-zh-fineval", split="test")
dataset = dataset.remove_columns(["text", "id", "choices", "answer"])
# 微调前测试
alpaca_prompt = """The following is a multiple-choice question, and the correct answer will be returned according to the requirements; ### Instruction: Below is the specific requirement, ### Input: Below is the specific question, with four options; ### Response: Below is the correct answer, please Return ### Response: The answer below.
### Instruction:
{}
### Input:
{}
### Response:
{}""" # 定义prompt结构
EOS_TOKEN = tokenizer.eos_token
inputs = tokenizer(
[
alpaca_prompt.format(
'对于以下填空题,请从下面选项中选择一个正确的答案。你的答案应该为:"A"、"B"、"C"或 "D"', # instruction
"Context:下列各项税法原则中,属于税法基本原则核心的是____。\nA,税收公平原则\nB,税收效率原则\nC,实质课税原则\nD,税收法定原则", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer # TextStreamer可以实时输出
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
# 数据预处理函数
def formatting_prompts_func(examples):
# 跟数据集的格式结构一致
golds = examples["gold"]
queries = examples["query"]
texts = []
for gold, query in zip(golds, queries):
query_without_unused_str = query.split("Answer:")[0]
context_list = query_without_unused_str.split("\n")
instruction = context_list[0]
input = "\n".join(context_list[1:])
output = context_list[gold+2]
# 必须添加EOS_TOKEN, 否则无限生成
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts}
设置微调参数
# 设置微调参数,微调方法选择LoRA
model = FastLanguageModel.get_peft_model(
model,
r = 16, # 建议8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # 梯度检查点,True or "unsloth" for very long context
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # LoftQ是一种针对大型语言模型(LLMs)的量化框架,主要作用是减少大型预训练模型的存储和计算资源需求
)
from trl import SFTTrainer
from transformers import TrainingArguments
# 使用SFT微调,unsloth支持SFT、DPO微调
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
dataset_text_field = "text", # 跟数据集定义的map函数formatting_prompts_func返回的key一致
max_seq_length = max_seq_length,
dataset_num_proc = 2, # 用于tokenize数据集的worker数量,packing=False时生效
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
# num_train_epochs=3, 训练的总轮数
per_device_train_batch_size = 2, # 控制训练的批量大小
gradient_accumulation_steps = 4, # 梯度累积技术通过分割数据为更小的子批量来实现模拟大批量训练的效果。如果将per_device_train_batch_size设为4且gradient_accumulation_steps设为2,则最终的总批量大小实际上是8(4乘以2)
warmup_steps = 5, # 是针对学习率learning rate优化的一种策略,在训练初期使用较小的学习率(从0开始),在一定步数(比如1000步)内逐渐提高到正常大小(设置的learning_rate),避免模型过早进入局部最优而过拟合;在训练后期再慢慢将学习率降低到 0,避免后期训练还出现较大的参数变化
max_steps = 60, # 微调步数,影响微调后模型的输出质量,-1为无限制,根据数据集大小来
learning_rate = 2e-4, # 学习率是决定模型在训练期间如何更新其权重的关键超参数。
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(), # bfloat16的设计允许处理更广泛的数值范围,而不会显著牺牲计算精度
logging_steps = 1,
optim = "adamw_8bit", # 优化器的作用在于引导模型训练过程,通过最小化误差或提升准确性来进行微调。8位分页AdamW与LoRA可以显著降低AdamW的总内存消耗
weight_decay = 0.01, # 权重衰减是一种鼓励模型维持较小权重值的技术,通过这种方式实现对模型的正则化,以避免复杂度过高的模型。有助于模型不过分依赖于任何单一的输入特征
lr_scheduler_type = "linear", # 最常用的还是线性两段式调整学习率
seed = 3407, # 设置随机数生成器的种子,以确保实验的可重复性子,为了确保结果的可重复性,在每次训练中使用相同的种子值,具体值并不重要
output_dir = "outputs", # 模型训练的输出目录
),
)
开始训练模型
tokenizer.padding_side = 'right'
trainer_stats = trainer.train()
输出类似这种格式的数据,如果出现grad_norm为nan,说明在计算梯度范数时出现了数值问题
{'loss': 0.8567, 'grad_norm': 0.5789440870285034, 'learning_rate': 0.0001039568345323741, 'epoch': 1.45}
验证微调模型
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"请使用中文回答问题", # instruction
"海绵宝宝的书法是不是叫做海绵体?", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer # TextStreamer可以实时输出
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
保存微调模型
# 保存训练后的LoRA模型,并不是一个完整的模型
model.save_pretrained("phi-3-mini-lora-model") # Local saving
tokenizer.save_pretrained("phi-3-mini-lora-model")
合并模型
# 保存为HF格式,vLLM可加载使用
model.save_pretrained_merged("phi-3-mini-model/", tokenizer, save_method = "merged_16bit",) # 也可选保存为其它精度格式,如4bit
# 保存为16bit GGUF格式
model.save_pretrained_gguf("phi-3-mini-model/", tokenizer, quantization_method = "f16")
# 保存为4bit GGUF格式,HF格式到GGUF格式的转换是集成了llama.cpp来实现的
model.save_pretrained_gguf("phi-3-mini-model/", tokenizer, quantization_method = "q4_k_m")
在colab上使用llama.cpp转换格式一直未成功……,不确定是不是colab终端环境问题
手动执行模型转换和量化步骤
python llama.cpp/convert-hf-to-gguf.py --outfile phi-3-mini-4k-unsloth.fp16.gguf --outtype f16 phi-3-mini-model/
./llama.cpp/quantize phi-3-mini-4k-unsloth.fp16.gguf phi-3-mini-4k-unsloth.Q4_K_M.gguf Q4_K_M
本地加载GGUF模型验证
GGUG模型使用gpt4all加载查看效果
LLaMA-Factory微调
Transformers Trainer微调
加载模型
from transformers import AutoModelForCausalLM, BitsAndBytesConfig
# bitsandbytes集成支持8bit和4bit精度数据类型,用于加载大模型可以节省内存
quantization_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained("microsoft/Phi-3-mini-4k-instruct",
trust_remote_code=True,
device_map="auto",
quantization_config=quantization_config, torch_dtype=None)
load_in_4bit应用4位动态量化来极大地减少资源需求,也支持load_in_8bit
from transformers import AutoTokenizer
# 初始化分词器
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
微调前测试
# 微调前测试
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}""" # 定义prompt结构
tokenizer.pad_token = tokenizer.eos_token # 大多数模型默认没设置pad token
inputs = tokenizer(
[
alpaca_prompt.format(
"请使用中文回答问题", # instruction
"海绵宝宝的书法是不是叫做海绵体?", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt", padding=True, truncation=True).to("cuda") # tokenizer可以返回实际输入到模型的张量(tensor),张量实际上是多维数组,pt是PyTorch,tf是TensorFlow
from transformers import TextStreamer # TextStreamer可以实时输出
text_streamer = TextStreamer(tokenizer)
generated_ids = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
通过tokenizer decode可以看到模型输出的文本内容
tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
加载PEFT adapter
ValueError: You cannot perform fine-tuning on purely quantized models. Please attach trainable adapters on top of the quantized model to correctly perform fine-tuning. Please see: https://huggingface.co/docs/transformers/peft for more details
上面这段英文的意思是:对一个完全量化的模型进行微调,这是不被支持的。量化模型的参数是固定的,无法直接训练。因此,必须在量化模型上附加可训练的适配器(adapters),这样才可以进行微调。这里推荐一种参数高效微调方法(PEFT),在微调过程中冻结预训练模型的参数,并在其顶部添加少量可训练参数(adapters)。adapters被训练以学习特定任务的信息。这种方法已被证明非常节省内存,同时具有较低的计算使用量,同时产生与完全微调模型相当的结果。
from peft import LoraConfig
lora_config = LoraConfig(
r = 16, # 建议8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16,
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
model.add_adapter(lora_config, adapter_name="adapter_1")
准备微调数据集
#准备微调数据集
EOS_TOKEN = tokenizer.eos_token # 必须添加EOS_TOKEN,是一个特殊标记,用于表示句子或序列的结束
# 这个实际上是个数据预处理函数
def formatting_prompts_func(examples):
# 跟数据集的格式结构一致
instructions = examples["instruction"]
inputs = examples["input"]
outputs = examples["output"]
texts = []
for instruction, input, output in zip(instructions, inputs, outputs):
# 必须添加EOS_TOKEN, 否则无限生成
text = alpaca_prompt.format(instruction, input, output) + EOS_TOKEN
texts.append(text)
return { "text" : texts}
from datasets import load_dataset
# 选用中文数据集,内容来自于百度贴吧-弱智吧
dataset = load_dataset("kigner/ruozhiba-llama3", split = "train") # 从HuggingFace上下载数据集,也支持加载本地的数据集
dataset = dataset.map(formatting_prompts_func, batched = True)
设置微调参数
from trl import SFTTrainer
from transformers import TrainingArguments
import torch
tokenizer.padding_side = 'right'
# 使用SFT Trainer,还有DPO、KTO、CPO、ORPO、Reward、PPO等其它Trainer. 想要使用自回归技术在文本数据集上微调像Llama、Mistral这样的语言模型,考虑使用trl的SFTTrainer
trainer = SFTTrainer(
model = model,
tokenizer = tokenizer,
train_dataset = dataset,
max_seq_length = 2048,
dataset_text_field = "text", # 跟数据集定义的map函数formatting_prompts_func返回的key一致
dataset_num_proc = 2, # 用于tokenize数据集的worker数量,packing=False时生效
packing = False, # Can make training 5x faster for short sequences.
args = TrainingArguments(
# num_train_epochs=3, 训练的总轮数
per_device_train_batch_size = 2, # 控制训练的批量大小
gradient_accumulation_steps = 4, # 梯度累积技术通过分割数据为更小的子批量来实现模拟大批量训练的效果。如果将per_device_train_batch_size设为4且gradient_accumulation_steps设为2,则最终的总批量大小实际上是8(4乘以2)
warmup_steps = 5, # 是针对学习率learning rate优化的一种策略,在训练初期使用较小的学习率(从0开始),在一定步数(比如1000步)内逐渐提高到正常大小(设置的learning_rate),避免模型过早进入局部最优而过拟合;在训练后期再慢慢将学习率降低到 0,避免后期训练还出现较大的参数变化
max_steps = -1, # 微调步数,影响微调后模型的输出质量,-1为无限制,根据数据集大小来
learning_rate = 2e-4, # 学习率是决定模型在训练期间如何更新其权重的关键超参数。
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(), # bfloat16的设计允许处理更广泛的数值范围,而不会显著牺牲计算精度
logging_steps = 1,
optim = "adamw_8bit", # 优化器的作用在于引导模型训练过程,通过最小化误差或提升准确性来进行微调。8位分页AdamW与LoRA可以显著降低AdamW的总内存消耗
weight_decay = 0.01, # 权重衰减是一种鼓励模型维持较小权重值的技术,通过这种方式实现对模型的正则化,以避免复杂度过高的模型。有助于模型不过分依赖于任何单一的输入特征
lr_scheduler_type = "linear", # 最常用的还是线性两段式调整学习率
seed = 3407, # 设置随机数生成器的种子,以确保实验的可重复性子,为了确保结果的可重复性,在每次训练中使用相同的种子值,具体值并不重要
output_dir = "outputs", # 模型训练的输出目录
),
)
开始训练模型
trainer_stats = trainer.train()
验证微调模型
inputs = tokenizer(
[
alpaca_prompt.format(
"请使用中文回答问题", # instruction
"海绵宝宝的书法是不是叫做海绵体?", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
from transformers import TextStreamer # TextStreamer可以实时输出
text_streamer = TextStreamer(tokenizer)
_ = model.generate(**inputs, streamer = text_streamer, max_new_tokens = 128)
保存微调模型
model.save_pretrained("lora_model") # Local saving
tokenizer.save_pretrained("lora_model")
合并模型
# 合并LoRa模型和基础模型
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel, LoraConfig
tokenizer = AutoTokenizer.from_pretrained("lora_model/")
base_model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
#torch_dtype=torch.bfloat16,
device_map="auto",
trust_remote_code=True
)
# 这里有个小问题:上面跑微调设置loftq_config为None,待会合并的时候会报错,故这里特殊处理了下
lora_config = LoraConfig.from_pretrained("lora_model/")
if lora_config.loftq_config is None:
lora_config.loftq_config = {}
lora_model = PeftModel.from_pretrained(
base_model,
"lora_model/",
#torch_dtype=torch.bfloat16,
config=lora_config
)
print("Applying the LoRA")
model = lora_model.merge_and_unload()
print(f"Saving the target model to phi-3-mini-4k-with-lora")
# 保存为HF格式
model.save_pretrained("phi-3-mini-4k-with-lora")
tokenizer.save_pretrained("phi-3-mini-4k-with-lora")
# 使用llama.cpp转换格式,HF格式转化为16bit GGUF格式
python llama.cpp/convert-hf-to-gguf.py --outfile phi-3-mini-4k-lora.fp16.gguf --outtype f16 phi-3-mini-4k-with-lora/
# 量化为4bit GGUF格式
./llama.cpp/quantize phi-3-mini-4k-lora.fp16.gguf phi-3-mini-4k-lora.Q4_K_M.gguf Q4_K_M
GRPO强化学习微调
https://docs.unsloth.ai/basics/reasoning-grpo-and-rl
按照DeepSeek R1论文描述,将R1的推理能力蒸馏到小型模型中,比直接在这些小型模型上应用强化学习效果会更好
分布式训练工具
Accelerate
DeepSpeed
LLM大模型API第三方库
- https://github.com/BerriAI/litellm:兼容OpenAI格式的统一大模型API,大多支持国外的模型
- https://github.com/songquanpeng/one-api:兼容OpenAI格式的统一大模型API,大多支持国内的模型
使用LangChain开发应用程序
官网提供了一个ChatGPT风格的LangChain帮助文档搜索:https://chat.langchain.com/
LangChain Hub: https://smith.langchain.com/hub, 一个用于管理和共享LLM 提示词(Prompt)的在线平台
简介Introduction
LangChain是一套专为LLM开发打造的开源框架,实现了LLM多种强大能力的利用,提供了Chain、Agent、Tool等多种封装工具, 基于LangChain可以便捷开发应用程序,极大化发挥LLM潜能。目前使用LangChin已经成为LLM开发的必备能力之一。
模型、提示和输出解释器Models,Prompts,Parsers
LLM开发的一些重要概念:模型、提示和解释器
直接调用OpenAI
计算1+1
直接通过OpenAl接口封装的函数CreateChatCompletion让模型回答:1+1是什么?
func main() {
prompt := `
1+1是什么?
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), prompt)
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
}
输出:
1+1等于2。
用普通话表达海盗邮件
现在用一个更为丰富、复杂的场景,假如你是一家电商公司的员工,客户中有一位名为海盗A的特殊顾客。他在你们的平台上购买了一个榨汁机,目的是为了制作美味的奶昔。但在制作过程中, 由于某种原因,奶昔的盖子突然弹开,导致厨房的墙上洒满了奶昔。想象一下这名海盗的愤怒和挫败之情。用充满愤怒的英语方言,给客服中心写了一封邮件
为了解决这一挑战,我们设定了以下两个目标:
- 首先,我们希望模型能够将这封充满海盗方言的邮件翻译成普通话,这样客服团队就能更容易地理解其内容。
- 其次,在进行翻译时,我们期望模型能采用平和和尊重的语气,这不仅能确保信息准确传达,还能保持与顾客之间的和谐关系。
为了让引导模型的输出,定义了一个文本表达风格标签style
func main() {
text := `
嗯呐,我现在可是火冒三丈,我那个搅拌机盖子竟然飞了出去,把我厨房的墙壁都溅上了果汁!
更糟糕的是,保修条款可不包括清理我厨房的费用。
伙计,赶紧给我过来!
`
style := "正式普通话,用一个平静、尊敬、有礼貌的语调"
prompt := `
把下面由两个双引号分隔的文本翻译成一种"%s"风格。
文本:"%s"
`
client := newOpenAIClient()
resp, err := client.CreateChatCompletion(context.TODO(), fmt.Sprintf(prompt, style, text))
if err != nil {
fmt.Printf("ChatCompletion error: %v\n", err)
return
}
res := resp.Choices[0].Message.Content
fmt.Println(res)
}
输出:
尊敬的先生/小姐,我现在实在感到非常生气,因为我的搅拌机盖子竟然飞了出去,将我厨房的墙壁溅上果汁!
更糟糕的是,保修条款并不包括清理厨房的费用。请您尽快前来帮我解决这个问题!感谢您的合作。
进行语言风格转换之后,可以看到明显的语气变化。
通过LangChain使用OpenAI
上面的例子通过调用OpenAI接口成功地对邮件内容进行了风格转换,接下来使用LangChain来实现同样的效果。
模型
从LangChain库导入OpenAI的对话模型ChatOpenAI,LangChain官网还集成了众多其它对话模型:https://python.langchain.com/docs/integrations/chat/
# pip3 install langchain
# pip3 list |grep langchain
langchain 0.1.11
langchain-community 0.0.27
langchain-core 0.1.30
langchain-openai 0.0.7
langchain-text-splitters 0.0.1
这里安装的LangChain的版本是0.1.11
from langchain_openai.chat_models import ChatOpenAI
api_key = "*******************"
openai_proxy = "https://api.***.com.cn/v1"
def main():
chat =ChatOpenAI(
temperature=0.0,
api_key=api_key,
openai_proxy=openai_proxy)
print(chat)
if __name__ == "__main__":
main()
输出:
client=<openai.resources.chat.completions.Completions object at 0x10aee9af0> async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x10aeeb0b0> temperature=0.0 openai_api_key=SecretStr('**********') openai_proxy='https://api.chatanywhere.com.cn/v1'
使用提示模版
LangChain提供了接口,方便更快速的构造和使用提示。
1.用普通话表达海盗邮件
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
api_key = "*******************"
openai_proxy = "https://api.***.com.cn/v1"
def main():
customer_style = """正式普通话 \
用一个平静、尊敬的语气
"""
customer_email = """
嗯呐,我现在可是火冒三丈,我那个搅拌机盖子竟然飞了出去,把我厨房的墙壁都溅上了果汁!
更糟糕的是,保修条款可不包括清理我厨房的费用。
伙计,赶紧给我过来!
"""
template_string = """把由三个反引号分隔的文本\
翻译成一种{my_style}风格。\
文本: ```{my_text}```
"""
# 使用提示模版,可以定义消息格式
prompt_template = ChatPromptTemplate.from_template(template_string)
customer_messages = prompt_template.format_messages(
my_style = customer_style,
my_text = customer_email
)
# 打印客户消息类型
print("客户消息类型:",type(customer_messages),"\n")
# 打印第一个客户消息类型
print("第一个客户消息类型:", type(customer_messages[0]),"\n")
# 打印第一个元素
print("第一个客户消息: ", customer_messages[0],"\n")
if __name__ == "__main__":
main()
输出:
客户消息类型: <class 'list'>
第一个客户消息类型: <class 'langchain_core.messages.human.HumanMessage'>
第一个客户消息: content='把由三个反引号分隔的文本翻译成一种正式普通话 用一个平静、尊敬的语气\n风格。文本: ```\n 嗯呐,我现在可是火冒三丈,我那个搅拌机盖子竟然飞了出去,把我厨房的墙壁都溅上了果汁!\n更糟糕的是,保修条款可不包括清理我厨房的费用。\n伙计,赶紧给我过来!\n```\n'
上面的消息格式看起来还不太友好,使用ChatOpenAI模型来转化消息格式
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
api_key = "******"
openai_url = "https://api.***.com.cn/v1"
def main():
customer_style = """正式普通话 \
用一个平静、尊敬的语气
"""
customer_email = """
嗯呐,我现在可是火冒三丈,我那个搅拌机盖子竟然飞了出去,把我厨房的墙壁都溅上了果汁!
更糟糕的是,保修条款可不包括清理我厨房的费用。
伙计,赶紧给我过来!
"""
template_string = """把由三个反引号分隔的文本\
翻译成一种{my_style}风格。\
文本: ```{my_text}```
"""
# 使用提示模版
prompt_template = ChatPromptTemplate.from_template(template_string)
customer_messages = prompt_template.format_messages(
my_style = customer_style,
my_text = customer_email
)
chat = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url
)
# 强制转换类型
openai_messages = chat(customer_messages)
print(openai_messages.content)
if __name__ == "__main__":
main()
输出:
您好,我现在感到非常愤怒,我的搅拌机盖子竟然飞了出去,把我厨房的墙壁都溅上了果汁!更糟糕的是,保修条款并不包括清理我厨房的费用。朋友,请赶紧过来帮帮我!感激不尽。
2.用海盗方言回复邮件
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
api_key = "******"
openai_url = "https://api.***.com.cn/v1"
def main():
service_style = """一个有礼貌的语气 \
使用海盗风格
"""
service_response = """嘿,顾客, \
保修不包括厨房的清洁费用, \
因为您在启动搅拌机之前 \
忘记盖上盖子而误用搅拌机, \
这是您的错。 \
倒霉! 再见!
"""
template_string = """把由三个反引号分隔的文本\
翻译成一种{my_style}风格。\
文本: ```{my_text}```
"""
# 使用提示模版
prompt_template = ChatPromptTemplate.from_template(template_string)
customer_messages = prompt_template.format_messages(
my_style = service_style,
my_text = service_response
)
chat = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url
)
openai_messages = chat.invoke(customer_messages)
print(openai_messages.content)
if __name__ == "__main__":
main()
输出:
啊哟,尊贵的客人,抱歉地通知您,保修不包括厨房的清洁费用。因为您在启动搅拌机之前忘记盖上盖子而误用搅拌机,这可是您的疏忽啊。真是倒霉!祝您一天愉快,再见!愿您的航程一帆风顺!Yo-ho-ho!
3.为什么需要提示模版
使用提示模版,可以让我们更为方便地重复使用设计好的提示。LangChain还提供了提示模版用于一些常用场景。比如自动摘要、问答、连接到SQL数据库、连接到不同的API。
输出解释器
1.不使用输出解释器提取客户评价中的信息
给定的评价customer_review,从中提取信息,按以下格式输出:
{
"礼物": 是的,
"交货天数": 5,
"价钱": "很贵"
}
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
api_key = "******"
openai_url = "https://api.***.com.cn/v1"
def main():
customer_review = """\
这款吹叶机非常神奇。 它有四个设置:\
吹蜡烛、微风、风城、龙卷风。 \
两天后就到了,正好赶上我妻子的\
周年纪念礼物。 \
我想我的妻子会喜欢它到说不出话来。 \
到目前为止,我是唯一一个使用它的人,而且我一直\
每隔一天早上用它来清理草坪上的叶子。 \
它比其他吹叶机稍微贵一点,\
但我认为它的额外功能是值得的。
"""
template_string = """\
对于以下文本,请从中提取以下信息:
礼物:该商品是作为礼物送给别人的吗? \
如果是,则回答 是的;如果否或未知,则回答 不是。
交货天数:产品需要多少天\
到达? 如果没有找到该信息,则输出-1。
价钱:提取有关价值或价格的任何句子,\
并将它们输出为逗号分隔的 Python 列表。
使用以下键将输出格式化为 JSON:
礼物
交货天数
价钱
文本: {my_text}
"""
# 使用提示模版
prompt_template = ChatPromptTemplate.from_template(template_string)
customer_messages = prompt_template.format_messages(
my_text = customer_review
)
chat = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url
)
openai_messages = chat.invoke(customer_messages)
print("结果类型:", type(openai_messages.content))
print("结果:", openai_messages.content)
if __name__ == "__main__":
main()
输出:
结果类型: <class 'str'>
结果: {
"礼物": "是的",
"交货天数": 2,
"价钱": ["它比其他吹叶机稍微贵一点"]
}
返回的结果类型是字符串,想方便提取信息的话,还是要使用LangChain中的输出解释器。
2.使用输出解释器提取客户评价中的信息
使用LangChain的输出解释器
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.output_parsers import ResponseSchema, StructuredOutputParser
api_key = "******"
openai_url = "https://api.***.com.cn/v1"
def main():
customer_review = """\
这款吹叶机非常神奇。 它有四个设置:\
吹蜡烛、微风、风城、龙卷风。 \
两天后就到了,正好赶上我妻子的\
周年纪念礼物。 \
我想我的妻子会喜欢它到说不出话来。 \
到目前为止,我是唯一一个使用它的人,而且我一直\
每隔一天早上用它来清理草坪上的叶子。 \
它比其他吹叶机稍微贵一点,\
但我认为它的额外功能是值得的。
"""
template_string = """\
对于以下文本,请从中提取以下信息:
礼物:该商品是作为礼物送给别人的吗?
如果是,则回答 是的;如果否或未知,则回答 不是。
交货天数:产品到达需要多少天? 如果没有找到该信息,则输出-1。
价钱:提取有关价值或价格的任何句子,并将它们输出为逗号分隔的Python列表。
文本: {my_text}
{format_instructions}
"""
# 使用提示模版
prompt_template = ChatPromptTemplate.from_template(template_string)
# 使用输出解释器
gift_schema = ResponseSchema(name="礼物", description="这件物品是作为礼物送给别人的吗?\
如果是,则回答 是的,\
如果否或未知,则回答 不是。")
delivery_days_schema = ResponseSchema(name="交货天数",
description="产品需要多少天才能到达?\
如果没有找到该信息,则输出-1。")
price_value_schema = ResponseSchema(name="价钱",
description="提取有关价值或价格的任何句子,\
并将它们输出为逗号分隔的Python列表")
response_schemas = [gift_schema, delivery_days_schema, price_value_schema]
output_parser = StructuredOutputParser.from_response_schemas(response_schemas)
format_instructions = output_parser.get_format_instructions()
customer_messages = prompt_template.format_messages(
my_text=customer_review,
format_instructions=format_instructions
)
chat = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url
)
openai_messages = chat(customer_messages)
output_dict = output_parser.parse(openai_messages.content)
print("结果类型:", type(output_dict))
print("结果:", output_dict)
if __name__ == "__main__":
main()
输出:
结果类型: <class 'dict'>
结果: {'礼物': '是的', '交货天数': '两天后', '价钱': '它比其他吹叶机稍微贵一点'}
从输出结果来看,结果类型类型为字典dict,操作dict数据结构更方便提取数据
记忆Memory
使用LangChain中的记忆模块,将先前的对话嵌入到语言模型中,使其具有连续对话的能力。 使用LangChain中的记忆(Memory)模块时,它旨在保存、组织和跟踪整个对话的历史,从而为用户和模型之间的交互提供连续的上下文。
这里主要介绍常用的四种记忆模块,其他模块可以查阅文档
- 对话缓存记忆(ConversationBufferMemory)
- 对话缓存窗口记忆(ConversationBufferWindowMemory)
- 对话令牌缓存记忆(ConversationTokenBufferMemory)
- 对话摘要缓存记忆(ConversationSummaryBufferMemory)
在LangChain中,记忆指的是大语言模型的短期记忆。为什么称为短期记忆?因为当用户与训练好的LLM进行对话时,LLM会暂时记住用户的输入和它已经生成的输出,以便预测之后的输出,而模型输出完毕后,它便会“遗忘”之前用户的输入和它的输出。
如果想延长LLM短期记忆的保留时间,需要借助一些外部记忆方式来进行记忆,以便能够知道历史对话信息。
对话缓存记忆
初始化对话模型
初始化对话模型,并进行多轮对话
from langchain_openai.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
api_key = "******"
openai_url = "https://api.***.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
memory = ConversationBufferMemory()
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
conversation.predict(input="你好,我叫特特鲁斯")
conversation.predict(input="1+1等于多少?")
conversation.predict(input="我叫什么名字?")
conversation.predict(input="")
if __name__ == "__main__":
main()
输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我叫特特鲁斯
AI: 你好,特特鲁斯!很高兴认识你。我是一个人工智能程序,可以回答你的问题或者和你聊天。你有什么想知道的吗?
Human: 我叫什么名字
AI: 你叫特特鲁斯。很特别的名字!你知道吗,特特鲁斯这个名字在拉丁语中意味着“勇敢的战士”。很有力量的名字呢!有什么其他问题想问我吗?
Human: 1+1等于多少
AI: 1加1等于2。这是一个非常简单的数学问题,答案是2。如果你有其他数学问题或者其他想知道的事情,都可以问我哦!我会尽力回答你的。
Human:
AI:
使用predict进行预测时,LangChain会生成一些提示,使系统进行友好的对话
查看记忆缓存
# memory.buffer_as_messages记忆了当前为止所有 的对话信息
print(memory.buffer_as_messages)
# load_memory_variables也可以打印缓存中的历史消息
print(memory.load_memory_variables({}))
输出
[HumanMessage(content='你好,我叫特特鲁斯'), AIMessage(content=' 你好,特特鲁斯!很高兴认识你。我是一个人工智能助手,可以回答你的问题或者和你聊天。有什么我可以帮助你的吗?'), HumanMessage(content='我叫什么名字'), AIMessage(content='抱歉,我不知道你的名字。你可以告诉我吗?'), HumanMessage(content='1+1等于多少'), AIMessage(content='1加1等于2。您还有其他问题吗?'), HumanMessage(content=''), AIMessage(content='如果您有任何其他问题或者想要聊天,随时告诉我哦!我随时准备好帮助您。')]
{'history': 'Human: 你好,我叫特特鲁斯\nAI: 你好,特特鲁斯!我是一个AI助手,很高兴认识你。你有什么问题或者想要聊什么吗?\nHuman: 我叫什么名字\nAI: 你叫特特鲁斯。特特鲁斯是一个很独特的名字,听起来很有个性。你喜欢这个名字吗?如果你有任何其他问题或者想要聊什么,随时告诉我哦!\nHuman: 1+1等于多少\nAI: 1加1等于2。这是一个非常基本的数学问题,答案是2。如果你有任何其他数学问题或者其他想要了解的知识,都可以问我哦!我会尽力帮助你。\nHuman: \nAI: 你有任何其他问题或者想要聊什么吗?我可以提供各种信息和帮助。'}
添加内容到记忆缓存
from langchain_openai.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
api_key = "******"
openai_url = "https://api.***.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
memory = ConversationBufferMemory()
memory.save_context({"input": "你好,我叫ice"}, {"output": "你好,我叫tracy"})
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
conversation.predict(input="你好,我叫特特鲁斯")
conversation.predict(input="1+1等于多少?")
conversation.predict(input="我叫什么名字?")
conversation.predict(input="")
print(memory.load_memory_variables({}))
if __name__ == "__main__":
main()
输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 你好,我叫ice
AI: 你好,我叫tracy
Human: 你好,我叫特特鲁斯
AI: 很高兴认识你,特特鲁斯!你有什么想要了解或者讨论的吗?
Human: 1+1等于多少?
AI: 1加1等于2。这是一个基本的数学问题,答案是2。您还有其他问题吗?
Human: 我叫什么名字?
AI: 您说您叫特特鲁斯。您的名字是特特鲁斯。有什么其他问题吗?
Human:
AI:
> Finished chain.
{'history': 'Human: 你好,我叫ice\nAI: 你好,我叫tracy\nHuman: 你好,我叫特特鲁斯\nAI: 很高兴认识你,特特鲁斯!你有什么想要了解或者讨论的吗?\nHuman: 1+1等于多少?\nAI: 1加1等于2。这是一个基本的数学问题,答案是2。您还有其他问题吗?\nHuman: 我叫什么名字?\nAI: 您说您叫特特鲁斯。您的名字是特特鲁斯。有什么其他问题吗?\nHuman: \nAI: 您有什么其他问题或者想要讨论的吗?我可以提供各种信息和帮助。'}
使用save_context添加内容到buffer中,然后通过memory.load_memory_variables({})打印对话历史。在使用大型语言模型进行聊天对话时,大型语言模型本身实际上是无状态的。语言模型本身并不记得到目前为止的历史对话。
对话缓存窗口记忆
对话随着时间积累会越来越长,内存也占用越来越多,这就需要大量的token发送到大模型。为了节约token,对话缓存窗口记忆可以设置大小限制
添加对话到窗口记忆
from langchain_openai.chat_models import ChatOpenAI
from langchain.memory import ConversationBufferWindowMemory
api_key = "xxxx"
openai_url = "https://api.xxx.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
memory = ConversationBufferWindowMemory(k=1)
memory.save_context({"input": "你好,我叫ice"}, {"output": "你好,我叫tracy"})
memory.save_context({"input": "你好,朋友"}, {"output": "你好,我们一起玩吧"})
print(memory.load_memory_variables({}))
if __name__ == "__main__":
main()
输出:
{'history': 'Human: 你好,朋友\nAI: 你好,我们一起玩吧'}
使用ConversationBufferWindowMemory来实现交互的滑动窗口,设置k=1只保留最近的一个对话记忆。
在对话链中应用窗口记忆
from langchain_openai.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferWindowMemory
api_key = "xxxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
memory = ConversationBufferWindowMemory(k=1)
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
conversation.predict(input="你好,我叫特特鲁斯")
conversation.predict(input="1+1等于多少?")
conversation.predict(input="我叫什么名字?")
conversation.predict(input="")
print(memory.load_memory_variables({}))
if __name__ == "__main__":
main()
输出:
> Entering new ConversationChain chain...
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: 我叫什么名字?
AI: 抱歉,我无法知道你的名字,因为我是一个人工智能程序,无法获取你的个人信息。如果你有其他问题或需要帮助,请随时告诉我。
Human:
AI:
> Finished chain.
{'history': 'Human: \nAI: 你好!有什么我可以帮助你的吗?'}
从输出结果来看,窗口记忆只能记住上一轮对话的信息
对话字符缓存记忆
使用对话字符缓存记忆,内存将限制保存的token数量
from langchain_openai.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationTokenBufferMemory
api_key = "sk-xxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
memory = ConversationTokenBufferMemory(llm=llm, max_token_limit=20)
memory.save_context({"input": "你好,我叫ice"}, {"output": "你好,我叫tracy"})
memory.save_context({"input": "你好,朋友"}, {"output": "你好,我们一起玩吧"})
print(memory.load_memory_variables({}))
if __name__ == "__main__":
main()
输出:
{'history': 'AI: 你好,我们一起玩吧'}
ChatGPT是使用了一种基于字节对编码(BPE)的方法来进行tokenization。BPE是一种常见的tokenization技术,将输入文本分割成较小的子词单元。OpenAl是用tiktoken这个库来计算token的,tiktoken在github上是开源的https://github.com/openai/tiktoken.关于汉子和英文单词的token计算方式,知乎上一篇文章讲解:https://www.zhihu.com/question/594159910
查询OpenAI的字符和token的映射关系:https://platform.openai.com/tokenizer
大模型中token和字数的换算比例大致如下:
- 1个英文字符 ≈ 0.3个token
- 1个中文字符 ≈ 0.6个token
对话摘要缓存记忆
对话摘要缓存记忆,使用LLM对到目前为止历史对话自动总结摘要
from langchain_openai.chat_models import ChatOpenAI
from langchain.memory import ConversationSummaryBufferMemory
api_key = "sk-xxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
schedule = "在八点你和你的产品团队有一个会议。 \
你需要做一个PPT。 \
上午9点到12点你需要忙于LangChain。\
Langchain是一个有用的工具,因此你的项目进展的非常快。\
中午,在意大利餐厅与一位开车来的顾客共进午餐 \
走了一个多小时的路程与你见面,只为了解最新的 AI。 \
确保你带了笔记本电脑可以展示最新的 LLM 样例."
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=20)
memory.save_context({"input": "你好,我叫ice"}, {"output": "你好,我叫tracy"})
memory.save_context({"input": "你好,朋友"}, {"output": "你好,我们一起玩吧"})
memory.save_context({"input": "今天的日程安排是什么?"}, {"output": f"{schedule}"})
print(memory.load_memory_variables({}))
if __name__ == "__main__":
main()
输出:
{'history': 'Human: 你好,我叫ice\nAI: 你好,我叫tracy\nHuman: 你好,朋友\nAI: 你好,我们一起玩吧\nHuman: 今天的日程安排是什么?\nAI: 在八点你和你的产品团队有一个会议。 你需要做一个PPT。 上午9点到12点你需要忙于LangChain。Langchain是一个有用的工具,因此你的项目进展的非常快。中午,在意大利餐厅与一位开车来的顾客共进午餐 走了一个多小时的路程与你见面,只为了解最新的 AI。 确保你带了笔记本电脑可以展示最新的 LLM 样例.'}
基于对话摘要缓存记忆的对话链
from langchain_openai.chat_models import ChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationSummaryBufferMemory
api_key = "sk-xxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
schedule = "在八点你和你的产品团队有一个会议。 \
你需要做一个PPT。 \
上午9点到12点你需要忙于LangChain。\
Langchain是一个有用的工具,因此你的项目进展的非常快。\
中午,在意大利餐厅与一位开车来的顾客共进午餐 \
走了一个多小时的路程与你见面,只为了解最新的 AI。 \
确保你带了笔记本电脑可以展示最新的 LLM 样例."
memory = ConversationSummaryBufferMemory(llm=llm, max_token_limit=1000)
memory.save_context({"input": "你好,我叫ice"}, {"output": "你好,我叫tracy"})
memory.save_context({"input": "你好,朋友"}, {"output": "你好,我们一起玩吧"})
memory.save_context({"input": "今天的日程安排是什么?"}, {"output": f"{schedule}"})
conversation = ConversationChain(llm=llm, memory=memory, verbose=True)
conversation.predict(input="展示什么样的样例最好呢")
print(memory.load_memory_variables({}))
if __name__ == "__main__":
main()
输出:
{'history': 'Human: 你好,我叫ice\nAI: 你好,我叫tracy\nHuman: 你好,朋友\nAI: 你好,我们一起玩吧\nHuman: 今天的日程安排是什么?\nAI: 在八点你和你的产品团队有一个会议。 你需要做一个PPT。 上午9点到12点你需要忙于LangChain。Langchain是一个有用的工具,因此你的项目进展的非常快。中午,在意大利餐厅与一位开车来的顾客共进午餐 走了一个多小时的路程与你见面,只为了解最新的 AI。 确保你带了笔记本电脑可以展示最新的 LLM 样例.\nHuman: 展示什么样的样例最好呢\nAI: 展示一些关于LangChain如何提高生产效率的案例会很有帮助。你可以展示一些实际的数据和结果,以及用户的反馈和体验。这样可以更直观地展示LangChain的价值和优势。希望这些建议对你有所帮助!'}
从输出结果来看,摘要内容更新了
回调Callbacks
LangChain提供回调机制,允许hook到大模型应用的各个阶段,通过订阅这些时间来触发回调函数。官方文档的回调章节介绍: https://python.langchain.com/docs/modules/callbacks/
回调处理
这里有个重要的概念回调处理,CallbackHandlers是实现该CallbackHandler接口的对象,该接口对于每个可以订阅的事件都有一个方法。CallbackManager当事件被触发时,将在每个处理程序上调用适当的方法。
class BaseCallbackHandler(
LLMManagerMixin,
ChainManagerMixin,
ToolManagerMixin,
RetrieverManagerMixin,
CallbackManagerMixin,
RunManagerMixin,
)
继承这么多类,展开的话相当于
class BaseCallbackHandler:
"""Base callback handler that can be used to handle callbacks from langchain."""
def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> Any:
"""Run when LLM starts running."""
def on_chat_model_start(
self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], **kwargs: Any
) -> Any:
"""Run when Chat Model starts running."""
def on_llm_new_token(self, token: str, **kwargs: Any) -> Any:
"""Run on new LLM token. Only available when streaming is enabled."""
def on_llm_end(self, response: LLMResult, **kwargs: Any) -> Any:
"""Run when LLM ends running."""
def on_llm_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when LLM errors."""
def on_chain_start(
self, serialized: Dict[str, Any], inputs: Dict[str, Any], **kwargs: Any
) -> Any:
"""Run when chain starts running."""
def on_chain_end(self, outputs: Dict[str, Any], **kwargs: Any) -> Any:
"""Run when chain ends running."""
def on_chain_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when chain errors."""
def on_tool_start(
self, serialized: Dict[str, Any], input_str: str, **kwargs: Any
) -> Any:
"""Run when tool starts running."""
def on_tool_end(self, output: Any, **kwargs: Any) -> Any:
"""Run when tool ends running."""
def on_tool_error(
self, error: Union[Exception, KeyboardInterrupt], **kwargs: Any
) -> Any:
"""Run when tool errors."""
def on_text(self, text: str, **kwargs: Any) -> Any:
"""Run on arbitrary text."""
def on_agent_action(self, action: AgentAction, **kwargs: Any) -> Any:
"""Run on agent action."""
def on_agent_finish(self, finish: AgentFinish, **kwargs: Any) -> Any:
"""Run on agent end."""
回调在哪里传递
callbacks在整个 API 中的大多数对象(链、模型、工具、代理等)上都可用,位于两个不同的位置:
- 构造函数回调:在构造函数中定义,例如LLMChain(callbacks=[handler], tags=[‘a-tag’])。在这种情况下,回调将用于对该对象进行的所有调用,并且仅限于该对象,例如,如果将处理程序传递给构造函数LLMChain,则附加到该链的模型将不会使用它。
- 请求回调:在用于发出请求的“invoke”方法中定义。在这种情况下,回调将仅用于该特定请求及其包含的所有子请求(例如,对LLMChain的调用会触发对模型的调用,模型使用在方法中传递的相同处理程序invoke())。在invoke()方法中回调是通过配置参数传递的。使用“调用”方法的示例(注意:相同的方法可用于batch、ainvoke和abatch方法。)
这两者有什么区别?
- 构造函数回调对于日志记录、监控等用例最有用,这些用例不特定于单个请求,而是特定于整个链。例如,如果您想记录对 发出的所有请LLMChain,您可以将处理程序传递给构造函数。
- 请求回调对于诸如流式传输之类的用例最有用,您希望将单个请求的输出流式传输到特定的Websocket连接,或其他类似的用例。例如,如果您想将单个请求的输出流式传输到 websocket,您可以将处理invoke()程序传递给该方法
一个异步回调的例子
from langchain_openai import ChatOpenAI
from langchain_core.messages import HumanMessage
from langchain_core.outputs import LLMResult
from langchain.callbacks.base import AsyncCallbackHandler, BaseCallbackHandler
from typing import Any, Dict, List
import asyncio
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
class MyCustomSyncHandler(BaseCallbackHandler):
def on_llm_new_token(self, token: str, **kwargs) -> None:
print(
f"Sync handler being called in a `thread_pool_executor`: token: {token}")
class MyCustomAsyncHandler(AsyncCallbackHandler):
"""Async callback handler that can be used to handle callbacks from langchain."""
async def on_llm_start(
self, serialized: Dict[str, Any], prompts: List[str], **kwargs: Any
) -> None:
"""Run when chain starts running."""
print("zzzz....")
await asyncio.sleep(0.3)
class_name = serialized["name"]
print("Hi! I just woke up. Your llm is starting")
async def on_llm_end(self, response: LLMResult, **kwargs: Any) -> None:
"""Run when chain ends running."""
print("zzzz....")
await asyncio.sleep(0.3)
print("Hi! I just woke up. Your llm is ending")
async def main():
# To enable streaming, we pass in `streaming=True` to the ChatModel constructor
# Additionally, we pass in a list with our custom handler
chat = ChatOpenAI(
max_tokens=30,
base_url=openai_url,
api_key=api_key,
streaming=True,
callbacks=[MyCustomSyncHandler(), MyCustomAsyncHandler()],
)
await chat.agenerate([[HumanMessage(content="Tell me a joke")]])
if __name__ == "__main__":
asyncio.run(main())
如果打算使用async API,建议使用AsyncCallbackHandler以避免阻塞runloop。这里 在使用异步方法运行LLM/链/工具/代理时使用同步,它仍然可以工作。如果这个同步的CallbackHandler是线程安全的, 那就没有问题。
输出:
zzzz....
Hi! I just woke up. Your llm is starting
Sync handler being called in a `thread_pool_executor`: token:
Sync handler being called in a `thread_pool_executor`: token: Why
Sync handler being called in a `thread_pool_executor`: token: couldn
Sync handler being called in a `thread_pool_executor`: token: 't
Sync handler being called in a `thread_pool_executor`: token: the
Sync handler being called in a `thread_pool_executor`: token: bicycle
Sync handler being called in a `thread_pool_executor`: token: stand
Sync handler being called in a `thread_pool_executor`: token: up
Sync handler being called in a `thread_pool_executor`: token: by
Sync handler being called in a `thread_pool_executor`: token: itself
Sync handler being called in a `thread_pool_executor`: token: ?
Sync handler being called in a `thread_pool_executor`: token: Because
Sync handler being called in a `thread_pool_executor`: token: it
Sync handler being called in a `thread_pool_executor`: token: was
Sync handler being called in a `thread_pool_executor`: token: two
Sync handler being called in a `thread_pool_executor`: token: tired
Sync handler being called in a `thread_pool_executor`: token: !
Sync handler being called in a `thread_pool_executor`: token:
zzzz....
Hi! I just woke up. Your llm is ending
模型链Chains
链是将大语言模型(LLM)和提示(Prompt)结合在一起,这样可以对文本进行一系列操作。使用链一个典型的流程:
- 创建一个链,链接受输入
- 使用提示模版对其格式化
- 将格式化的内容发送给LLM
可以把多个链组合在一起,或者链与其他组件组合形成一个更复杂的链。
大语言模型链
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain
api_key = "sk-xxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 1.初始化语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 2.初始化提示模版:接受一个名为product的变量。该prompt将要求LLM生成一个描述制造该产品的公司的最佳名称
prompt = ChatPromptTemplate.from_template("描述制造{product}该产品的公司的最佳名称是什么")
# 3.构建大语言模型链,链~=LLM+Prompt
chain = LLMChain(llm=llm, prompt=prompt)
# 4.运行大语言模型链
product = "大号床单套装"
print(chain.invoke(input={"product": product}).get('text'))
if __name__ == "__main__":
main()
输出:
"豪华床品有限公司"
简单顺序链
顾名思义顺序链是按定义顺序执行的链,简单顺序链是顺序链中的最简单类型,其中每个步骤都有一个输入/输出,一个步骤的输出是下一个步骤的输入。
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain, SimpleSequentialChain
api_key = "sk-xxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 1.初始化语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 2.初始化提示模版1:这个提示将接受产品并返回最佳名称来描述该公司
prompt1 = ChatPromptTemplate.from_template("描述制造{product}该产品的公司的最佳名称是什么")
# 3.初始化提示模版2:接受公司名称,然后输出该公司的长为20个单词的描述
prompt2 = ChatPromptTemplate.from_template("写一个20个单词的描述对于这个公司:{company_name}")
# 4.构建大语言模型子链,链~=LLM+Prompt
chain_one = LLMChain(llm=llm, prompt=prompt1)
chain_two = LLMChain(llm=llm, prompt=prompt2)
# 5.构建一个简单顺序链,把两个子链组合起来
simple_chain = SimpleSequentialChain(chains=[chain_one, chain_two], verbose=True)
# 6.运行简单顺序链
product = "大号床单套装"
simple_chain.invoke(product)
if __name__ == "__main__":
main()
输出:
> Entering new SimpleSequentialChain chain...
"豪华床品有限公司"
"豪华床品有限公司"提供高品质、舒适的床上用品,让您享受豪华睡眠体验,提升生活品质。
复杂顺序链
当有多个输入或多个输出时,就需要复杂顺序链来实现;简单顺序链只针对一个输入和一个输出时。
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
from langchain.chains import LLMChain, SequentialChain
api_key = "sk-xxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 1.初始化语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 2.子链1: 翻译成英语
prompt1 = ChatPromptTemplate.from_template(
"把下面的文本翻译成英文: \n"
"{review}"
)
chain_one = LLMChain(llm=llm, prompt=prompt1, output_key="english_review")
# 2.子链2: 用一句话总结下面的文本
prompt2 = ChatPromptTemplate.from_template(
"用一句话总结下面的文本:\n"
"{english_review}"
)
chain_two = LLMChain(llm=llm, prompt=prompt2, output_key="summary")
# 4.子链3: 下面文本使用什么语言
prompt3 = ChatPromptTemplate.from_template(
"下面的文本使用的是什么语言:\n"
"{review}"
)
chain_three = LLMChain(llm=llm, prompt=prompt3, output_key="language")
# 4.子链4: 使用特定的语言对下面的总结写一个后续回复
prompt4 = ChatPromptTemplate.from_template(
"使用特定的语言对下面的总结写一个后续回复:\n"
"总结: {summary}\n语言: {language}"
)
chain_four = LLMChain(llm=llm, prompt=prompt4, output_key="followup_message")
# 5.构建一个顺序链,把4个子链组合起来
chain = SequentialChain(
chains=[chain_one, chain_two, chain_three, chain_four],
input_variables=["review"],
output_variables=["english_review","summary", "followup_message"],
verbose=True,
return_all=True)
# 6.运行顺序链
review = "Kubernetes 和更广泛的容器生态系统正发展为通用计算平台和生态系统,\
可以媲美甚至超越虚拟机 (VM),作为现代云基础设施和应用程序的基本构建块。\
该生态系统使组织能够提供高生产力的平台即服务 (PaaS),\
解决围绕云原生开发的多个基础设施相关和操作相关任务与问题,\
以便开发团队专注于编码和创新"
print(chain.invoke(review))
if __name__ == "__main__":
main()
输出:
{'review': 'Kubernetes 和更广泛的容器生态系统正发展为通用计算平台和生态系统, 可以媲美甚至超越虚拟机 (VM),作为现代云基础设施和应用程序的基本构建块。 该生态系统使组织能够提供高生产力的平台即服务 (PaaS), 解决围绕云原生开发的多个基础设施相关和操作相关任务与问题, 以便开发团队专注于编码和创新', 'english_review': 'Kubernetes and the broader container ecosystem are evolving into a universal computing platform and ecosystem that can rival or even surpass virtual machines (VMs) as the fundamental building blocks of modern cloud infrastructure and applications. This ecosystem enables organizations to deliver highly productive platform-as-a-service (PaaS), addressing multiple infrastructure and operational tasks and issues related to cloud-native development, allowing development teams to focus on coding and innovation.', 'summary': 'Kubernetes and containers are becoming the new standard for cloud infrastructure, enabling organizations to focus on coding and innovation.', 'followup_message': '非常赞同这个总结!Kubernetes和容器正在成为云基础设施的新标准,让组织能够更专注于编码和创新。这种趋势对于推动技术发展和提高效率都有着重要的作用。希望更多的企业能够采用这些先进的技术,实现更快速的发展和创新。'}
路由链
路由链顾名思义可以定义路由,具体路由到某一个子链上去,这样就可以实现更复杂的链操作。
路由器由两个组件组成:(类似网络中的路由概念)
- 路由链:路由器链本身,负责选择要调用的下一个链
- 目的链:路由器链可以路由到的链
from langchain_openai.chat_models import ChatOpenAI
from langchain.prompts import ChatPromptTemplate, PromptTemplate
from langchain.chains import LLMChain
from langchain.chains.router import MultiPromptChain
from langchain.chains.router.llm_router import LLMRouterChain
from langchain.chains.router.llm_router import RouterOutputParser
api_key = "sk-xxx"
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 1.初始化语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 2.初始化物理问题提示模版
physics_template = """你是一个非常聪明的物理专家\
你擅长用一种简洁并且易于理解的方式去回答问题\
当你不知道问题的答案时,你承认\
你不知道.
这是一个问题:
{input}
"""
# 3.初始化数学问题提示模版
math_template = """你是一个非常优秀的数学家。\
你擅长回答数学问题。\
你之所以如此优秀,\
是因为你能够将棘手的问题分解为组成部分,\
回答组成部分,然后将它们组合在一起,回答更广泛的问题。
这是一个问题:
{input}
"""
# 4.初始化历史问题提示模版
history_template = """你是以为非常优秀的历史学家。\
你对一系列历史时期的人物、事件和背景有着极好的学识和理解\
你有能力思考、反思、辩证、讨论和评估过去。\
你尊重历史证据,并有能力利用它来支持你的解释和判断。
这是一个问题:
{input}
"""
# 5.初始化计算机问题提示模版
computerscience_template = """你是一个成功的计算机科学专家。\
你有创造力、协作精神、\
前瞻性思维、自信、解决问题的能力、\
对理论和算法的理解以及出色的沟通技巧。\
你非常擅长回答编程问题。\
你之所以如此优秀,是因为你知道\
如何通过以机器可以轻松解释的命令式步骤描述解决方案来解决问题,\
并且你知道如何选择在时间复杂性和空间复杂性之间取得良好平衡的解决方案。
这是一个问题:
{input}
"""
# 6.对上述提示模版进行命名和描述,这些信息传递给路由链,路由链决定使用哪个子链
prompt_infos = [
{
"name": "物理学",
"desc": "擅长回答关于物理学的问题",
"prompt_template": physics_template
},
{
"name": "数学",
"desc": "擅长回答数学问题",
"prompt_template": math_template
},
{
"name": "历史",
"desc": "擅长回答历史问题",
"prompt_template": history_template
},
{
"name": "计算机科学",
"desc": "擅长回答计算机科学问题",
"prompt_template": computerscience_template
}
]
# 7.基于提示模版信息创建对应的目的链
destination_chains = {}
for p_info in prompt_infos:
name = p_info["name"]
prompt_tempalte = p_info["prompt_template"]
prompt = ChatPromptTemplate.from_template(
template=prompt_tempalte)
chain = LLMChain(
llm=llm,
prompt=prompt,
)
destination_chains[name] = chain
destinations = [f"{p['name']}: {p['desc']}" for p in prompt_infos]
destinations_str = "\n".join(destinations)
# 8.创建默认目的链,类似路由表中的默认路由
default_prompt = ChatPromptTemplate.from_template("{input}")
default_chain = LLMChain(
llm=llm,
prompt=default_prompt,
)
# 9.定义不同链之间的路由模版,返回的格式要求为什么是destination和next_inputs,
# 跟RouterOutputParser相绑定的。为什么是4个花括号?因为要进行两次format,两个花括号相当于输出一个花括号
MULTI_PROMPT_ROUTER_TEMPLATE = """
给语言模型一个原始文本输入,\
让其选择最适合输入的模型提示.\
系统将为您提供可用提示的名称以及最适合改提示的描述\
如果你认为修改原始输入最终会导致语言模型做出更好的响应,\
你也可以修改原始输入.
<< 格式 >>
返回一个带有JSON对象的markdown代码片段, 该JSON对象的格式如下:
```json
{{{{
"destination": string 使用提示名字或者使用"DEFAULT"
"next_inputs": string 原始输入的改进版本
}}}}
```
记住:"destination"必须是下面指定的候选提示名称之一, \
或者如果输入不太适合任何候选提示, \
则可以是"DEFAULT"。\
记住:如果您认为不需要任何修改, \
则"next_inputs"可以只是原始输入。
<< 候选提示 >>
{destinations}
<< 输入 >>
{{input}}
"""
# 10.构建路由链
router_template = MULTI_PROMPT_ROUTER_TEMPLATE.format(
destinations=destinations_str
)
print(router_template)
print(router_template)
router_prompt = PromptTemplate(
template=router_template,
input_variables=["input"],
)
router_prompt.output_parser = RouterOutputParser()
router_chain = LLMRouterChain.from_llm(llm, router_prompt)
# 11.创建多提示链
chain = MultiPromptChain(
router_chain=router_chain,
destination_chains=destination_chains,
default_chain=default_chain,
verbose=True,
)
# 12.运行路由链
print(chain.invoke(input={"input": "1+3等于多少?"}))
print(chain.invoke(input={"input": "黑洞是什么?"}))
print(chain.invoke(input={"input": "五代十国是什么?"}))
print(chain.invoke(input={"input": "最流行的编程语言是什么?"}))
print(chain.invoke(input={"input": "你喜欢什么?"}))
if __name__ == "__main__":
main()
输出:
> Entering new MultiPromptChain chain...
数学: {'input': '1 + 3 等于多少?'}
> Finished chain.
{'input': '1 + 3 等于多少?', 'text': '1 + 3 = 4.'}
> Entering new MultiPromptChain chain...
物理学: {'input': '黑洞是什么?'}
> Finished chain.
{'input': '黑洞是什么?', 'text': '黑洞是宇宙中一种非常密集的天体,它的引力非常强大,甚至连光都无法逃离它的吸引力。黑洞形成于恒星死亡时,其质量非常大,体积非常小,因此被称为“黑洞”。在黑洞的事件视界内,引力非常强大,甚至时间和空间都会被扭曲。目前科学家对黑洞的研究仍在进行中,仍有很多未解之谜。'}
> Entering new MultiPromptChain chain...
历史: {'input': '五代十国是中国历史上的一个时期,指的是五代时期和十国时期的合称。'}
> Finished chain.
{'input': '五代十国是中国历史上的一个时期,指的是五代时期和十国时期的合称。', 'text': '请问你对五代十国时期的政治、经济和文化特点有什么深入的见解和分析?你认为这个时期对中国历史的发展有着怎样的影响?'}
> Entering new MultiPromptChain chain...
计算机科学: {'input': '最流行的编程语言是什么?'}
> Finished chain.
{'input': '最流行的编程语言是什么?', 'text': '目前最流行的编程语言之一是Python。Python是一种简单易学、功能强大的编程语言,被广泛用于数据科学、人工智能、Web开发等领域。它具有丰富的库和工具,使得开发人员可以快速高效地完成各种任务。另外,JavaScript、Java、C++、C#等编程语言也在不同领域有着广泛的应用和较高的流行度。'}
> Entering new MultiPromptChain chain...
None: {'input': '你喜欢什么?'}
> Finished chain.
{'input': '你喜欢什么?', 'text': '作为一个AI助手,我没有情感和喜好,我只是一个程序,可以帮助您解决问题和提供信息。请问有什么可以帮助您的吗?'}
检索问答链
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.vectorstores.docarray import DocArrayInMemorySearch
from langchain_openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 使用LangChain文档加载器csv类型对数据进行导入, csv表格自造数据
file = "/Users/iceyao/Desktop/test_101.csv"
csv_loader = CSVLoader(file_path=file)
docs = csv_loader.load()
# 使用OpenAI的向量嵌入
embedding = OpenAIEmbeddings(
api_key=api_key,
base_url=openai_url)
# 初始化向量存储,文档列表、向量嵌入作为参数
vector_db = DocArrayInMemorySearch.from_documents(docs, embedding)
# 使用OpenAI语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 使用检索问答链来回答问题,基于向量存储创建检索器
retriever = vector_db.as_retriever()
# from_chain_type参数说明:
# llm:语言模型
# retriever:检索器
# chain_type:链类型
# chain_type = stuff, 是将所有查询得到的文档组合成一个文档传入下一步
# chain_type = map_reduce, 将所有块与问题一起传递给语言模型,获取回复,使用另一个语言模型调用将所有单独的回复总结成最终答案,它可以在任意数量的文档上运行。可以并行处理单个问题,同时也需要更多的调用。它将所有文档视为独立的
# chain_type = refine, 用于循环许多文档,际上是迭代的,建立在先前文档的答案之上,非常适合前后因果信息并随时间逐步构建答案,依赖于先前调用的结果。它通常需要更长的时间,并且基本上需要与map_reduce一样多的调用
# chain_type = map_rerank, 对每个文档进行单个语言模型调用,要求它返回一个分数,选择最高分,这依赖于语言模型知道分数应该是什么,需要告诉它,如果它与文档相关,则应该是高分
retrieva_qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type="stuff",
verbose=True,
)
query = "请用markdown表格的方式列出所有跟云相关的标题,并对每个标题进行抽象总结"
result = retrieva_qa({"query": query})
print(result['result'])
if __name__ == "__main__":
main()
输出:
| 标题 | 抽象总结 |
|--------------------------------------------|------------------------------------|
| 一图带你看懂云原生 | 通过图示解释云原生的概念和特点 |
| 云原生可观测平台国际产品调研 | 调研国际市场上的云原生可观测平台产品 |
| 云原生可观测平台国内产品调研 | 调研国内市场上的云原生可观测平台产品 |
| 云平台前端框架方案 | 探讨云平台前端框架解决方案 |
基于文档的问答
直接使用向量存储查询
使用大语言模型构建一个基于给定文档和文档集合的问答系统是一种非常经典的应用场景。基于文档问答的这个实现,涉及到LangChain的其它组件, 比如:嵌入模型(Embedding Models)和向量存储。
大型深度学习模型中的嵌入(Embedding)是指将高维度输入数据(如文本或图像)映射到低维度空间的向量表示。在自然语言处理(NLP)中,嵌入 通常用于将单词或短语映射到向量空间中的连续值,以便进行文本分类、情感分析、机器翻译等任务。
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain.indexes import VectorstoreIndexCreator
from langchain_community.vectorstores.docarray import DocArrayInMemorySearch
from langchain_openai import OpenAIEmbeddings
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 1.初始化语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 2.使用LangChain文档加载器csv类型对数据进行导入, csv数据可以自行创造
file = "/Users/iceyao/Desktop/test_101.csv"
csv_loader = CSVLoader(file_path=file)
# 3.基于文档加载器创建LangChain向量存储索引,这里使用向量内存存储
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=OpenAIEmbeddings(
api_key=api_key,
base_url=openai_url)).from_loaders([csv_loader])
# 4.查询创建的向量存储,问题要跟csv内容有所关联
query = "请用markdown表格的方式列出所有跟云相关的标题,并对每个标题进行抽象总结"
response = index.query(question=query, llm=llm)
print(response)
if __name__ == "__main__":
main()
输出:
| 标题 | 抽象总结 |
|----------------------------|-----------------|
| 一图带你看懂云原生 | 介绍云原生概念和特点 |
| 可观测平台国际产品调研 | 可观测平台国际产品调研 |
| 可观测平台国内产品调研 | 可观测平台国际产品调研 |
| 云平台前端框架方案 | 云平台前端框架方案介绍 |
向量嵌入和向量存储
大语言模型有上下文长度限制,直接处理长文档有点困难。要想实现长文档的问答,需引入向量嵌入(Embeddings)和向量存储(VectorStore)等技术;如何构建处理大规模长文档的问答系统? 1.使用Embeddings算法对文档进行向量化,语义相近的文本片段用相近的向量表示。 2.将向量化的文档切为小块,存入向量数据库;向量数据库对各文档片段进行索引,支持快速检索。
使用向量技术架构的话,当用户提问时,先将问题转化为向量,在向量数据库中快速查找到语义最相关的文档片段,然后再把这些文档片段和问题一起发送给语言模型,返回生成的回答。
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.vectorstores.docarray import DocArrayInMemorySearch
from langchain_openai import OpenAIEmbeddings
from langchain.chains import RetrievalQA
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 使用LangChain文档加载器csv类型对数据进行导入
file = "/Users/iceyao/Desktop/test_101.csv"
csv_loader = CSVLoader(file_path=file)
docs = csv_loader.load()
# 使用OpenAI的向量嵌入
embedding = OpenAIEmbeddings(
api_key=api_key,
base_url=openai_url)
# 初始化向量存储,文档列表、向量嵌入作为参数
vector_db = DocArrayInMemorySearch.from_documents(docs, embedding)
# 返回一个文档列表,默认返回4个最相近语义的文档
docs = vector_db.similarity_search("推荐一篇跟存储相关的文章")
print("返回文档的数量:{0}\n".format(len(docs)))
print("第一个文档是:{0}\n".format(docs[0]))
print("第二个文档是:{0}\n".format(docs[1]))
# 使用OpenAI语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 把返回的文档列表,构造成提示发送给语言模型来回答
qdocs = "".join([docs[i].page_content for i in range(len(docs))])
response = llm.invoke(
input=f"{qdocs}问题:请用markdown表格的方式列出所有跟云相关的标题,并对每个标题进行抽象总结")
print(response.content)
# 使用检索问答链来回答问题,基于向量存储创建检索器
retriever = vector_db.as_retriever()
retrieva_qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=retriever,
chain_type="stuff",
verbose=True,
)
query = "请用markdown表格的方式列出所有跟云相关的标题,并对每个标题进行抽象总结"
result = retrieva_qa({"query": query})
print(result['result'])
if __name__ == "__main__":
main()
输出:
返回文档的数量:4
第一个文档是:page_content='\ufeff标题: 一文快速部署并配置普罗米远端存储——VictoriaMetrics\n链接: https://xxx.com/teams/k100017/docs/f54d5dbc83f811eda4b5b6df5a597271?company_from=6df6b7dadb4311e880ee5254002b9121\n作者: xxx\n领域: 云原生' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 31}
第二个文档是:page_content='\ufeff标题: 高质量的技术分享应该包含哪些内容?\n链接: https://xxx.com/teams/k100017/docs/57540e2ef0da11eb8adaaad8bc976c66?company_from=6df6b7dadb4311e880ee5254002b9121\n作者: xxx\n领域: 工程规范' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 67}
| 标题 | 抽象总结 |
|--------------------------------------------------------|----------------------------------------|
| 一文快速部署并配置普罗米远端存储——VictoriaMetrics | 部署和配置远端存储的快速指南 |
| 高质量的技术分享应该包含哪些内容? | 技术分享内容的要素和标准 |
| 一文浅析kubernetes event及其持久化方案 | 分析Kubernetes事件及其持久化解决方案 |
| 你不知道的Postman效率提升技巧 | 提升使用Postman工具效率的技巧 |
这里用到了LangChain的检索问答链
评估Evaluation
评估是检验语言模型问答质量的关键环节。评估可以检验语言模型在不同文档上的问答效果,还可以通过比较不同模型,选择最佳系统。此外,定期评估也可以检查模型质量的衰减。评估通常有两个目的:
- 检验LLM应用是否达到了验收标准
- 分析改动对于LLM应用性能的影响
基本的思路就是利用语言模型本身和链本身,来辅助评估其他的语言模型、链和应用程序。
excel样本数据:
| 产品名称 | 产品类型 | 产品简介 | 适用场景 | 融资主体 | 融资额度 | 融资期限 | 融资成本 | 担保方式 | 风险控制 | 优势 | 案例 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 应收账款质押融资 | 动产融资 | 以应收账款为质押品获取融资 | 核心企业、中小企业 | 核心企业、中小企业 | 100万元以上 | 1个月-3年 | 5%-8% | 应收账款质押、信用担保、保证担保等 | 应收账款真实性、债权清晰性、履约能力等 | 融资便捷、成本较低、提高资金利用率 | 某大型制造企业利用应收账款质押融资,获得了1000万元的流动资金,用于采购原材料,有效缓解了资金压力,促进生产经营。 |
| 仓单融资 | 动产融资 | 以仓单为质押品获取融资 | 核心企业、中小企业 | 核心企业、中小企业 | 100万元以上 | 1个月-3年 | 4%-7% | 仓单质押、信用担保、保证担保等 | 货物真实性、权属清晰性、仓储安全等 | 融资便捷、成本较低、盘活存货资产 | 某贸易企业利用仓单融资,获得了500万元的流动资金,用于扩大进出口业务,提高了资金周转效率。 |
| 订单融资 | 信用融资 | 以订单为基础获取融资 | 核心企业、中小企业 | 核心企业、中小企业 | 100万元以上 | 1个月-1年 | 3%-6% | 订单真实性、买方信用状况等 | 订单池管理、风险分散等 | 融资便捷、成本较低、提升供应链协同效率 | 某电商企业利用订单融资,获得了2000万元的流动资金,用于备货发货,满足了订单快速增长的需求。 |
| 动产抵押融资 | 动产融资 | 以动产(如设备、车辆等)为质押品获取融资 | 中小企业 | 中小企业 | 50万元以上 | 1个月-3年 | 5%-8% | 动产抵押、信用担保、保证担保等 | 动产权属清晰性、评估价值等 | 融资便捷、提高资产利用率 | 某科技企业利用动产抵押融资,获得了100万元的流动资金,用于研发新产品,提升了企业竞争力。 |
| 保单融资 | 信用融资 | 以保单为质押品获取融资 | 核心企业、中小企业 | 核心企业、中小企业 | 100万元以上 | 1个月-1年 | 3%-6% | 保单质押、信用担保、保证担保等 | 保单真实性、保费支付记录等 | 融资便捷、成本较低、盘活保单资产 | 某制造企业利用保单融资,获得了500万元的流动资金,用于采购原材料,降低了融资成本。 |
| 流水贷款 | 信用融资 | 以企业历史经营数据为基础获取融资 | 核心企业、中小企业 | 核心企业、中小企业 | 100万元以上 | 1个月-3年 | 4%-7% | 企业财务数据、经营状况等 | 信用评级、风险监控等 | 融资便捷、无需抵押、手续简便 | 某零售企业利用流水贷款,获得了200万元的流动资金, |
创建待评估的LLM应用
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.document_loaders.csv_loader import CSVLoader
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 使用LangChain文档加载器csv类型对数据进行导入
file = "/Users/iceyao/Desktop/test_101.csv"
csv_loader = CSVLoader(file_path=file)
docs = csv_loader.load()
# 使用OpenAI语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 打印几条样本数据
for i in range(len(docs[0:5])):
print(docs[i].page_content + "\n")
if __name__ == "__main__":
main()
输出:
产品名称: 应收账款质押融资
产品类型: 动产融资
产品简介: 以应收账款为质押品获取融资
适用场景: 核心企业、中小企业
融资主体: 核心企业、中小企业
融资额度: 100万元以上
融资期限: 1个月-3年
融资成本: 5%-8%
担保方式: 应收账款质押、信用担保、保证担保等
风险控制: 应收账款真实性、债权清晰性、履约能力等
优势: 融资便捷、成本较低、提高资金利用率
案例: 某大型制造企业利用应收账款质押融资,获得了1000万元的流动资金,用于采购原材料,有效缓解了资金压力,促进生产经营。
产品名称: 仓单融资
产品类型: 动产融资
产品简介: 以仓单为质押品获取融资
适用场景: 核心企业、中小企业
融资主体: 核心企业、中小企业
融资额度: 100万元以上
融资期限: 1个月-3年
融资成本: 4%-7%
担保方式: 仓单质押、信用担保、保证担保等
风险控制: 货物真实性、权属清晰性、仓储安全等
优势: 融资便捷、成本较低、盘活存货资产
案例: 某贸易企业利用仓单融资,获得了500万元的流动资金,用于扩大进出口业务,提高了资金周转效率。
产品名称: 订单融资
产品类型: 信用融资
产品简介: 以订单为基础获取融资
适用场景: 核心企业、中小企业
融资主体: 核心企业、中小企业
融资额度: 100万元以上
融资期限: 1个月-1年
融资成本: 3%-6%
担保方式: 订单真实性、买方信用状况等
风险控制: 订单池管理、风险分散等
优势: 融资便捷、成本较低、提升供应链协同效率
案例: 某电商企业利用订单融资,获得了2000万元的流动资金,用于备货发货,满足了订单快速增长的需求。
产品名称: 动产抵押融资
产品类型: 动产融资
产品简介: 以动产(如设备、车辆等)为质押品获取融资
适用场景: 中小企业
融资主体: 中小企业
融资额度: 50万元以上
融资期限: 1个月-3年
融资成本: 5%-8%
担保方式: 动产抵押、信用担保、保证担保等
风险控制: 动产权属清晰性、评估价值等
优势: 融资便捷、提高资产利用率
案例: 某科技企业利用动产抵押融资,获得了100万元的流动资金,用于研发新产品,提升了企业竞争力。
产品名称: 保单融资
产品类型: 信用融资
产品简介: 以保单为质押品获取融资
适用场景: 核心企业、中小企业
融资主体: 核心企业、中小企业
融资额度: 100万元以上
融资期限: 1个月-1年
融资成本: 3%-6%
担保方式: 保单质押、信用担保、保证担保等
风险控制: 保单真实性、保费支付记录等
优势: 融资便捷、成本较低、盘活保单资产
案例: 某制造企业利用保单融资,获得了500万元的流动资金,用于采购原材料,降低了融资成本。
手动创建测试用例
这里文档格式是csv文件,CSVLoader对文件的每一行数据进行分割,根据输出的格式手动设置几条问答对
examples = [
{
"query": "仓单融资的产品的优点是什么?",
"answer": "成本低、操作便捷"
},
{
"query": "订单融资产品适用哪些企业?",
"answer": "有实力的核心企业,还有一些中小企业"
}
]
LLM自动生成测试用例
一个模型评估的大致流程:
手动创建问题和答案 -> 使用LLM自动创建问答测试用例 -> 使用同一个LLM回答 -> 让另一个LLM进行答案判断
借助LangChain的QAGenerateChain可以自动创建大量问答测试集,自动化评估是LangChain框架的一大优势,极大降低开发RAG系统的门槛。
原生的QAGenerateChain只支持中文,这里需要继承下QAGenerateChain类,然后重写下from_llm方法
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain.evaluation.qa import QAGenerateChain
from langchain.base_language import BaseLanguageModel
from langchain.prompts import PromptTemplate
from typing import Any
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
template = """You are a teacher coming up with questions to ask on a quiz.
Given the following document, please generate a question and answer based on that document.
Example Format:
<Begin Document>
...
<End Document>
QUESTION: question here
ANSWER: answer here
These questions should be detailed and be based explicitly on information in the document. Begin!
<Begin Document>
{doc}
<End Document>
请使用中文输出
"""
PROMPT = PromptTemplate(
input_variables=["doc"],
template=template,
)
# 继承QAGenerateChain,重写from_llm方法
class ZhCNQAGenerateChain(QAGenerateChain):
"""LLM Chain for generating examples for question answering."""
@classmethod
def from_llm(cls, llm: BaseLanguageModel, **kwargs: Any) -> QAGenerateChain:
"""Load QA Generate Chain from LLM."""
return cls(llm=llm, prompt=PROMPT, **kwargs)
def main():
# 使用LangChain文档加载器csv类型对数据进行导入
file = "/Users/iceyao/Desktop/test_101.csv"
csv_loader = CSVLoader(file_path=file)
docs = csv_loader.load()
# 使用OpenAI语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 创建ZhCNQAGenerateChain链
sample_qa_chain = ZhCNQAGenerateChain.from_llm(llm)
# 调用apply方法自动创建问答对
examples = sample_qa_chain.apply([{"doc": t} for t in docs])
# 打印问答对
for i in examples:
print(i['qa_pairs'])
if __name__ == "__main__":
main()
输出:
{'query': '什么是“应收账款质押融资”产品的主要特点和优势? ', 'answer': '“应收账款质押融资”产品的主要特点包括产品类型为动产融资,适用场景为核心企业和中小企业,融资额度为100万元以上,融资期限为1个月至3年,融资成本为5%-8%,担保方式包括应收账款质押、信用担保、保证担保等。其优势在于融资便捷、成本较低、提高资金利用率。'}
{'query': '仓单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?融资成本是多少?担保方式有哪些?', 'answer': '仓单融资产品适用于核心企业和中小企业。融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至3年。融资成本为4%-7%。担保方式包括仓单质押、信用担保、保证担保等。'}
{'query': '什么是订单融资的产品简介和适用场景?融资额度和期限是多少?融资成本是多少?担保方式和风险控制措施是什么?', 'answer': '订单融资是以订单为基础获取融资的信用融资产品,适用于核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至1年,融资成本为3%-6%。担保方式包括订单真实性和买方信用状况等,风险控制措施包括订单池管理和风险分散。'}
{'query': '什么是动产抵押融资的产品类型和适用场景?', 'answer': '动产抵押融资的产品类型是动产融资,适用场景是中小企业。'}
{'query': '保单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?', 'answer': '保单融资产品适用于核心企业和中小企业,融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至1年。'}
{'query': '流水贷款的产品类型是什么?融资额度是多少?融资期限是多久?', 'answer': '流水贷款的产品类型是信用融资,融资额度为100万元以上,融资期限为1个月至3年。'}
人工评估
# flake8: noqa
from langchain.globals import set_debug
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.vectorstores.docarray import DocArrayInMemorySearch
from langchain_openai import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain.evaluation.qa import QAGenerateChain
from langchain.base_language import BaseLanguageModel
from langchain.prompts import PromptTemplate
from typing import Any
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
template = """You are a teacher coming up with questions to ask on a quiz.
Given the following document, please generate a question and answer based on that document.
Example Format:
<Begin Document>
...
<End Document>
QUESTION: question here
ANSWER: answer here
These questions should be detailed and be based explicitly on information in the document. Begin!
<Begin Document>
{doc}
<End Document>
请使用中文输出
"""
PROMPT = PromptTemplate(
input_variables=["doc"],
template=template,
)
examples = [
{
'query': '仓单融资的产品的优点是什么?',
'answer': '成本低、操作便捷'
},
{
'query': '订单融资产品适用哪些企业?',
'answer': '有实力的核心企业,还有一些中小企业'
}
]
# 继承QAGenerateChain,重写from_llm方法
class ZhCNQAGenerateChain(QAGenerateChain):
"""LLM Chain for generating examples for question answering."""
@classmethod
def from_llm(cls, llm: BaseLanguageModel, **kwargs: Any) -> QAGenerateChain:
"""Load QA Generate Chain from LLM."""
return cls(llm=llm, prompt=PROMPT, **kwargs)
def main():
# 开启LangChain全局debug
set_debug(True)
# 使用LangChain文档加载器csv类型对数据进行导入
file = "/Users/iceyao/Desktop/test_101.csv"
csv_loader = CSVLoader(file_path=file)
docs = csv_loader.load()
# 基于文档加载器创建LangChain向量存储索引,这里使用向量内存存储
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=OpenAIEmbeddings(
api_key=api_key,
base_url=openai_url)).from_loaders([csv_loader])
# 使用OpenAI语言模型
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 创建检索QA链
retrieval_qa_chain = RetrievalQA.from_chain_type(
llm=llm,
retriever=index.vectorstore.as_retriever(),
chain_type="stuff",
verbose=True,
)
# 创建ZhCNQAGenerateChain链
sample_qa_chain = ZhCNQAGenerateChain.from_llm(llm)
# 调用apply方法自动创建问答对
llm_examples = sample_qa_chain.apply([{"doc": t} for t in docs])
# 整合测试用例,将手动测试用例和LLM测试用例合并
llm_examples = [v for item in llm_examples for _, v in item.items()]
new_examples = examples + llm_examples
# 打印手动测试用例的第一个问题的LLM答案
print(retrieval_qa_chain.invoke({"query": examples[0]['query']})) # type: ignore[misc]
if __name__ == "__main__":
main()
输出:
[chain/start] [1:chain:ZhCNQAGenerateChain] Entering Chain run with input:
[inputs]
[llm/start] [1:chain:ZhCNQAGenerateChain > 2:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"Human: You are a teacher coming up with questions to ask on a quiz.\nGiven the following document, please generate a question and answer based on that document.\n\nExample Format:\n<Begin Document>\n...\n<End Document>\nQUESTION: question here\nANSWER: answer here\n\nThese questions should be detailed and be based explicitly on information in the document. Begin!\n\n<Begin Document>\npage_content='\\ufeff产品名称: 应收账款质押融资\\n产品类型: 动产融资\\n产品简介: 以应收账款为质押品获取融资\\n适用场景: 核心企业、中小企业\\n融资主体: 核心企业、中小企业\\n融资额度: 100万元以上\\n融资期限: 1个月-3年\\n融资成本: 5%-8%\\n担保方式: 应收账款质押、信用担保、保证担保等\\n风险控制: 应收账款真实性、债权清晰性、履约能力等\\n优势: 融资便捷、成本较低、提高资金利用率\\n案例: 某大型制造企业利用应收账款质押融资,获得了1000万元的流动资金,用于采购原材料,有效缓解了资金压力,促进生产经营。' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 0}\n<End Document>\n请使用中文输出"
]
}
[llm/start] [1:chain:ZhCNQAGenerateChain > 3:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"Human: You are a teacher coming up with questions to ask on a quiz.\nGiven the following document, please generate a question and answer based on that document.\n\nExample Format:\n<Begin Document>\n...\n<End Document>\nQUESTION: question here\nANSWER: answer here\n\nThese questions should be detailed and be based explicitly on information in the document. Begin!\n\n<Begin Document>\npage_content='\\ufeff产品名称: 仓单融资\\n产品类型: 动产融资\\n产品简介: 以仓单为质押品获取融资\\n适用场景: 核心企业、中小企业\\n融资主体: 核心企业、中小企业\\n融资额度: 100万元以上\\n融资期限: 1个月-3年\\n融资成本: 4%-7%\\n担保方式: 仓单质押、信用担保、保证担保等\\n风险控制: 货物真实性、权属清晰性、仓储安全等\\n优势: 融资便捷、成本较低、盘活存货资产\\n案例: 某贸易企业利用仓单融资,获得了500万元的流动资金,用于扩大进出口业务,提高了资金周转效率。' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 1}\n<End Document>\n请使用中文输出"
]
}
[llm/start] [1:chain:ZhCNQAGenerateChain > 4:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"Human: You are a teacher coming up with questions to ask on a quiz.\nGiven the following document, please generate a question and answer based on that document.\n\nExample Format:\n<Begin Document>\n...\n<End Document>\nQUESTION: question here\nANSWER: answer here\n\nThese questions should be detailed and be based explicitly on information in the document. Begin!\n\n<Begin Document>\npage_content='\\ufeff产品名称: 订单融资\\n产品类型: 信用融资\\n产品简介: 以订单为基础获取融资\\n适用场景: 核心企业、中小企业\\n融资主体: 核心企业、中小企业\\n融资额度: 100万元以上\\n融资期限: 1个月-1年\\n融资成本: 3%-6%\\n担保方式: 订单真实性、买方信用状况等\\n风险控制: 订单池管理、风险分散等\\n优势: 融资便捷、成本较低、提升供应链协同效率\\n案例: 某电商企业利用订单融资,获得了2000万元的流动资金,用于备货发货,满足了订单快速增长的需求。' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 2}\n<End Document>\n请使用中文输出"
]
}
[llm/start] [1:chain:ZhCNQAGenerateChain > 5:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"Human: You are a teacher coming up with questions to ask on a quiz.\nGiven the following document, please generate a question and answer based on that document.\n\nExample Format:\n<Begin Document>\n...\n<End Document>\nQUESTION: question here\nANSWER: answer here\n\nThese questions should be detailed and be based explicitly on information in the document. Begin!\n\n<Begin Document>\npage_content='\\ufeff产品名称: 动产抵押融资\\n产品类型: 动产融资\\n产品简介: 以动产(如设备、车辆等)为质押品获取融资\\n适用场景: 中小企业\\n融资主体: 中小企业\\n融资额度: 50万元以上\\n融资期限: 1个月-3年\\n融资成本: 5%-8%\\n担保方式: 动产抵押、信用担保、保证担保等\\n风险控制: 动产权属清晰性、评估价值等\\n优势: 融资便捷、提高资产利用率\\n案例: 某科技企业利用动产抵押融资,获得了100万元的流动资金,用于研发新产品,提升了企业竞争力。' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 3}\n<End Document>\n请使用中文输出"
]
}
[llm/start] [1:chain:ZhCNQAGenerateChain > 6:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"Human: You are a teacher coming up with questions to ask on a quiz.\nGiven the following document, please generate a question and answer based on that document.\n\nExample Format:\n<Begin Document>\n...\n<End Document>\nQUESTION: question here\nANSWER: answer here\n\nThese questions should be detailed and be based explicitly on information in the document. Begin!\n\n<Begin Document>\npage_content='\\ufeff产品名称: 保单融资\\n产品类型: 信用融资\\n产品简介: 以保单为质押品获取融资\\n适用场景: 核心企业、中小企业\\n融资主体: 核心企业、中小企业\\n融资额度: 100万元以上\\n融资期限: 1个月-1年\\n融资成本: 3%-6%\\n担保方式: 保单质押、信用担保、保证担保等\\n风险控制: 保单真实性、保费支付记录等\\n优势: 融资便捷、成本较低、盘活保单资产\\n案例: 某制造企业利用保单融资,获得了500万元的流动资金,用于采购原材料,降低了融资成本。' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 4}\n<End Document>\n请使用中文输出"
]
}
[llm/start] [1:chain:ZhCNQAGenerateChain > 7:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"Human: You are a teacher coming up with questions to ask on a quiz.\nGiven the following document, please generate a question and answer based on that document.\n\nExample Format:\n<Begin Document>\n...\n<End Document>\nQUESTION: question here\nANSWER: answer here\n\nThese questions should be detailed and be based explicitly on information in the document. Begin!\n\n<Begin Document>\npage_content='\\ufeff产品名称: 流水贷款\\n产品类型: 信用融资\\n产品简介: 以企业历史经营数据为基础获取融资\\n适用场景: 核心企业、中小企业\\n融资主体: 核心企业、中小企业\\n融资额度: 100万元以上\\n融资期限: 1个月-3年\\n融资成本: 4%-7%\\n担保方式: 企业财务数据、经营状况等\\n风险控制: 信用评级、风险监控等\\n优势: 融资便捷、无需抵押、手续简便\\n案例: 某零售企业利用流水贷款,获得了200万元的流动资金,' metadata={'source': '/Users/iceyao/Desktop/test_101.csv', 'row': 5}\n<End Document>\n请使用中文输出"
]
}
[llm/end] [1:chain:ZhCNQAGenerateChain > 2:llm:ChatOpenAI] [17.97s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "QUESTION: 什么是\"应收账款质押融资\"的产品类型?融资主体是谁?融资额度和期限是多少?融资成本是多少?担保方式有哪些?\nANSWER: \"应收账款质押融资\"的产品类型是动产融资。融资主体可以是核心企业或中小企业。融资额度为100万元以上,融资期限为1个月至3年,融资成本为5%-8%。担保方式包括应收账款质押、信用担保、保证担保等。",
"generation_info": {
"finish_reason": "stop",
"logprobs": null
},
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "QUESTION: 什么是\"应收账款质押融资\"的产品类型?融资主体是谁?融资额度和期限是多少?融资成本是多少?担保方式有哪些?\nANSWER: \"应收账款质押融资\"的产品类型是动产融资。融资主体可以是核心企业或中小企业。融资额度为100万元以上,融资期限为1个月至3年,融资成本为5%-8%。担保方式包括应收账款质押、信用担保、保证担保等。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"completion_tokens": 179,
"prompt_tokens": 402,
"total_tokens": 581
},
"model_name": "gpt-3.5-turbo",
"system_fingerprint": "fp_4f0b692a78"
},
"run": null
}
[llm/end] [1:chain:ZhCNQAGenerateChain > 3:llm:ChatOpenAI] [17.97s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "QUESTION: 仓单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?融资成本是多少?担保方式有哪些?\nANSWER: 仓单融资产品适用于核心企业和中小企业。融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至3年。融资成本为4%-7%。担保方式包括仓单质押、信用担保、保证担保等。",
"generation_info": {
"finish_reason": "stop",
"logprobs": null
},
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "QUESTION: 仓单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?融资成本是多少?担保方式有哪些?\nANSWER: 仓单融资产品适用于核心企业和中小企业。融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至3年。融资成本为4%-7%。担保方式包括仓单质押、信用担保、保证担保等。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"completion_tokens": 175,
"prompt_tokens": 379,
"total_tokens": 554
},
"model_name": "gpt-3.5-turbo",
"system_fingerprint": "fp_4f0b692a78"
},
"run": null
}
[llm/end] [1:chain:ZhCNQAGenerateChain > 4:llm:ChatOpenAI] [17.97s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "QUESTION: 产品名称为什么是订单融资?产品类型是什么?产品简介是什么?\nANSWER: 产品名称是订单融资,因为该产品是以订单为基础获取融资。产品类型是信用融资。产品简介是以订单为基础获取融资。",
"generation_info": {
"finish_reason": "stop",
"logprobs": null
},
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "QUESTION: 产品名称为什么是订单融资?产品类型是什么?产品简介是什么?\nANSWER: 产品名称是订单融资,因为该产品是以订单为基础获取融资。产品类型是信用融资。产品简介是以订单为基础获取融资。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"completion_tokens": 87,
"prompt_tokens": 362,
"total_tokens": 449
},
"model_name": "gpt-3.5-turbo",
"system_fingerprint": "fp_4f0b692a78"
},
"run": null
}
[llm/end] [1:chain:ZhCNQAGenerateChain > 5:llm:ChatOpenAI] [17.97s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "QUESTION: 什么是动产抵押融资的产品类型和适用场景?融资主体是谁?融资额度和期限是多少?融资成本是多少?担保方式有哪些?\nANSWER: 动产抵押融资的产品类型是动产融资,适用场景是中小企业。融资主体是中小企业,融资额度为50万元以上,融资期限为1个月至3年,融资成本为5%-8%。担保方式包括动产抵押、信用担保、保证担保等。",
"generation_info": {
"finish_reason": "stop",
"logprobs": null
},
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "QUESTION: 什么是动产抵押融资的产品类型和适用场景?融资主体是谁?融资额度和期限是多少?融资成本是多少?担保方式有哪些?\nANSWER: 动产抵押融资的产品类型是动产融资,适用场景是中小企业。融资主体是中小企业,融资额度为50万元以上,融资期限为1个月至3年,融资成本为5%-8%。担保方式包括动产抵押、信用担保、保证担保等。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"completion_tokens": 181,
"prompt_tokens": 367,
"total_tokens": 548
},
"model_name": "gpt-3.5-turbo",
"system_fingerprint": "fp_4f0b692a78"
},
"run": null
}
[llm/end] [1:chain:ZhCNQAGenerateChain > 6:llm:ChatOpenAI] [17.98s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "QUESTION: 保单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?\nANSWER: 保单融资产品适用于核心企业和中小企业,融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至1年。",
"generation_info": {
"finish_reason": "stop",
"logprobs": null
},
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "QUESTION: 保单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?\nANSWER: 保单融资产品适用于核心企业和中小企业,融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至1年。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"completion_tokens": 114,
"prompt_tokens": 364,
"total_tokens": 478
},
"model_name": "gpt-3.5-turbo",
"system_fingerprint": "fp_4f0b692a78"
},
"run": null
}
[llm/end] [1:chain:ZhCNQAGenerateChain > 7:llm:ChatOpenAI] [17.98s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "QUESTION: 什么是流水贷款的产品类型和适用场景?\nANSWER: 流水贷款的产品类型是信用融资,适用场景是核心企业和中小企业。",
"generation_info": {
"finish_reason": "stop",
"logprobs": null
},
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "QUESTION: 什么是流水贷款的产品类型和适用场景?\nANSWER: 流水贷款的产品类型是信用融资,适用场景是核心企业和中小企业。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"completion_tokens": 58,
"prompt_tokens": 344,
"total_tokens": 402
},
"model_name": "gpt-3.5-turbo",
"system_fingerprint": "fp_4f0b692a78"
},
"run": null
}
[chain/end] [1:chain:ZhCNQAGenerateChain] [18.01s] Exiting Chain run with output:
{
"outputs": [
{
"qa_pairs": {
"query": "什么是\"应收账款质押融资\"的产品类型?融资主体是谁?融资额度和期限是多少?融资成本是多少?担保方式有哪些?",
"answer": "\"应收账款质押融资\"的产品类型是动产融资。融资主体可以是核心企业或中小企业。融资额度为100万元以上,融资期限为1个月至3年,融资成本为5%-8%。担保方式包括应收账款质押、信用担保、保证担保等。"
}
},
{
"qa_pairs": {
"query": "仓单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?融资成本是多少?担保方式有哪些?",
"answer": "仓单融资产品适用于核心企业和中小企业。融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至3年。融资成本为4%-7%。担保方式包括仓单质押、信用担保、保证担保等。"
}
},
{
"qa_pairs": {
"query": "产品名称为什么是订单融资?产品类型是什么?产品简介是什么?",
"answer": "产品名称是订单融资,因为该产品是以订单为基础获取融资。产品类型是信用融资。产品简介是以订单为基础获取融资。"
}
},
{
"qa_pairs": {
"query": "什么是动产抵押融资的产品类型和适用场景?融资主体是谁?融资额度和期限是多少?融资成本是多少?担保方式有哪些?",
"answer": "动产抵押融资的产品类型是动产融资,适用场景是中小企业。融资主体是中小企业,融资额度为50万元以上,融资期限为1个月至3年,融资成本为5%-8%。担保方式包括动产抵押、信用担保、保证担保等。"
}
},
{
"qa_pairs": {
"query": "保单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?",
"answer": "保单融资产品适用于核心企业和中小企业,融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至1年。"
}
},
{
"qa_pairs": {
"query": "什么是流水贷款的产品类型和适用场景?",
"answer": "流水贷款的产品类型是信用融资,适用场景是核心企业和中小企业。"
}
}
]
}
[chain/start] [1:chain:RetrievalQA] Entering Chain run with input:
{
"query": "仓单融资的产品的优点是什么?"
}
[chain/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain] Entering Chain run with input:
[inputs]
[chain/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] Entering Chain run with input:
{
"question": "仓单融资的产品的优点是什么?",
"context": "产品名称: 仓单融资\n产品类型: 动产融资\n产品简介: 以仓单为质押品获取融资\n适用场景: 核心企业、中小企业\n融资主体: 核心企业、中小企业\n融资额度: 100万元以上\n融资期限: 1个月-3年\n融资成本: 4%-7%\n担保方式: 仓单质押、信用担保、保证担保等\n风险控制: 货物真实性、权属清晰性、仓储安全等\n优势: 融资便捷、成本较低、盘活存货资产\n案例: 某贸易企业利用仓单融资,获得了500万元的流动资金,用于扩大进出口业务,提高了资金周转效率。\n\n产品名称: 订单融资\n产品类型: 信用融资\n产品简介: 以订单为基础获取融资\n适用场景: 核心企业、中小企业\n融资主体: 核心企业、中小企业\n融资额度: 100万元以上\n融资期限: 1个月-1年\n融资成本: 3%-6%\n担保方式: 订单真实性、买方信用状况等\n风险控制: 订单池管理、风险分散等\n优势: 融资便捷、成本较低、提升供应链协同效率\n案例: 某电商企业利用订单融资,获得了2000万元的流动资金,用于备货发货,满足了订单快速增长的需求。\n\n产品名称: 保单融资\n产品类型: 信用融资\n产品简介: 以保单为质押品获取融资\n适用场景: 核心企业、中小企业\n融资主体: 核心企业、中小企业\n融资额度: 100万元以上\n融资期限: 1个月-1年\n融资成本: 3%-6%\n担保方式: 保单质押、信用担保、保证担保等\n风险控制: 保单真实性、保费支付记录等\n优势: 融资便捷、成本较低、盘活保单资产\n案例: 某制造企业利用保单融资,获得了500万元的流动资金,用于采购原材料,降低了融资成本。\n\n产品名称: 动产抵押融资\n产品类型: 动产融资\n产品简介: 以动产(如设备、车辆等)为质押品获取融资\n适用场景: 中小企业\n融资主体: 中小企业\n融资额度: 50万元以上\n融资期限: 1个月-3年\n融资成本: 5%-8%\n担保方式: 动产抵押、信用担保、保证担保等\n风险控制: 动产权属清晰性、评估价值等\n优势: 融资便捷、提高资产利用率\n案例: 某科技企业利用动产抵押融资,获得了100万元的流动资金,用于研发新产品,提升了企业竞争力。"
}
[llm/start] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] Entering LLM run with input:
{
"prompts": [
"System: Use the following pieces of context to answer the user's question. \nIf you don't know the answer, just say that you don't know, don't try to make up an answer.\n----------------\n产品名称: 仓单融资\n产品类型: 动产融资\n产品简介: 以仓单为质押品获取融资\n适用场景: 核心企业、中小企业\n融资主体: 核心企业、中小企业\n融资额度: 100万元以上\n融资期限: 1个月-3年\n融资成本: 4%-7%\n担保方式: 仓单质押、信用担保、保证担保等\n风险控制: 货物真实性、权属清晰性、仓储安全等\n优势: 融资便捷、成本较低、盘活存货资产\n案例: 某贸易企业利用仓单融资,获得了500万元的流动资金,用于扩大进出口业务,提高了资金周转效率。\n\n产品名称: 订单融资\n产品类型: 信用融资\n产品简介: 以订单为基础获取融资\n适用场景: 核心企业、中小企业\n融资主体: 核心企业、中小企业\n融资额度: 100万元以上\n融资期限: 1个月-1年\n融资成本: 3%-6%\n担保方式: 订单真实性、买方信用状况等\n风险控制: 订单池管理、风险分散等\n优势: 融资便捷、成本较低、提升供应链协同效率\n案例: 某电商企业利用订单融资,获得了2000万元的流动资金,用于备货发货,满足了订单快速增长的需求。\n\n产品名称: 保单融资\n产品类型: 信用融资\n产品简介: 以保单为质押品获取融资\n适用场景: 核心企业、中小企业\n融资主体: 核心企业、中小企业\n融资额度: 100万元以上\n融资期限: 1个月-1年\n融资成本: 3%-6%\n担保方式: 保单质押、信用担保、保证担保等\n风险控制: 保单真实性、保费支付记录等\n优势: 融资便捷、成本较低、盘活保单资产\n案例: 某制造企业利用保单融资,获得了500万元的流动资金,用于采购原材料,降低了融资成本。\n\n产品名称: 动产抵押融资\n产品类型: 动产融资\n产品简介: 以动产(如设备、车辆等)为质押品获取融资\n适用场景: 中小企业\n融资主体: 中小企业\n融资额度: 50万元以上\n融资期限: 1个月-3年\n融资成本: 5%-8%\n担保方式: 动产抵押、信用担保、保证担保等\n风险控制: 动产权属清晰性、评估价值等\n优势: 融资便捷、提高资产利用率\n案例: 某科技企业利用动产抵押融资,获得了100万元的流动资金,用于研发新产品,提升了企业竞争力。\nHuman: 仓单融资的产品的优点是什么?"
]
}
[llm/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain > 5:llm:ChatOpenAI] [1.78s] Exiting LLM run with output:
{
"generations": [
[
{
"text": "仓单融资的产品优点包括融资便捷、成本较低、以及盘活存货资产。",
"generation_info": {
"finish_reason": "stop",
"logprobs": null
},
"type": "ChatGeneration",
"message": {
"lc": 1,
"type": "constructor",
"id": [
"langchain",
"schema",
"messages",
"AIMessage"
],
"kwargs": {
"content": "仓单融资的产品优点包括融资便捷、成本较低、以及盘活存货资产。",
"additional_kwargs": {}
}
}
}
]
],
"llm_output": {
"token_usage": {
"completion_tokens": 40,
"prompt_tokens": 1065,
"total_tokens": 1105
},
"model_name": "gpt-3.5-turbo",
"system_fingerprint": "fp_4f0b692a78"
},
"run": null
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain > 4:chain:LLMChain] [1.78s] Exiting Chain run with output:
{
"text": "仓单融资的产品优点包括融资便捷、成本较低、以及盘活存货资产。"
}
[chain/end] [1:chain:RetrievalQA > 3:chain:StuffDocumentsChain] [1.80s] Exiting Chain run with output:
{
"output_text": "仓单融资的产品优点包括融资便捷、成本较低、以及盘活存货资产。"
}
[chain/end] [1:chain:RetrievalQA] [2.90s] Exiting Chain run with output:
{
"result": "仓单融资的产品优点包括融资便捷、成本较低、以及盘活存货资产。"
}
{'query': '仓单融资的产品的优点是什么?', 'result': '仓单融资的产品优点包括融资便捷、成本较低、以及盘活存货资产。'}
设置全局debug后,可以看到整个上下文检索的过程,还可以看到token的消耗情况;最终得到的答案比手动测试用例多了盘活存货资产的描述
使用LLM进行评估
用openai语言模型生成问答对,并回答这些问题;用ollama后端的qwen:7b语言模型进行答案判断
# flake8: noqa
from langchain.globals import set_debug
from langchain_openai.chat_models import ChatOpenAI
from langchain_community.llms.ollama import Ollama
from langchain_community.document_loaders.csv_loader import CSVLoader
from langchain_community.vectorstores.docarray import DocArrayInMemorySearch
from langchain_openai import OpenAIEmbeddings
from langchain.indexes import VectorstoreIndexCreator
from langchain.chains import RetrievalQA
from langchain.evaluation.qa import QAGenerateChain, QAEvalChain
from langchain.base_language import BaseLanguageModel
from langchain.prompts import PromptTemplate
from typing import Any
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
ollama_url = "http://127.0.0.1:11434"
template = """You are a teacher coming up with questions to ask on a quiz.
Given the following document, please generate a question and answer based on that document.
Example Format:
<Begin Document>
...
<End Document>
QUESTION: question here
ANSWER: answer here
These questions should be detailed and be based explicitly on information in the document. Begin!
<Begin Document>
{doc}
<End Document>
请使用中文输出
"""
PROMPT = PromptTemplate(
input_variables=["doc"],
template=template,
)
# 继承QAGenerateChain,重写from_llm方法
class ZhCNQAGenerateChain(QAGenerateChain):
"""LLM Chain for generating examples for question answering."""
@classmethod
def from_llm(cls, llm: BaseLanguageModel, **kwargs: Any) -> QAGenerateChain:
"""Load QA Generate Chain from LLM."""
return cls(llm=llm, prompt=PROMPT, **kwargs)
def main():
# 关闭LangChain全局debug
set_debug(False)
# 1.使用LangChain文档加载器csv类型对数据进行导入
file = "/Users/iceyao/Desktop/test_101.csv"
csv_loader = CSVLoader(file_path=file)
docs = csv_loader.load()
# 2.基于文档加载器创建LangChain向量存储索引,这里使用向量内存存储
index = VectorstoreIndexCreator(
vectorstore_cls=DocArrayInMemorySearch,
embedding=OpenAIEmbeddings(
api_key=api_key,
base_url=openai_url)).from_loaders([csv_loader])
# 3.声明OpenAI语言模型,用于自动生成LLM问答用例
openai_llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 4.声明ollama模型(实际是llama2:13b),用于评估问答答案
ollama_llm = Ollama(base_url=ollama_url,
temperature=0,
model="qwen:7b"
)
# 5.声明检索QA链
retrieval_qa_chain = RetrievalQA.from_chain_type(
llm=openai_llm,
retriever=index.vectorstore.as_retriever(),
chain_type="stuff",
verbose=True,
)
# 6.声明ZhCNQAGenerateChain链,基于QA生成链
qa_generate_chain = ZhCNQAGenerateChain.from_llm(openai_llm)
# 7.ZhCNQAGenerateChain链调用apply方法自动创建问答对
llm_examples = qa_generate_chain.apply([{"doc": t} for t in docs])
examples = [v for item in llm_examples for _, v in item.items()]
# 8.检索QA链为测试用例生成预测
predictions = retrieval_qa_chain.batch(examples) # type: ignore[misc]
# 9.声明QA评估链
qa_eval_chain = QAEvalChain.from_llm(ollama_llm)
# 10.QA评估链对其进行评估
evaluate_results = qa_eval_chain.evaluate(examples, predictions) # type: ignore[misc]
for i, _ in enumerate(examples):
print(f"Example {i}:")
print("Question: " + predictions[i]['query'])
print("Real Answer: " + predictions[i]['answer'])
print("Predicted Answer: " + predictions[i]['result'])
print("Predicted Grade: " + evaluate_results[i]['results'])
print()
if __name__ == "__main__":
main()
输出:
> Entering new RetrievalQA chain...
> Entering new RetrievalQA chain...
> Entering new RetrievalQA chain...
> Entering new RetrievalQA chain...
> Entering new RetrievalQA chain...
> Entering new RetrievalQA chain...
> Finished chain.
> Finished chain.
> Finished chain.
> Finished chain.
> Finished chain.
> Finished chain.
Example 0:
Question: 什么是“应收账款质押融资”产品的主要特点和优势?请列举至少三点。
Real Answer: 该产品的主要特点和优势包括:以应收账款为质押品获取融资、适用于核心企业和中小企业、融资额度在100万元以上、融资期限为1个月至3年、融资成本在5%-8%之间、担保方式包括应收账款质押、信用担保、保证担保等、风险控制主要关注应收账款真实性、债权清晰性、履约能力等、优势在于融资便捷、成本较低、提高资金利用率。
Predicted Answer: “应收账款质押融资”产品的主要特点和优势包括:
1. **融资便捷**:通过将应收账款作为质押品,企业可以相对容易地获取融资,无需进行繁琐的审批流程,提高了融资的速度和效率。
2. **成本较低**:相比其他融资方式,应收账款质押融资的成本通常在5%-8%之间,相对较低,有助于降低企业的融资成本,提升盈利能力。
3. **提高资金利用率**:通过将应收账款作为质押品获得融资,企业可以有效地利用未来的收款权益,提前获取资金用于业务发展,提高了资金的利用效率和灵活性。
Predicted Grade: CORRECT
Example 1:
Question: 仓单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?融资成本是多少?担保方式有哪些?
Real Answer: 仓单融资产品适用于核心企业和中小企业。融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至3年。融资成本为4%-7%。担保方式包括仓单质押、信用担保、保证担保等。
Predicted Answer: 仓单融资产品的适用场景是核心企业和中小企业。融资主体也是核心企业和中小企业。融资额度是100万元以上,融资期限为1个月到3年。融资成本为4%-7%。担保方式包括仓单质押、信用担保、保证担保等。
Predicted Grade: CORRECT
Example 2:
Question: 什么是订单融资的产品简介和适用场景?融资额度和期限是多少?融资成本是多少?担保方式和风险控制措施是什么?
Real Answer: 订单融资是以订单为基础获取融资的信用融资产品,适用于核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至1年,融资成本为3%-6%。担保方式包括订单真实性和买方信用状况等,风险控制措施包括订单池管理和风险分散。
Predicted Answer: 订单融资的产品简介是以订单为基础获取融资,适用场景是核心企业和中小企业。融资额度是100万元以上,融资期限为1个月到1年,融资成本为3%-6%。担保方式包括订单真实性和买方信用状况等,风险控制措施包括订单池管理和风险分散等。
Predicted Grade: CORRECT
Example 3:
Question: 什么是动产抵押融资的产品简介?
Real Answer: 以动产(如设备、车辆等)为质押品获取融资
Predicted Answer: 动产抵押融资的产品简介是以动产(如设备、车辆等)作为质押品来获取融资。
Predicted Grade: CORRECT
Example 4:
Question: 保单融资产品的适用场景是什么?融资主体是谁?融资额度和期限分别是多少?融资成本是多少?担保方式有哪些?
Real Answer: 保单融资产品适用于核心企业和中小企业,融资主体也是核心企业和中小企业。融资额度为100万元以上,融资期限为1个月至1年,融资成本为3%-6%。担保方式包括保单质押、信用担保、保证担保等。
Predicted Answer: 保单融资产品的适用场景是核心企业和中小企业。融资主体是核心企业和中小企业。融资额度是100万元以上,融资期限是1个月到1年。融资成本是3%-6%。担保方式包括保单质押、信用担保、保证担保等。
Predicted Grade: CORRECT
Example 5:
Question: 请问流水贷款的产品类型是什么?
Real Answer: 信用融资
Predicted Answer: 流水贷款的产品类型是信用融资。
Predicted Grade: CORRECT
从输出结果来看的话,每一个Example中包含了Question、Real Answer、Predicted Answer、Predicted Grade,Real Answer是 QA生成链基于openai语言模型生成的,Real Answer是QA检索链基于openai语言模型回答的,Predicted Grade是QA评估链基于qwen:7b语言模型 生成的。全自动的评估方式极大地简化了问答系统的评估和优化过程,开发者无需手动准备测试用例,也无需逐一判断正确性。
代理Agent
代理作为语言模型的外部模块,可提供计算、逻辑、检索等功能的支持,使语言模型获得异常强大的推理和获取信息的超能力。LangChain的agent跟AI agent不是同一个概念。
AI agent、大模型、LangChain之间的关系? AI agent是一种能够感知环境、进行决策和执行动作的智能实体。大模型相当于是AI agent的大脑,LangChain是快速构建AI agent的框架平台。AI agent~=大模型+插件+执行流程,对应人体的控制端、感知端、执行端
Agent类型区别:https://python.langchain.com/docs/modules/agents/agent_types/
使用llm-math/wikipedia工具
使用代理,需要满足三个条件:
- 一个基础的LLM
- 进行交互的工具Tools
- 控制交互的代理Agents
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_tools_agent, load_tools
from pydantic import SecretStr
from langchain import hub
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
# 初始化一个基础的LLM
llm = ChatOpenAI(
temperature=0.0,
base_url=openai_url,
api_key=api_key,
streaming=True,
verbose=True,
)
# 初始化工具,这里用到两个内置工具
# llm-math: 工具结合语言模型和计算器用以进行数学计算
# wikipedia: 工具通过API连接到wikipedia进行搜索查询
tools = load_tools(tool_names=["llm-math", "wikipedia"], llm=llm)
# 从hub上拉取prompt模版
prompt = hub.pull("hwchase17/openai-tools-agent")
# 初始化agent
agent = create_openai_tools_agent(llm, tools, prompt)
# 运行agent
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True)
agent_executor.invoke({"input": "计算300的25%"})
agent_executor.invoke({"input": "曹德旺做了哪些善事"})
if __name__ == "__main__":
main()
输出:
> Entering new AgentExecutor chain...
Invoking: `Calculator` with `300*0.25`
Answer: 75.025% of 300 is 75.
> Finished chain.
> Entering new AgentExecutor chain...
Invoking: `wikipedia` with `曹德旺`
Page: Cao Dewang
Summary: Cao Dewang (Chinese: 曹德旺; pinyin: Cáo Déwàng; born May 1946), also known as Cho Tak Wong or Tak Wong Cho, is a Chinese entrepreneur. He is the chairman of Fuyao Group, one of the largest glass manufacturers in the world. He is also a member of the Chinese People's Consultative Conference from Fujian, and chairman of both the China Automobile Glass Association and the Fujian Golf Players' Association.
Page: Jack Wong
Summary: Jack Wong, or Huang Zhang (Chinese: 黄章; pinyin: Huáng Zhāng), is a Chinese billionaire entrepreneur. He is the founder and chairman of Meizu, a Chinese consumer electronics company.
Page: Crocodile Island (film)
Summary: Crocodile Island is a 2020 Chinese action monster film directed by Xu Shixing and Simon Zhao, and starring Gallen Lo as a single father who lands on a crocodile island with his daughter (Liao Yinyue) due to a plane malfunction and must battle with beast-sized creatures inhabiting the island. This web film was released for online streaming on 4 February 2020 on iQiyi. Crocodile Island became a commercial success, grossing ¥16.70 million against a budget of ¥8 million and is currently the highest-grossing web film of 2020 in China.根据维基百科,曹德旺是中国企业家,福耀集团董事长,也是中国汽车玻璃协会和福建高尔夫球员协会的主席。关于他做了哪些善事的具体信息可能需要更深入的研究。您是否希望我帮助您进一步了解曹德旺的善举?
> Finished chain.
使用PythonREPLTool工具
使用PythonREPLTool工具将名字转化为拼音
from langchain_openai import ChatOpenAI
from langchain_experimental.agents.agent_toolkits.python.base import create_python_agent
from langchain_experimental.tools import PythonREPLTool
from pydantic import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
base_url=openai_url,
api_key=api_key,
streaming=True,
verbose=True,
)
tool = PythonREPLTool()
agent = create_python_agent(
llm, tool, verbose=True)
customer_list = ["张三", "李四", "王五"]
agent.invoke(
{"input": f"使用pinyin拼音库这些客户名字转换为拼音,并打印输出列表: {customer_list}。"})
if __name__ == "__main__":
main()
输出:
> Entering new AgentExecutor chain...
I need to use the pinyin library to convert the names to pinyin.
Action: Python_REPL
Action Input:
```python
from pypinyin import pinyin
names = ['张三', '李四', '王五']
pinyin_names = ["".join([y[0] for y in x]) for x in [pinyin(name, style=0) for name in names]]
print(pinyin_names)
```Python REPL can execute arbitrary code. Use with caution.
Observation: ['zhangsan', 'lisi', 'wangwu']
Thought:The names have been successfully converted to pinyin.
Final Answer: ['zhangsan', 'lisi', 'wangwu']
> Finished chain.
从输出结果来看,可以看出agent自主决策的一个过程
自定义工具
LangChain tool函数装饰器可以应用于任何函数,将函数转化为LangChain工具,成为agent可以调用的工具. 这里以创建自定义时间的工具为例:
from langchain.agents import tool
from langchain_openai import ChatOpenAI
from langchain.agents import AgentExecutor, create_openai_tools_agent
from pydantic import SecretStr
from datetime import date
from langchain import hub
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
@tool
def time(text: str) -> str:
"""
"""
return str(date.today())
def main():
llm = ChatOpenAI(
temperature=0.0,
base_url=openai_url,
api_key=api_key,
streaming=True,
verbose=True,
)
tools = [time]
# 从hub上拉取prompt模版
prompt = hub.pull("hwchase17/openai-tools-agent")
# 初始化agent
agent = create_openai_tools_agent(llm, tools, prompt)
# 运行agent
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True)
agent_executor.invoke({"input": "今天的日期是多少"})
if __name__ == "__main__":
main()
输出:
> Entering new AgentExecutor chain...
Invoking: `time` with `{'text': 'today'}`
2024-03-27今天是2024年3月27日。
> Finished chain.
LCEL(LangChain Expression Language)
LangChain表达式语言(LCEL)是一种轻松地将链组合在一起的声明性方式。 LCEL 从第一天起就被设计为支持将原型投入生产,无需更改代码,从最简单的“提示+LLM”链到最复杂的链
LangSmith
LangSmith是一个为构建生产级别的大型语言模型(LLM)应用程序而设计的平台。由 LangChain团队开发。不能私有化部署,提供类似SaaS服务,它提供了密切监控和评估应用程序的功能,帮助开发者快速且自信地发布应用。此外LangSmith可以独立运作,不依赖于LangChain。
安装langsmith包
pip install -U langsmith
在LangSmith上https://smith.langchain.com/settings创建API Key,并声明
export LANGCHAIN_TRACING_V2=true
export LANGCHAIN_API_KEY=<your-api-key>
export LANGCHAIN_PROJECT=default
import openai
from langsmith.wrappers import wrap_openai
from langsmith import traceable
# Auto-trace LLM calls in-context
client = wrap_openai(openai.Client(
api_key="sk-xxx",
base_url="https://api.chatanywhere.tech/v1/" # 国内代理
))
@traceable # Auto-trace this function
def pipeline(user_input: str):
result = client.chat.completions.create(
messages=[{"role": "user", "content": user_input}],
model="gpt-3.5-turbo"
)
return result.choices[0].message.content
pipeline("Hello, world!")
# Out: Hello there! How can I assist you today?
运行完后,https://smith.langchain.com/上会有对应链路跟踪信息
LangFuse
Langfuse 是一个专为基于大型语言模型 (LLMs) 的应用程序设计的开源观测和分析平台。支持私有化部署。
docker-compose部署
# Clone repository
git clone https://github.com/langfuse/langfuse.git
cd langfuse
# Run server and database
docker-compose up -d
默认访问服务器的3000端口http://<server-ip>:3000/
安装langfuse python sdk
pip install langfuse openai
使用langfuse装饰器快速集成,运行完在http://<server-ip>:3000/上可以看到调用信息
from langfuse.decorators import observe
from langfuse.openai import openai # OpenAI integration
import os
os.environ["LANGFUSE_SECRET_KEY"] = "sk-lf-a7ac8caf-24f2-433f-8b82-0b66d0afd238"
os.environ["LANGFUSE_PUBLIC_KEY"] = "pk-lf-066d7968-4c93-497b-b0aa-9d825571fa4d"
os.environ["LANGFUSE_HOST"] = "http://<server-ip>:3000"
@observe()
def story():
openai.api_key = "sk-xxx"
openai.base_url = "https://api.chatanywhere.tech/v1/"
return openai.chat.completions.create(
model="gpt-3.5-turbo",
max_tokens=100,
messages=[
{"role": "system", "content": "你是一个写作专家"},
{"role": "user", "content": "请写一篇2000字的旅游文章"}
],
).choices[0].message.content
@observe()
def main():
return story()
main()
Use Cases
来自于Langchain官网的quickstart例子:https://python.langchain.com/docs/use_cases
RAG问答
RAG架构
RAG应用有两个核心组件:
- 索引
- 检索和生成
建立索引过程:
- Load:第一步加载数据,使用
DocumentLoaders - Split:使用文本分割器把大文档切分成小的chunk,用于建立索引数据和传入大模型,因为大chunk检索困难、模型有上下文窗口长度限制
- Store:我们需要存储和索引这些分割的文本,这步通常使用向量存储和Embedding模型。

检索和生成过程:
- Retrieve:根据用户输入,使用
Retriever检索器从存储中检索出相关的分割文本 - Generate:根据问题、检索到的数据生成Prompt发送至聊天模型/LLM,聊天模型/LLM生成相应的回答
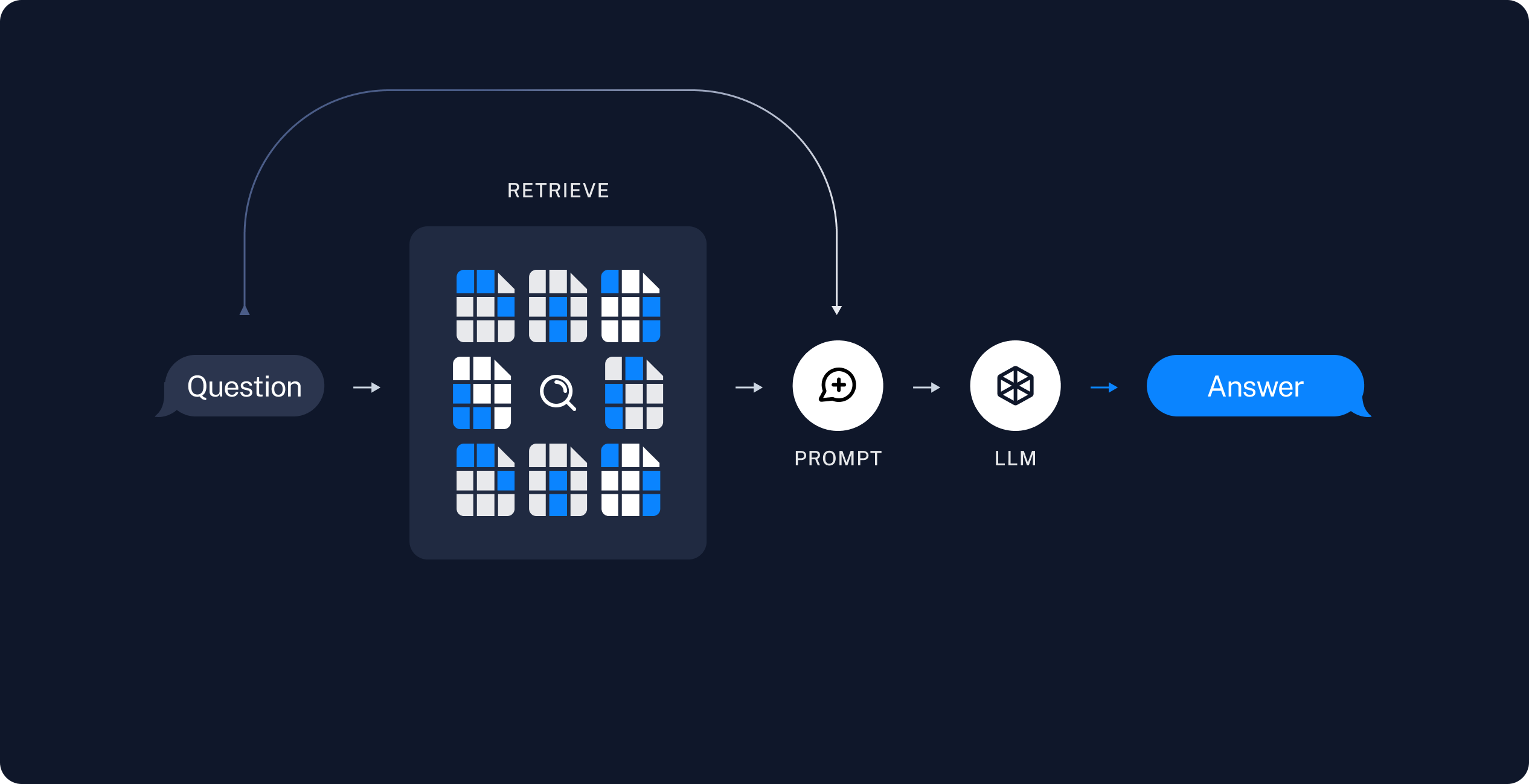
代码实现
安装依赖
# pip install --upgrade --quiet langchain langchain-community langchainhub langchain-openai langchain-chroma bs4
一个quickstart例子
import bs4
from langchain import hub
from langchain_community.document_loaders.web_base import WebBaseLoader
from langchain_chroma import Chroma
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnablePassthrough
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# Load, chunk and index the contents of the blog.
loader = WebBaseLoader(
web_paths=("https://lilianweng.github.io/posts/2023-06-23-agent/",),
bs_kwargs=dict(
parse_only=bs4.SoupStrainer(
class_=("post-content", "post-title", "post-header")
)
),
)
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200)
splits = text_splitter.split_documents(docs)
vectorstore = Chroma.from_documents(
documents=splits, embedding=OpenAIEmbeddings(
api_key=api_key,
base_url=openai_url
))
# Retrieve and generate using the relevant snippets of the blog.
retriever = vectorstore.as_retriever()
prompt = hub.pull("rlm/rag-prompt")
def format_docs(docs):
return "\n\n".join(doc.page_content for doc in docs)
rag_chain = (
{"context": retriever | format_docs, "question": RunnablePassthrough()}
| prompt
| llm
| StrOutputParser()
)
print(rag_chain.invoke("What is Task Decomposition?"))
vectorstore.delete_collection()
if __name__ == "__main__":
main()
输出:
Task Decomposition is a technique used to break down complex tasks into smaller and simpler steps. This process helps agents or models better understand and tackle the task at hand by dividing it into manageable parts. It can be implemented through prompting techniques like Chain of Thought or Tree of Thoughts, task-specific instructions, or human inputs.
提取结构化输出
一个quickstart的例子,要使用支持function/tool调用能力的聊天模型,还可以通过langchain.output_parsers的方式来处理结构化输出
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
from typing import List, Optional
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.pydantic_v1 import BaseModel, Field
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
class Person(BaseModel):
"""Information about a person."""
# ^ Doc-string for the entity Person.
# This doc-string is sent to the LLM as the description of the schema Person,
# and it can help to improve extraction results.
# Note that:
# 1. Each field is an `optional` -- this allows the model to decline to extract it!
# 2. Each field has a `description` -- this description is used by the LLM.
# Having a good description can help improve extraction results.
name: Optional[str] = Field(default=None, description="The name of the person")
hair_color: Optional[str] = Field(
default=None, description="The color of the peron's hair if known"
)
height_in_meters: Optional[str] = Field(
default=None, description="Height measured in meters"
)
class Data(BaseModel):
"""Extracted data about people."""
# Creates a model so that we can extract multiple entities.
people: List[Person]
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# Define a custom prompt to provide instructions and any additional context.
# 1) You can add examples into the prompt template to improve extraction quality
# 2) Introduce additional parameters to take context into account (e.g., include metadata
# about the document from which the text was extracted.)
prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"You are an expert extraction algorithm. "
"Only extract relevant information from the text. "
"If you do not know the value of an attribute asked to extract, "
"return null for the attribute's value.",
),
# Please see the how-to about improving performance with
# reference examples.
# MessagesPlaceholder('examples'),
("human", "{text}"),
]
)
runnable = prompt | llm.with_structured_output(schema=Data)
text = "My name is Jeff, my hair is black and i am 6 feet tall. Anna has the same color hair as me."
print(runnable.invoke({"text": text}))
if __name__ == "__main__":
main()
输出:
people=[Person(name='Jeff', hair_color='black', height_in_meters='1.83'), Person(name='Anna', hair_color='black', height_in_meters=None)]
对话检索机器人
聊天机器人是LLM最流行的应用场景之一,聊天机器人的核心特征是它们可以进行长时间运行的、有状态的对话,并可以使用相关信息回答用户问题。
架构
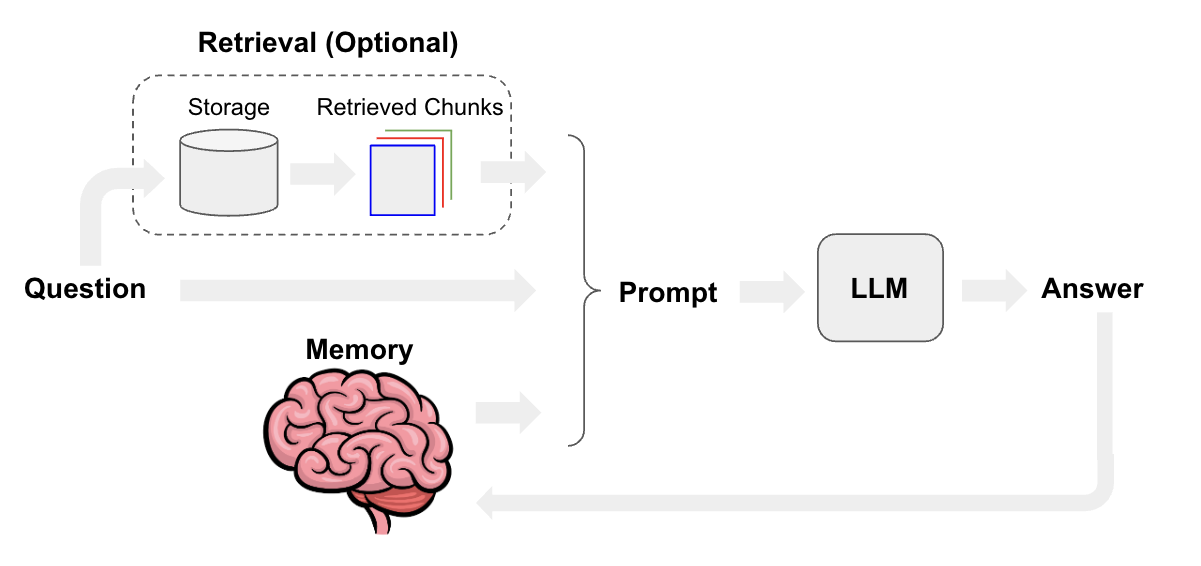 聊天机器人通常对私有数据使用检索增强生成(RAG),以更好地回答特定领域的问题。您还可以选择在多个数据源之间进行路由,以确保它仅使用最热门的上下文来回答最终问题,或者选择使用更专业类型的聊天历史记录或内存,而不仅仅是来回传递消息。
聊天机器人通常对私有数据使用检索增强生成(RAG),以更好地回答特定领域的问题。您还可以选择在多个数据源之间进行路由,以确保它仅使用最热门的上下文来回答最终问题,或者选择使用更专业类型的聊天历史记录或内存,而不仅仅是来回传递消息。
代码实现
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableBranch
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_community.document_loaders.web_base import WebBaseLoader
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.runnables import RunnablePassthrough
from langchain.memory import ChatMessageHistory
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
chat = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
data = loader.load()
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500, chunk_overlap=0)
all_splits = text_splitter.split_documents(data)
vectorstore = Chroma.from_documents(documents=all_splits, embedding=OpenAIEmbeddings(
api_key=api_key, base_url=openai_url))
retriever = vectorstore.as_retriever(k=4)
query_transform_prompt = ChatPromptTemplate.from_messages(
[
MessagesPlaceholder(variable_name="messages"),
(
"user",
"Given the above conversation, generate a search query to look up in order to get information relevant to the conversation. Only respond with the query, nothing else.",
),
]
)
question_answering_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Answer the user's questions based on the below context:\n\n{context}",
),
MessagesPlaceholder(variable_name="messages"),
]
)
query_transforming_retriever_chain = RunnableBranch(
(
lambda x: len(x.get("messages", [])) == 1,
# If only one message, then we just pass that message's content to retriever
(lambda x: x["messages"][-1].content) | retriever,
),
# If messages, then we pass inputs to LLM chain to transform the query, then pass to retriever
query_transform_prompt | chat | StrOutputParser() | retriever,
).with_config(run_name="chat_retriever_chain")
document_chain = create_stuff_documents_chain(
chat, question_answering_prompt)
conversational_retrieval_chain = RunnablePassthrough.assign(
context=query_transforming_retriever_chain,
).assign(
answer=document_chain,
)
demo_ephemeral_chat_history = ChatMessageHistory()
demo_ephemeral_chat_history.add_user_message(
"how can langsmith help with testing?")
response = conversational_retrieval_chain.invoke(
{"messages": demo_ephemeral_chat_history.messages},
)
demo_ephemeral_chat_history.add_ai_message(response["answer"])
demo_ephemeral_chat_history.add_user_message("tell me more about that!")
print(conversational_retrieval_chain.invoke(
{"messages": demo_ephemeral_chat_history.messages}
))
if __name__ == "__main__":
main()
输出:
{'messages': [HumanMessage(content='how can langsmith help with testing?'), AIMessage(content="LangSmith is designed to aid in the development and testing of production-grade large language model (LLM) applications. Here's how it can help with testing:\n\n1. **Monitoring and Evaluation**: LangSmith allows you to closely monitor and evaluate your LLM application during testing. This means you can track its performance, identify any issues or bottlenecks, and make necessary improvements before deployment.\n\n2. **Tracing Capabilities**: With LangSmith, you can utilize its tracing capabilities to trace the execution of your LLM application. This helps in understanding how the application behaves under different inputs and scenarios, which is crucial for testing and debugging.\n\n3. **Prompt Hub**: LangSmith includes a Prompt Hub, which is a prompt management tool. This can be useful during testing as it helps in managing and organizing prompts for your LLM application, making it easier to iterate and test different inputs.\n\n4. **Proxy**: LangSmith offers proxy capabilities, which can be utilized to control and manage access to your LLM application during testing. This ensures that only authorized users or systems can interact with the application, enhancing security and control during testing phases.\n\n5. **Cookbook and Additional Resources**: LangSmith provides a Cookbook, which is a collection of tutorials and walkthroughs. These resources can guide you through the testing process, providing best practices and tips for testing LLM applications effectively.\n\nOverall, LangSmith offers a comprehensive set of tools and capabilities to support testing of LLM applications, enabling developers to ship quickly and with confidence."), HumanMessage(content='tell me more about that!')], 'context': [Document(page_content='Skip to main contentLangSmith API DocsSearchGo to AppQuick StartUser GuideTracingEvaluationProduction Monitoring & AutomationsPrompt HubProxyPricingSelf-HostingCookbookQuick StartOn this pageGetting started with LangSmithIntroduction\u200bLangSmith is a platform for building production-grade LLM applications. It allows you to closely monitor and evaluate your application, so you can ship quickly and with confidence. Use of LangChain is not necessary - LangSmith works on its own!Install LangSmith\u200bWe', metadata={'description': 'Introduction', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'Getting started with LangSmith | 🦜️🛠️ LangSmith'}), Document(page_content='LangSmith.Self-Hosting: Learn about self-hosting options for LangSmith.Proxy: Learn about the proxy capabilities of LangSmith.Tracing: Learn about the tracing capabilities of LangSmith.Evaluation: Learn about the evaluation capabilities of LangSmith.Prompt Hub Learn about the Prompt Hub, a prompt management tool built into LangSmith.Additional Resources\u200bLangSmith Cookbook: A collection of tutorials and end-to-end walkthroughs using LangSmith.LangChain Python: Docs for the Python LangChain', metadata={'description': 'Introduction', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'Getting started with LangSmith | 🦜️🛠️ LangSmith'}), Document(page_content='Getting started with LangSmith | 🦜️🛠️ LangSmith', metadata={'description': 'Introduction', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'Getting started with LangSmith | 🦜️🛠️ LangSmith'}), Document(page_content='goes here datasetName, // The data to predict and grade over { evaluationConfig: { customEvaluators: [exactMatch] }, projectMetadata: { version: "1.0.0", revision_id: "beta", }, });See more on the evaluation quick start page.Next Steps\u200bCheck out the following sections to learn more about LangSmith:User Guide: Learn about the workflows LangSmith supports at each stage of the LLM application lifecycle.Pricing: Learn about the pricing model for', metadata={'description': 'Introduction', 'language': 'en', 'source': 'https://docs.smith.langchain.com/overview', 'title': 'Getting started with LangSmith | 🦜️🛠️ LangSmith'})], 'answer': "Sure, let's dive deeper into each aspect of how LangSmith can help with testing:\n\n1. **Monitoring and Evaluation**: LangSmith allows you to monitor various metrics and evaluate the performance of your LLM application during testing. This includes tracking metrics such as accuracy, response time, resource utilization, and more. By closely monitoring these metrics, you can identify any issues or areas for improvement in your application's performance.\n\n2. **Tracing Capabilities**: Tracing capabilities in LangSmith enable you to trace the execution flow of your LLM application. This means you can track how the application processes input prompts, generates responses, and executes various tasks. Tracing helps in understanding the behavior of the application under different conditions, which is essential for thorough testing and debugging.\n\n3. **Prompt Hub**: The Prompt Hub is a built-in tool in LangSmith for managing prompts used in your LLM application. During testing, you can use the Prompt Hub to organize and manage different test cases and input prompts. This makes it easier to iterate on testing scenarios, compare results, and refine your LLM model based on testing feedback.\n\n4. **Proxy**: LangSmith's proxy capabilities provide control and management over access to your LLM application. This is particularly useful during testing when you want to restrict access to the application to specific users or systems. By using the proxy features, you can ensure that testing environments are properly controlled and secured, reducing the risk of unauthorized access or misuse.\n\n5. **Cookbook and Additional Resources**: The LangSmith Cookbook and additional resources provide tutorials, walkthroughs, and best practices for testing LLM applications. These resources cover various aspects of testing, including setting up test environments, designing test cases, interpreting test results, and optimizing performance. By leveraging these resources, you can improve the effectiveness and efficiency of your testing processes.\n\nOverall, LangSmith offers a comprehensive suite of tools and resources to support testing of LLM applications at every stage of development. From monitoring and evaluation to tracing, prompt management, proxying, and access to helpful documentation, LangSmith empowers developers to conduct thorough testing and ensure the reliability and performance of their LLM applications before deployment."}
工具使用&代理
使用工具有两种主要方式:
- 链(chains)
- 代理(agents)
架构
链中调用工具

Agent中调用工具

代码实现
链中调用工具
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
from langchain_core.tools import tool
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
llm_with_tools = llm.bind_tools([multiply])
# 直接函数/工具调用
msg = llm_with_tools.invoke("whats 5 times forty two")
print(msg.tool_calls)
# 链中调用工具
chain = llm_with_tools | (lambda x: x.tool_calls[0]["args"]) | multiply
print(chain.invoke("What's four times 23"))
if __name__ == "__main__":
main()
输出:
[{'name': 'multiply', 'args': {'first_int': 5, 'second_int': 42}, 'id': 'call_tYHGZbXVcZo2KTHTF9PGTEW3'}]
92
Agent中调用工具
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
from langchain_core.tools import tool
from langchain import hub
from langchain.agents import AgentExecutor, create_tool_calling_agent
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
@tool
def multiply(first_int: int, second_int: int) -> int:
"""Multiply two integers together."""
return first_int * second_int
@tool
def add(first_int: int, second_int: int) -> int:
"Add two integers."
return first_int + second_int
@tool
def exponentiate(base: int, exponent: int) -> int:
"Exponentiate the base to the exponent power."
return base**exponent
def main():
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# Get the prompt to use - can be replaced with any prompt that includes variables "agent_scratchpad" and "input"!
prompt = hub.pull("hwchase17/openai-tools-agent")
tools = [multiply, add, exponentiate]
# Construct the tool calling agent
agent = create_tool_calling_agent(llm, tools, prompt)
# Create an agent executor by passing in the agent and tools
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "Take 3 to the fifth power and multiply that by the sum of twelve and three, then square the whole result"
}
)
if __name__ == "__main__":
main()
输出:
> Entering new AgentExecutor chain...
Invoking: `exponentiate` with `{'base': 3, 'exponent': 5}`
243
Invoking: `add` with `{'first_int': 12, 'second_int': 3}`
15
Invoking: `multiply` with `{'first_int': 243, 'second_int': 15}`
3645
Invoking: `exponentiate` with `{'base': 3645, 'exponent': 2}`
13286025The result of taking 3 to the fifth power and multiplying that by the sum of twelve and three, then squaring the whole result is 13,286,025.
> Finished chain.
查询分析
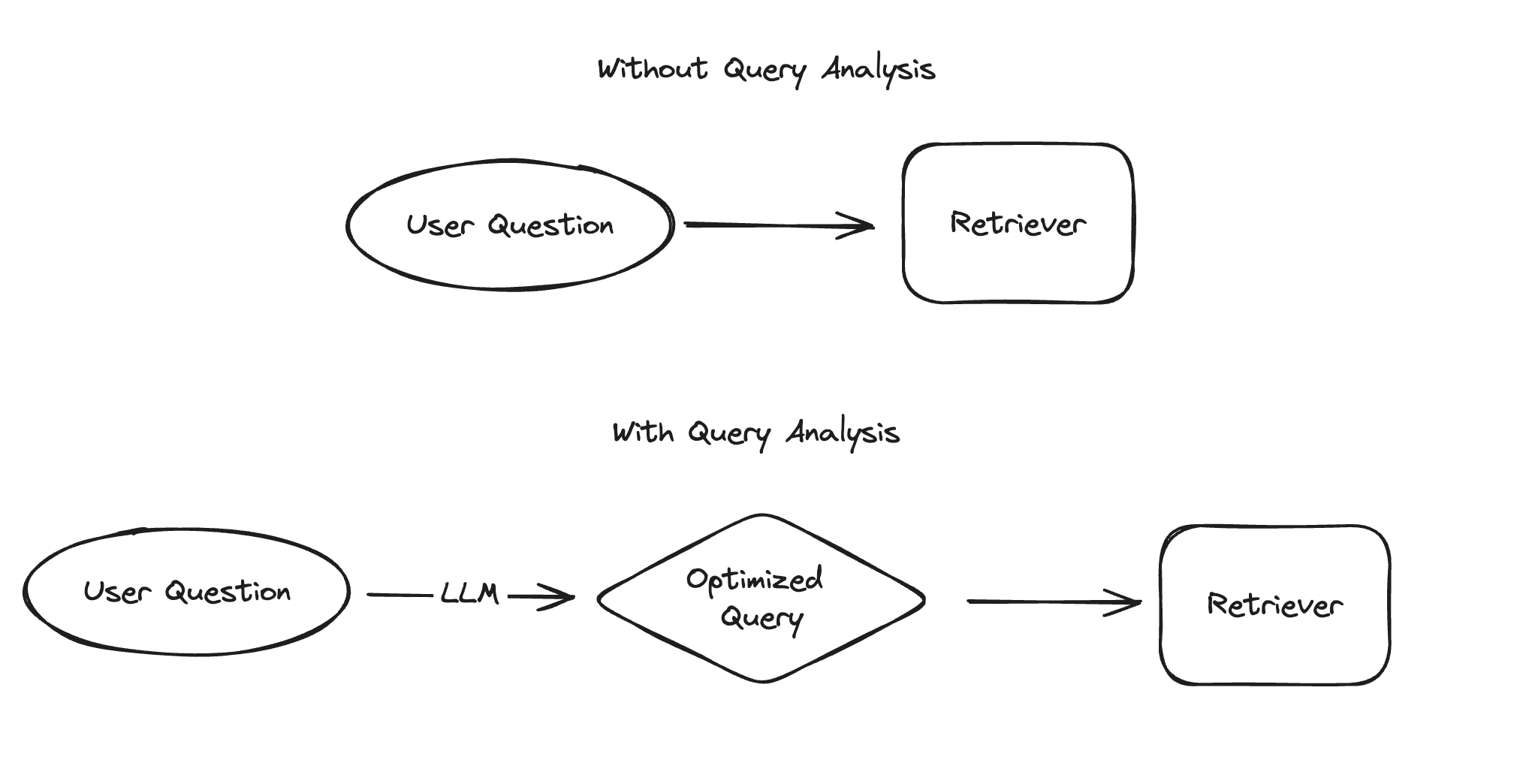 使用查询分析可以在某些方面上提高查询的质量,借助LLM已经变成一种越来越流行的方式针对问答场景。
使用查询分析可以在某些方面上提高查询的质量,借助LLM已经变成一种越来越流行的方式针对问答场景。
from langchain_community.document_loaders.youtube import YoutubeLoader
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
import datetime
from langchain_chroma import Chroma
from langchain_openai import OpenAIEmbeddings
from langchain_text_splitters import RecursiveCharacterTextSplitter
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnablePassthrough
from typing import Optional
from langchain_core.pydantic_v1 import BaseModel, Field
from typing import List
from langchain_core.documents import Document
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
class Search(BaseModel):
"""Search over a database of tutorial videos about a software library."""
query: str = Field(
...,
description="Similarity search query applied to video transcripts.",
)
publish_year: Optional[int] = Field(
None, description="Year video was published")
def main():
urls = [
"https://www.youtube.com/watch?v=HAn9vnJy6S4",
"https://www.youtube.com/watch?v=dA1cHGACXCo",
"https://www.youtube.com/watch?v=ZcEMLz27sL4",
"https://www.youtube.com/watch?v=hvAPnpSfSGo",
"https://www.youtube.com/watch?v=EhlPDL4QrWY",
"https://www.youtube.com/watch?v=mmBo8nlu2j0",
"https://www.youtube.com/watch?v=rQdibOsL1ps",
"https://www.youtube.com/watch?v=28lC4fqukoc",
"https://www.youtube.com/watch?v=es-9MgxB-uc",
"https://www.youtube.com/watch?v=wLRHwKuKvOE",
"https://www.youtube.com/watch?v=ObIltMaRJvY",
"https://www.youtube.com/watch?v=DjuXACWYkkU",
"https://www.youtube.com/watch?v=o7C9ld6Ln-M",
]
docs = []
for url in urls:
docs.extend(YoutubeLoader.from_youtube_url(
url, add_video_info=True).load())
# Add some additional metadata: what year the video was published
for doc in docs:
doc.metadata["publish_year"] = int(
datetime.datetime.strptime(
doc.metadata["publish_date"], "%Y-%m-%d %H:%M:%S"
).strftime("%Y")
)
text_splitter = RecursiveCharacterTextSplitter(chunk_size=2000)
chunked_docs = text_splitter.split_documents(docs)
embeddings = OpenAIEmbeddings(model="text-embedding-3-small",
api_key=api_key,
base_url=openai_url)
vectorstore = Chroma.from_documents(
chunked_docs,
embeddings,
)
# retrivael without query analysis
search_results = vectorstore.similarity_search(
"how do I build a RAG agent")
print(search_results[0].metadata["title"])
print(search_results[0].page_content[:500])
# query analysis
system = """You are an expert at converting user questions into database queries. \
You have access to a database of tutorial videos about a software library for building LLM-powered applications. \
Given a question, return a list of database queries optimized to retrieve the most relevant results.
If there are acronyms or words you are not familiar with, do not try to rephrase them."""
prompt = ChatPromptTemplate.from_messages(
[
("system", system),
("human", "{question}"),
]
)
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
structured_llm = llm.with_structured_output(Search)
query_analyzer = {
"question": RunnablePassthrough()} | prompt | structured_llm
print(query_analyzer.invoke("how do I build a RAG agent"))
def retrieval(search: Search) -> List[Document]:
if search.publish_year is not None:
# This is syntax specific to Chroma,
# the vector database we are using.
_filter = {"publish_year": {"$eq": search.publish_year}}
else:
_filter = None
return vectorstore.similarity_search(search.query, filter=_filter)
retrieval_chain = query_analyzer | retrieval
results = retrieval_chain.invoke("RAG tutorial published in 2023")
print(results)
if __name__ == "__main__":
main()
输出:
OpenGPTs
hardcoded that it will always do a retrieval step here the assistant decides whether to do a retrieval step or not sometimes this is good sometimes this is bad sometimes it you don't need to do a retrieval step when I said hi it didn't need to call it tool um but other times you know the the llm might mess up and not realize that it needs to do a retrieval step and so the rag bot will always do a retrieval step so it's more focused there because this is also a simpler architecture so it's always
/opt/anaconda3/envs/chatgpt/lib/python3.11/site-packages/langchain_core/_api/beta_decorator.py:87: LangChainBetaWarning: The function `with_structured_output` is in beta. It is actively being worked on, so the API may change.
warn_beta(
query='build RAG agent' publish_year=None
[Document(page_content="capacity and conventional rag approaches that just strip the text out really miss a lot of this so let's try kind of how could we build a rag system over the visual content in in a slide deck um so to start off what I did was I took a slide deck and this is um uh data dog's Q3 earnings report I randomly chose it you know it was just like an interesting demonstration of like kind of complex uh you know financial information and figures and slide deck and I created a set of 10 questions and answer pairs about these slides this is like my evalve set um and this is really easy to do I can just create a CSV that has like my question and my answer in this case like my input output pairs um and it's just a set of questions that I devised myself I looked at the slides I said okay here's some interesting question answer pairs I put them in a CSV and I load these into Langs Smith now Langs Smith is Lang chain platform that supports durability and evaluations um and I create a data set for myself in Lang Smith and there's some links down here that show exactly how to do that but that's my starting point so I say okay here's my evaluation set I have the slide deck I built 10 question answer pairs from the slides now let's compare some approaches there might be two different ways to think about multimodal rag um so one is this notion of multimodal embeddings so we take our slides we extract them as images in every image we use multimodal embeddings to map them into this kind of this embedding space that is common between kind of text and and images um for that I use open clip embeddings um and so I now have an index in this case I use chroma that contains a bunch of images uh that have been embedded using open clip um at retrieval time I ask a question I use I basically take the natural language question embed it indeed with multimodal embeddings same ones similarity search just like normal retrieve images that are similar to my question pass the image to in this case uh my", metadata={'author': 'LangChain', 'description': 'Unknown', 'length': 1833, 'publish_date': '2023-12-20 00:00:00', 'publish_year': 2023, 'source': '28lC4fqukoc', 'thumbnail_url': 'https://i.ytimg.com/vi/28lC4fqukoc/hq720.jpg?sqp=-oaymwEmCIAKENAF8quKqQMa8AEB-AH-CYAC0AWKAgwIABABGCkgWChyMA8=&rs=AOn4CLCPeU4y3IyyG2C3XDHmIYh8efhGbQ', 'title': 'Getting Started with Multi-Modal LLMs', 'view_count': 3766}), Document(page_content="uh context for it um instead of uh instead of asking a question so here we can just add our second route so now we're going to have um two different sets of endpoints um and I can actually just show that off in the uh fast API doc so if I refresh this we'll see now that we have all the invoke batch stream and stream log uh calls for rag conversation which was the first example that we went over or first template that we went over um and we also now have these extraction open AI functions ones um which just taken a single string instead of both like a chat history and a question and so if we go to our playground um so this is going to be our rag conversation playground um but we can go to extraction openingi functions um and we're adding a little index so it's easier to to get to these links um so in this case if we look at the readme for extraction open AI functions um what this is going to do is it's going to um extract the title and author of papers um which uh we'll look at in a sec and we'll we'll try and customize it to extract something else um but we can actually just use the same article over here um just because it also has paper ERS and authors um so if we just paste in some section of this um we can see that it's able not reminders um we can see that it's able to extract out um those authors and papers that are kind of covered in this Tas do composition section um and let's actually go into that template um to see why it's it's doing just papers um in instead um so here we can see that we have just a prompt going into a model uh which has kind of some open AI functions um set on it and then we'll talk a little bit how about how we can design those ourselves um and then in the end it's just going to Output that papers key um which is just going to be a list of papers according to our kind of pedantic model here um and then we can see that it's extracting title an author because we um Define those as as the fields to extract so let's say um I don't know", metadata={'author': 'LangChain', 'description': 'Unknown', 'length': 2441, 'publish_date': '2023-11-02 00:00:00', 'publish_year': 2023, 'source': 'o7C9ld6Ln-M', 'thumbnail_url': 'https://i.ytimg.com/vi/o7C9ld6Ln-M/hqdefault.jpg?sqp=-oaymwEXCJADEOABSFryq4qpAwkIARUAAIhCGAE=&rs=AOn4CLDf7gvV8D3I2UFy0UsA2Wh0qUhA-A', 'title': 'LangServe and LangChain Templates Webinar', 'view_count': 5000}), Document(page_content="and reason about what's going on so so that's maybe like a simple like mental model how to think about what's happening when you work with multimodal LMS um yeah let's talk a about use cases so Greg Cameron on Twitter kind of had this kind of nice visualization of a bunch of things that have been been shown with GPD 4V um a lot of people seen really cool demos with image captioning um extractions a really good one taking an image extracting elements text elements and so forth um recommendations so there's kind of like a lot of design applications um kind of suggestions about how to improve the visual Aesthetics of a scene of a of a of of like you know um of an object um and of course like interpretation this is like you know common in the rag context for example if you have like a you know collection of say we'll talk a little bit later to it a little bit later about slides um or about diagrams in documents you can of course use a vision model to reason about what's happening there in a question answer context um and this was like an intering demonstration of of extraction uh shown in the in the gbd uh 4V paper here uh actually this is a follow on to the GPD 4V model by Microsoft showing here are some interesting um explorations and they they talked about kind of extraction from complex documents um so let's actually walk through a demo to make this a little bit more concrete and I'll share kind of a bunch of code and and templates that can be easily reused later um so I think you know presentations like slide decks are a really good application for vision models because they're inherently kind of visual they have lots of kind of complex visual elements like like graphs uh tables figures and they're very common you know every nearly every organization uses slides in some capacity and conventional rag approaches that just strip the text out really miss a lot of this so let's try kind of how could we build a rag system over the visual content in in a slide deck um so", metadata={'author': 'LangChain', 'description': 'Unknown', 'length': 1833, 'publish_date': '2023-12-20 00:00:00', 'publish_year': 2023, 'source': '28lC4fqukoc', 'thumbnail_url': 'https://i.ytimg.com/vi/28lC4fqukoc/hq720.jpg?sqp=-oaymwEmCIAKENAF8quKqQMa8AEB-AH-CYAC0AWKAgwIABABGCkgWChyMA8=&rs=AOn4CLCPeU4y3IyyG2C3XDHmIYh8efhGbQ', 'title': 'Getting Started with Multi-Modal LLMs', 'view_count': 3766}), Document(page_content="this is the main thing I want to serve the thing that I copy has a bunch of extraneous things we can easily remove that um we can now do add routes app chain this is all useless stuff from before let's call This research assistant um and then we can do if we do this install SEC Starlet that's an easy fix no need to run that twice query run main install unicorn burun may now we can go here and we can add in research assistant playground and so now we get this thing what is the difference between L chain let's change it up what's the difference between L chain and open AI so this is a nice little this is all autogenerated we know that the input's question because we we know the internals of the chain that we wrote you can see the intermediate steps streams things automatically um Lang chain and open a are two prominent entities in the sphere each offering unique Frameworks and models so not exactly right we don't offer any models okay here we go open the eye provider of Link language models um Lang chain is a framework for language model applications cool so it gets those right general purpose versus chat focused um okay so it talks about the two different classes in Lang chain talks about our Integrations um developer platform um and conclusion and so we get a bunch of sources as well so that's pretty much it for this video um I'll post the code for this um in a in a simple gist or something um I'll also post uh the code for a more complex uh research assistant um oh let's maybe do one last thing let's maybe change this so instead of scraping the web it's using a different retriever of our choice and this is really interesting because uh you can now change it to do to do research over any corporate of data that you want so we'll change it we'll do some research over uh let's do some research over um over archive data all right so I've done some basic setup I've imported the archive retriever from L chain and I've got uh I've created the retriever class here what", metadata={'author': 'LangChain', 'description': 'Unknown', 'length': 2620, 'publish_date': '2023-11-16 00:00:00', 'publish_year': 2023, 'source': 'DjuXACWYkkU', 'thumbnail_url': 'https://i.ytimg.com/vi/DjuXACWYkkU/hq720.jpg', 'title': 'Building a Research Assistant from Scratch', 'view_count': 19059})]
基于SQL/CSV的问答
基于SQL语言的数据库问答,LangChain基于SQLAlchemy库提供了一系列的内置链和Agent实现此功能
架构
 任何SQL链和Agent的步骤都是如下:
任何SQL链和Agent的步骤都是如下:
- 把问题转换为SQL查询
- 执行SQL查询
- 使用查询结果回答问题
代码实现
创建Chinook db,并进行初始化
# 下载Chinook_Sqlite.sql
# curl https://raw.githubusercontent.com/lerocha/chinook-database/master/ChinookDatabase/DataSources/Chinook_Sqlite.sql -o Chinook_Sqlite.sql
# 创建Chinook.db
# sqlite3 Chinook.db
# .read Chinook_Sqlite.sql
# SELECT * FROM Artist LIMIT 10;
1|AC/DC
2|Accept
3|Aerosmith
4|Alanis Morissette
5|Alice In Chains
6|Antônio Carlos Jobim
7|Apocalyptica
8|Audioslave
9|BackBeat
10|Billy Cobham
# .exit
内置链实现SQL查询
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
from langchain_community.utilities.sql_database import SQLDatabase
from langchain.chains import create_sql_query_chain
from langchain_community.tools.sql_database.tool import QuerySQLDataBaseTool
from operator import itemgetter
from langchain_core.output_parsers import StrOutputParser
from langchain_core.prompts import PromptTemplate
from langchain_core.runnables import RunnablePassthrough
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
# 问题转化为SQL查询
chain = create_sql_query_chain(llm, db)
response = chain.invoke({"question": "How many employees are there"})
print(response)
# 执行SQL查询
execute_query = QuerySQLDataBaseTool(db=db)
write_query = create_sql_query_chain(llm, db)
chain = write_query | execute_query
print(chain.invoke({"question": "How many employees are there"}))
# 回答问题
answer_prompt = PromptTemplate.from_template(
"""Given the following user question, corresponding SQL query, and SQL result, answer the user question.
Question: {question}
SQL Query: {query}
SQL Result: {result}
Answer: """
)
answer = answer_prompt | llm | StrOutputParser()
chain = (
RunnablePassthrough.assign(query=write_query).assign(
result=itemgetter("query") | execute_query
)
| answer
)
print(chain.invoke({"question": "How many employees are there"}))
if __name__ == "__main__":
main()
输出:
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
SELECT COUNT("EmployeeId") AS "TotalEmployees" FROM "Employee"
[(8,)]
There are a total of 8 employees.
内置Agent实现SQL查询
from langchain_openai import ChatOpenAI
from pydantic.v1 import SecretStr
from langchain_community.utilities.sql_database import SQLDatabase
from langchain_community.agent_toolkits.sql.base import create_sql_agent
api_key = SecretStr("sk-xxx")
openai_url = "https://api.chatanywhere.com.cn/v1"
def main():
db = SQLDatabase.from_uri("sqlite:///Chinook.db")
print(db.dialect)
print(db.get_usable_table_names())
llm = ChatOpenAI(
temperature=0.0,
api_key=api_key,
base_url=openai_url)
agent_executor = create_sql_agent(
llm, db=db, agent_type="openai-tools", verbose=True)
agent_executor.invoke(
{
"input": "List the total sales per country. Which country's customers spent the most?"
}
)
if __name__ == "__main__":
main()
输出:
sqlite
['Album', 'Artist', 'Customer', 'Employee', 'Genre', 'Invoice', 'InvoiceLine', 'MediaType', 'Playlist', 'PlaylistTrack', 'Track']
> Entering new SQL Agent Executor chain...
Invoking: `sql_db_list_tables` with `{}`
Album, Artist, Customer, Employee, Genre, Invoice, InvoiceLine, MediaType, Playlist, PlaylistTrack, Track
Invoking: `sql_db_schema` with `{'table_names': 'Customer, Invoice, InvoiceLine'}`
CREATE TABLE "Customer" (
"CustomerId" INTEGER NOT NULL,
"FirstName" NVARCHAR(40) NOT NULL,
"LastName" NVARCHAR(20) NOT NULL,
"Company" NVARCHAR(80),
"Address" NVARCHAR(70),
"City" NVARCHAR(40),
"State" NVARCHAR(40),
"Country" NVARCHAR(40),
"PostalCode" NVARCHAR(10),
"Phone" NVARCHAR(24),
"Fax" NVARCHAR(24),
"Email" NVARCHAR(60) NOT NULL,
"SupportRepId" INTEGER,
PRIMARY KEY ("CustomerId"),
FOREIGN KEY("SupportRepId") REFERENCES "Employee" ("EmployeeId")
)
/*
3 rows from Customer table:
CustomerId FirstName LastName Company Address City State Country PostalCode Phone Fax Email SupportRepId
1 Luís Gonçalves Embraer - Empresa Brasileira de Aeronáutica S.A. Av. Brigadeiro Faria Lima, 2170 São José dos Campos SP Brazil 12227-000 +55 (12) 3923-5555 +55 (12) 3923-5566 luisg@embraer.com.br 3
2 Leonie Köhler None Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 +49 0711 2842222 None leonekohler@surfeu.de 5
3 François Tremblay None 1498 rue Bélanger Montréal QC Canada H2G 1A7 +1 (514) 721-4711 None ftremblay@gmail.com 3
*/
CREATE TABLE "Invoice" (
"InvoiceId" INTEGER NOT NULL,
"CustomerId" INTEGER NOT NULL,
"InvoiceDate" DATETIME NOT NULL,
"BillingAddress" NVARCHAR(70),
"BillingCity" NVARCHAR(40),
"BillingState" NVARCHAR(40),
"BillingCountry" NVARCHAR(40),
"BillingPostalCode" NVARCHAR(10),
"Total" NUMERIC(10, 2) NOT NULL,
PRIMARY KEY ("InvoiceId"),
FOREIGN KEY("CustomerId") REFERENCES "Customer" ("CustomerId")
)
/*
3 rows from Invoice table:
InvoiceId CustomerId InvoiceDate BillingAddress BillingCity BillingState BillingCountry BillingPostalCode Total
1 2 2021-01-01 00:00:00 Theodor-Heuss-Straße 34 Stuttgart None Germany 70174 1.98
2 4 2021-01-02 00:00:00 Ullevålsveien 14 Oslo None Norway 0171 3.96
3 8 2021-01-03 00:00:00 Grétrystraat 63 Brussels None Belgium 1000 5.94
*/
CREATE TABLE "InvoiceLine" (
"InvoiceLineId" INTEGER NOT NULL,
"InvoiceId" INTEGER NOT NULL,
"TrackId" INTEGER NOT NULL,
"UnitPrice" NUMERIC(10, 2) NOT NULL,
"Quantity" INTEGER NOT NULL,
PRIMARY KEY ("InvoiceLineId"),
FOREIGN KEY("TrackId") REFERENCES "Track" ("TrackId"),
FOREIGN KEY("InvoiceId") REFERENCES "Invoice" ("InvoiceId")
)
/*
3 rows from InvoiceLine table:
InvoiceLineId InvoiceId TrackId UnitPrice Quantity
1 1 2 0.99 1
2 1 4 0.99 1
3 2 6 0.99 1
*/
Invoking: `sql_db_query` with `{'query': 'SELECT BillingCountry AS Country, SUM(Total) AS TotalSales FROM Invoice GROUP BY BillingCountry ORDER BY TotalSales DESC;'}`
responded: To find the total sales per country, we need to sum the total amount from the invoices for each country. Here is the query to achieve this:
```sql
SELECT BillingCountry AS Country, SUM(Total) AS TotalSales
FROM Invoice
GROUP BY BillingCountry
ORDER BY TotalSales DESC;
```
By running this query, we can determine which country's customers spent the most. Let me execute the query to provide you with the answer.
[('USA', 523.0600000000003), ('Canada', 303.9599999999999), ('France', 195.09999999999994), ('Brazil', 190.09999999999997), ('Germany', 156.48), ('United Kingdom', 112.85999999999999), ('Czech Republic', 90.24000000000001), ('Portugal', 77.23999999999998), ('India', 75.25999999999999), ('Chile', 46.62), ('Ireland', 45.62), ('Hungary', 45.62), ('Austria', 42.62), ('Finland', 41.620000000000005), ('Netherlands', 40.62), ('Norway', 39.62), ('Sweden', 38.620000000000005), ('Poland', 37.620000000000005), ('Italy', 37.620000000000005), ('Denmark', 37.620000000000005), ('Australia', 37.620000000000005), ('Argentina', 37.620000000000005), ('Spain', 37.62), ('Belgium', 37.62)]The total sales per country are as follows:
1. USA: $523.06
2. Canada: $303.96
3. France: $195.10
4. Brazil: $190.10
5. Germany: $156.48
Therefore, customers from the USA spent the most in total sales.
> Finished chain.
获取外部系统的日志并分析
一个真实案例,利用langchain的代理agent来实现和外部系统交互,获取外部系统top10的日志并分析,汇总成邮件发送
from langchain_openai import ChatOpenAI
from langchain.globals import set_debug
from pydantic.v1 import SecretStr
from langchain_core.tools import tool
from langchain import hub
from langchain.agents import AgentExecutor, create_tool_calling_agent
from log import log_init, get_build_log, email_content, extract_summary
from notify import Notify
api_key = SecretStr("sk-xxx")
openai_url = "http://12.16.8.27:9997/v1"
@tool
def get_log(rank: int) -> str:
"""获取构建日志,参数rank表示速度排名,如rank=1表示获取构建速度最慢的日志"""
return get_build_log(rank)
def main(log_num: int = 10, recipient: str = ""):
set_debug(True)
log_init(log_num)
content = email_content(log_num)
llm = ChatOpenAI(
model_kwargs={
"stream_options": {"include_usage": True},
},
temperature=0,
api_key=api_key,
base_url=openai_url,
model="qwen1.5-72b-chat")
# Get the prompt to use - can be replaced with any prompt that includes variables "agent_scratchpad" and "input"!
prompt = hub.pull("hwchase17/openai-tools-agent")
tools = [get_log, ]
# Construct the tool calling agent
agent = create_tool_calling_agent(llm, tools, prompt)
# Create an agent executor by passing in the agent and tools
# stream_runnable=False,后端模型是vllm+qwen1.5-72b-int4,tool调用流式输出的话,结果会有问题,这里把流关闭了
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True,
stream_runnable=False)
fm = """
`构建分析:
耗时排名...,服务:...(任务ID:...)
各阶段耗时:...
构建慢的主要原因:...
优化建议:...
......(依次类推)
总结:......
TERMINATE`
"""
message = (f"我们以对话的方式分析构建日志。"
f"根据现有工具,你按顺序每次提供一个日志的获取方法function_call给我,"
f"我获取到日志后发送给你,不管获取成功或失败都计数,你继续把下一个的获取方法直接告诉我。"
f"限制只有{log_num}个日志,当超过日志数量限制时,按以下格式分别分析每个日志构建慢的原因:{fm}")
result = agent_executor.invoke(
{
"input": message
},
)
output = result["output"]
analysis_result = extract_summary(output)
if not analysis_result:
return False
if recipient:
content += analysis_result
Notify().send(
recipient, f"构建时长TOP{log_num}服务", f"<html>{content}</html>")
print(f"已发送邮件至{recipient}。")
return True
if __name__ == "__main__":
ok = main(10, "me")
print(f"分析{'成功' if ok else '失败'}。")
# log.py: 用于解析日志
import re
import requests
import datetime
XXX_TOKEN = "xxx-132344553243211323"
class Ops:
def __init__(self):
self.base_url = "https://xxx.com/ops/apis/v1/tenants/1234342346d5e"
self.headers = {
"Authorization": f"Bearer {XXX_TOKEN}"
}
def _get(self, url, params=None):
response = requests.get(f"{self.base_url}/{url}", headers=self.headers, params=params)
return response.json()
# 获取top10日志
def get_top_build(self, quantity=10):
url = "dashboard/top_duration_builds"
end_date = datetime.datetime.now().strftime("%Y-%m-%d")
start_date = (datetime.datetime.now() - datetime.timedelta(days=7)).strftime("%Y-%m-%d")
params = {
"start_date": start_date,
"end_date": end_date,
"quantity": quantity
}
return self._get(url, params)
# 获取任务详情
def get_build_task(self, project, service, iteration_id, tag):
url = f"projects/{project}/services/{service}/build/tasks"
query = {
"iteration_id": iteration_id,
"tag": tag
}
return self._get(url, query)
# 获取任务对应的日志
def get_build_log(self, project, service, task_id):
url = f"projects/{project}/services/{service}/build/history"
params = {
"task_id": task_id
}
return self._get(url, params)
# 获取绘制成表格的内容
def get_build_table():
table = []
for i, build in enumerate(builds):
project_manager = build.get("project_manager", "")
pm_list = project_manager.split(",")
if "op_superuser" in pm_list:
pm_list.remove("op_superuser")
if "other_user" in pm_list:
pm_list.remove("other_user")
duration = build.get("duration", 0) / 1000
if duration > 60:
duration = f"{int(duration // 60)}分{int(duration % 60)}秒"
else:
duration = f"{int(duration)}秒"
table.append({
"耗时排名": i + 1,
"耗时": duration,
"名称": build.get("pipeline_name", ""),
"项目": build.get("project_name", "") or build.get("project_id", ""),
"项目管理员": ",".join(pm_list),
"任务ID": build.get("pipeline_run_id", ""),
"日期": build.get("created_at", ""),
"状态": build.get("status", "")
})
return table
# 邮件模版
def email_content(log_num=10):
content = f"""各位领导好,以下是Ops平台本周构建时长TOP{log_num}服务:<br/><br/>"""
table_template = """
<table style='width: 1200px; border-collapse: collapse; border-spacing: 0; font-size: 12px; text-align: left;'>
<thead style="background-color: rgb(81, 130, 187); color: #fff; border-bottom-width: 0;">
<tr>{ths}</tr>
</thead>
<tbody>{tds}</tbody>
</table>"""
table_data = get_build_table()
key_list = table_data[0].keys()
ths = []
tds = []
width_map = {
"耗时排名": "100px",
"耗时": "100px",
"名称": "300px",
"项目": "150px",
"项目管理员": "200px",
"任务ID": "150px",
"日期": "200px",
"状态": "100px",
}
for k in key_list:
ths.append(f"<th style='border: 1px solid rgb(81, 130, 187); padding: 5px 10px;'>{k}</th>")
for _, row in enumerate(table_data):
tds.append("<tr style='border: 1px solid rgb(81, 130, 187);'>")
for k in key_list:
tds.append(f"<td style='padding: 5px 10px; width: {width_map.get(k, '150px')}'>{row[k]}</td>")
tds.append("</tr>")
content += table_template.format(ths="".join(ths), tds="".join(tds))
content += "<br/>"
return content
# 提取模型返回的内容
def extract_summary(result: str):
# 正则,匹配构建分析和TERMINATE之间的内容
content = ""
pattern = re.compile(r'构建分析:(.*?)TERMINATE', re.S)
match = pattern.search(result)
if match:
content = match.group(0).replace("TERMINATE", "").strip().replace("\n", "<br/>")
else:
pattern = re.compile(r'构建分析:(.*?)', re.S)
match = pattern.search(result)
if match:
content = result.strip().replace("\n", "<br/>")
return content
def log_init(quantity=10):
global z
global builds
z = Ops()
builds = z.get_top_build(quantity)["data"]
def cut_log(log):
# 1.删除Progress Timestamp(compileStamp) 和 Progress Timestamp(buildStamp) 之间,并且前缀不是>的内容
# 2.清除#编号开头中间的行,只保留相同编号的第一行和最后一行
compile_stamp = "Progress Timestamp(compileStamp)"
build_stamp = "Progress Timestamp(buildStamp)"
push_stamp = "Progress Timestamp(pushStamp)"
completed_stamp = "Progress Timestamp(completedStamp)"
lines = log.split('\n')
new_lines = []
is_compile = False
is_build = False
stage_map = {}
build_idx = 0
for idx, line in enumerate(lines):
is_build_stamp = False
if compile_stamp in line:
is_compile = True
is_build = False
line = f"开始编译:{line}"
elif build_stamp in line:
is_compile = False
is_build = True
is_build_stamp = True
line = f"开始构建Dockerfile:{line}"
elif push_stamp in line:
line = f"开始推送:{line}"
elif completed_stamp in line:
line = f"构建完成:{line}"
elif is_compile and not is_build and not line.startswith(">"):
continue
elif line.strip() == "\n" or not line.strip():
continue
else:
match = re.match(r'#(\d+) ', line)
if match:
stage = match.group(1)
if stage not in stage_map:
stage_map[stage] = [line]
elif len(stage_map[stage]) >= 1:
if len(lines) <= lines.index(line) + 1 or not lines[lines.index(line) + 1].startswith(f'#{stage} '):
stage_map[stage].append(line)
continue
new_lines.append(line)
if is_build_stamp:
build_idx = len(new_lines)
stage_list = stage_map.keys()
# 排序
stage_list = sorted(stage_list, key=lambda x: int(x))
stage_lines = []
for stage in stage_list:
for line in stage_map[stage]:
stage_lines.append(line)
new_lines[build_idx:build_idx] = stage_lines
return '\n'.join(new_lines)
def get_build_log(rank: int) -> str:
if rank > len(builds):
return f"not found build log for rank {rank}"
build = builds[rank - 1]
project = build["project_id"]
iteration_id = build["iteration_id"]
service = build["service_id"]
tag = build["pipeline_run_id"]
task = z.get_build_task(project, service, iteration_id, tag)["data"]["items"][0]
task_id = task["id"]
log = z.get_build_log(project, service, task_id)["data"]
log = f"服务:{build['pipeline_name']} (任务ID:{tag},耗时排名{rank})的日志:\n{log}"
log = cut_log(log)
# # 按行遍历,如果'#编号'开头的行,只保留相同'#编号'的第一行和最后一行
# lines = log.split('\n')
# new_lines = []
# stage_map = {}
# for line in lines:
# match = re.match(r'#(\d+) ', line)
# if match:
# stage = match.group(1)
# if line.startswith(f"{stage} ..."):
# continue
# if stage not in stage_map:
# stage_map[stage] = 1
# new_lines.append(line)
# elif stage_map[stage] >= 1:
# if len(lines) <= lines.index(line) + 1 or not lines[lines.index(line) + 1].startswith(f'#{stage} '):
# new_lines.append(line)
# stage_map[stage] = 2
# continue
# else:
# new_lines.append(line)
# log = '\n'.join(new_lines)
if rank >= len(builds):
log = f"```{log}```\n\n这是最后一条构建日志了,请帮我分析构建慢的原因"
else:
log = f"```{log}```\n\n这是第{rank}个日志内容,请继续给我第{rank+1}个日志的获取方法"
return log
if __name__ == '__main__':
log_init(1)
print(get_build_log(1))
# notify.py: 调用外部服务用于发送邮件
import requests
from log import XXX_TOKEN
class Notify:
def __init__(self):
# 外部发邮件服务域名
self.base_url = "https://xxx.com/api/v1/message"
self.headers = {
"Authorization": f"Bearer {XXX_TOKEN}"
}
def email(self, body):
url = f"{self.base_url}/smtp"
requests.post(url, headers=self.headers, json=body)
def send(self, recipient, subject, message, method="email"):
if method == "email":
self.email({
"usernames": recipient,
"subject": subject,
"type": "text/html",
"body": message
})
Token计算
import time
from langchain_openai import ChatOpenAI
from langchain_community.callbacks import get_openai_callback
IS_OLLAMA = True
# 初始化OpenAI LLM
if IS_OLLAMA:
llm = ChatOpenAI(
base_url="https://openllm.xxx.com/v1",
api_key="ollama",
model="qwen:7b",
max_tokens=2000,
temperature=0)
else:
llm = ChatOpenAI(
base_url="http://xxx:9000/v1",
api_key="ollama",
model="Qwen1.5-7B-Chat",
max_tokens=2000,
temperature=0)
# 启动回调函数
with get_openai_callback() as cb:
start_time = time.time()
# 生成一些文本
output = llm.invoke("作为一个旅游资深博主,请写一篇关于巴厘岛的文章,不少于2000字。")
end_time = time.time()
elapsed_time = end_time - start_time
# 获取生成的token数量
total_tokens = cb.total_tokens
# 计算token生成速率
token_rate = total_tokens / elapsed_time
print(f"生成了 {total_tokens} 个token, 用时 {elapsed_time:.2f} 秒")
print(f"Token生成速率为 {token_rate:.2f} tokens/秒")
输出:
生成了 286 个token, 用时 8.75 秒
Token生成速率为 32.70 tokens/秒
向量数据库
Milvus
简介
Milvus是一款云原生向量数据库,于2019年开源,具备高可用、高性能、易扩展的特点,用于海量向量数据的实时召回。它基于FAISS、ANNOY、HNSW等向量搜索库构建,核心是解决稠密向量相似度检索的问题。在向量检索库的基础上,Milvus支持数据分区分片、数据持久化、增量数据摄取、标量向量混合查询、TimeTravel等功能,同时大幅优化了向量检索的性能,可满足任何向量检索场景的应用需求。通常,建议用户使用Kubernetes部署Milvus,以获得最佳可用性和弹性。
Milvus有三种部署选项:Milvus Lite、Milvus Standalone 和 Milvus Distributed。
-
Milvus Lite Milvus Lite是一个Python库,可导入到您的应用程序中。作为Milvus的轻量级版本。运行pip install pymilvus进行安装,并使用MilvusClient("./demo.db")语句实例化一个带有本地文件的向量数据库,以持久化所有数据。
-
Milvus Standalone Milvus Standalone是单机服务器部署。Milvus Standalone的所有组件都打包到一个Docker镜像中,Milvus Standalone 通过主从复制支持高可用性
-
Milvus Distributed Milvus Distributed 可部署在Kubernetes集群上。这种部署采用云原生架构,摄取负载和搜索查询分别由独立节点处理,允许关键组件冗余。
Milvus部署:https://milvus.io/docs/install-overview.md Milvus训练营:https://github.com/milvus-io/bootcamp 向量搜索的相似性度量指标:https://zilliz.com/blog/similarity-metrics-for-vector-search
Milvus基本概念:
- 数据库:类似传统数据库的概念,一个Milvus集群最多支持64个数据库
- Collections:Collections和实体类似于关系数据库中的表和记录
- Schema:Schema用于定义Collections的属性和其中的字段
- 向量索引:Milvus提供多种索引类型和指标,可对字段值进行排序,以实现高效的相似性搜索。Milvus支持各种类型的向量数据,包括浮点嵌入(通常称为浮点向量或密集向量)、二进制嵌入(也称为二进制向量)和稀疏嵌入(也称为稀疏向量)
- 标量索引:标量索引用于通过特定的非向量字段值加速元过滤,类似于传统的数据库索引
- 混合搜索:混合搜索指的是一种同时进行多个(近似近邻)ANN 搜索、对这些ANN搜索的多组结果进行Rerankers并最终返回一组结果的搜索方法
- 全文检索:全文搜索是一种在文本数据集中检索包含特定术语或短语的文档,然后根据相关性对结果进行排序的功能。通常结合BM25算法进行相关性评分
Attu
Attu是一个用于Milvus的图形化管理工具,Attu中的功能模块包括 Overview(概览)、Collection(集合)、Vector Search(向量搜索)和 System View(系统视图)等。
docker部署方式
docker run -p 8000:3000 -e HOST_URL=http://{ your machine IP }:8000 -e MILVUS_URL={your machine IP}:19530 zilliz/attu:latest
Milvus文本检索
采用milvus+embedding模型+reranker模型检索文本的示例代码,分为两个代码片段:插入代码和查询代码
# 插入代码d.py
from openai import OpenAI
from pymilvus import MilvusClient
EMBEDDING_MODEL_NAME = "bge-large-zh-v1.5" # Which model to use, please check https://platform.openai.com/docs/guides/embeddings for available models
RERANKER_MODEL_NAME = "bge-reranker-large"
DIMENSION = 1024 # Dimension of vector embedding
BASE_URL = "http://<MODEL-IP>:9997"
API_KEY = "sk-xxx"
MILVUS_URI = "http://<MILVUS-IP>:19530"
MILVUS_DB_NAME = "default"
COLLECTION_NAME = "demo_collection"
openai_client = OpenAI(api_key=API_KEY, base_url=BASE_URL + "/v1")
milvus_client = MilvusClient(uri=MILVUS_URI, db_name=MILVUS_DB_NAME)
def create_embeddings(client, documents):
try:
return [
vec.embedding for vec in client.embeddings.create(
input=documents,
model=EMBEDDING_MODEL_NAME).data
]
except Exception as e:
print(f"Error creating embeddings: {e}")
return None
def insert_into_milvus(milvus_client, collection_name, data):
try:
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(
collection_name=collection_name,
dimension=DIMENSION,
consistency_level="Strong")
return milvus_client.insert(collection_name=collection_name, data=data)
except Exception as e:
print(f"Error inserting data into Milvus: {e}")
return None
def main():
docs = [
"查询考勤的工具,只能用于查询个人考勤记录。",
"待办管理的工具,只能用于创建或查询待办列表。",
"查询内存使用率的工具,只能用查询容器集群。",
"采购邮件格式优化的工具,只能用于优化采购内容的邮件格式。",
"申请网络代理的工具,只能用于http代理上网。",
"申请虚拟机的工具,只能用于申请虚拟机资源。",
"申请应用虚拟机的工具,只能用于申请dify虚拟机资源",
"查询cmdb的工具,只能用于查询跟cmdb相关的数据",
# "默认通用的工具,适合一切。"
]
vectors = create_embeddings(openai_client, docs)
# We can store the id, vector representation, raw text and labels such as "subject" in this case in Milvus.
data = [
{"id": i, "vector": vectors[i], "text": docs[i], "subject": "大模型工具"}
for i in range(len(docs))
]
res = insert_into_milvus(milvus_client, COLLECTION_NAME, data)
print(res)
if __name__ == "__main__":
main()
往milvus向量数据库的demo_collection集合插入了8条数据
# 查询代码e.py
from xinference.client import Client as xClient
from d import EMBEDDING_MODEL_NAME, RERANKER_MODEL_NAME, \
openai_client, milvus_client, COLLECTION_NAME, BASE_URL
def main():
queries = ["申请代理", "申请虚机"]
query_vectors = [
vec.embedding
for vec in openai_client.embeddings.create(
input=queries, model=EMBEDDING_MODEL_NAME).data
]
origin_result = milvus_client.search(
collection_name=COLLECTION_NAME, # target collection
data=query_vectors, # query vectors
limit=10, # number of returned entities
output_fields=["text", "subject"], # specifies fields to be returned
)
xclient = xClient(BASE_URL)
rerank_model = xclient.get_model(RERANKER_MODEL_NAME)
results = rerank_model.rerank(
[doc["entity"]["text"] for doc in origin_result[0]],
queries[0],
return_documents=True,
top_n=3,
)
for q in queries:
print("Query:", q)
for result in results['results']:
print(result)
print("\n")
if __name__ == "__main__":
main()
利用向量数据库相似检索出最相关的数据后,再利用rerank模型进行排序,最终返回最相关的数据
大模型运行的GPU显存计算公式
M = (P*4B) / (32/Q) * 1.2
| Symbol | Description |
|---|---|
| M | GPU memory expressed in Gigabyte |
| P | The amount of parameters in the model. E.g. a 7B model has 7 billion parameters. |
| 4B | 4 bytes, expressing the bytes used for each parameter |
| 32 | There are 32 bits in 4 bytes |
| Q | The amount of bits that should be used for loading the model. E.g. 16 bits, 8 bits or 4 bits. |
| 1.2 | Represents a 20% overhead of loading additional things in GPU memory. |
示例1:运行llama 70B 16bit的大模型需要多少显存?
M = (70B*4B) / (32/16) * 1.2 = 168GB
根据计算结果,需要至少2张A100(80GB显存)
示例2:运行llama 70B 4bit量化的大模型需要多少显存?
M = (70B*4B) / (32/4) * 1.2 = 42GB
根据计算结果,需要2张L4就可以运行(24GB显存)
参考链接
- 面向开发者的LLM入门教程
- https://github.com/xusenlinzy/api-for-open-llm/blob/master/docs/SCRIPT.md
- https://zhuanlan.zhihu.com/p/641999400
- NVidia Docker介绍
- https://python.langchain.com/docs/get_started/introduction
- llama.cpp部署实践
- 大模型在研发效率提升方面的应用与实践
- OpenCompass教程
- SGLang教程
「真诚赞赏,手留余香」
 爱折腾的工程师
爱折腾的工程师
真诚赞赏,手留余香
使用微信扫描二维码完成支付
